 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegionReasoner: Region-Grounded Multi-Round Visual Reasoning
Feb 03, 2026Large vision-language models have achieved remarkable progress in visual reasoning, yet most existing systems rely on single-step or text-only reasoning, limiting their ability to iteratively refine understanding across multiple visual contexts. To address this limitation, we introduce a new multi-round visual reasoning benchmark with training and test sets spanning both detection and segmentation tasks, enabling systematic evaluation under iterative reasoning scenarios. We further propose RegionReasoner, a reinforcement learning framework that enforces grounded reasoning by requiring each reasoning trace to explicitly cite the corresponding reference bounding boxes, while maintaining semantic coherence via a global-local consistency reward. This reward extracts key objects and nouns from both global scene captions and region-level captions, aligning them with the reasoning trace to ensure consistency across reasoning steps. RegionReasoner is optimized with structured rewards combining grounding fidelity and global-local semantic alignment. Experiments on detection and segmentation tasks show that RegionReasoner-7B, together with our newly introduced benchmark RegionDial-Bench, considerably improves multi-round reasoning accuracy, spatial grounding precision, and global-local consistency, establishing a strong baseline for this emerging research direction.
REALM: A Real-to-Sim Validated Benchmark for Generalization in Robotic Manipulation
Dec 22, 2025Vision-Language-Action (VLA) models empower robots to understand and execute tasks described by natural language instructions. However, a key challenge lies in their ability to generalize beyond the specific environments and conditions they were trained on, which is presently difficult and expensive to evaluate in the real-world. To address this gap, we present REALM, a new simulation environment and benchmark designed to evaluate the generalization capabilities of VLA models, with a specific emphasis on establishing a strong correlation between simulated and real-world performance through high-fidelity visuals and aligned robot control. Our environment offers a suite of 15 perturbation factors, 7 manipulation skills, and more than 3,500 objects. Finally, we establish two task sets that form our benchmark and evaluate the π_{0}, π_{0}-FAST, and GR00T N1.5 VLA models, showing that generalization and robustness remain an open challenge. More broadly, we also show that simulation gives us a valuable proxy for the real-world and allows us to systematically probe for and quantify the weaknesses and failure modes of VLAs. Project page: https://martin-sedlacek.com/realm
Evaluating Foundation Models' 3D Understanding Through Multi-View Correspondence Analysis
Dec 12, 2025Benchmarking 3D spatial understanding of foundation models is essential for real-world applications such as robotics and autonomous driving. Existing evaluations often rely on downstream finetuning with linear heads or task-specific decoders, making it difficult to isolate the intrinsic 3D reasoning ability of pretrained encoders. In this work, we introduce a novel benchmark for in-context 3D scene understanding that requires no finetuning and directly probes the quality of dense visual features. Building on the Hummingbird framework, which evaluates in-context 2D scene understanding, we extend the setup to the 3D Multi-View ImageNet (MVImgNet) dataset. Given a set of images from objects in specific angles (keys), we benchmark the performance of segmenting novel views (queries) and report the scores in 4 categories of easy, medium, hard, and extreme based on the key-query view contrast. We benchmark 8 state-of-the-art foundation models and show DINO-based encoders remain competitive across large viewpoint shifts, while 3D-aware models like VGGT require dedicated multi-view adjustments. Our code is publicly available at https://github.com/ToyeshC/open-hummingbird-3d-eval .
MoAlign: Motion-Centric Representation Alignment for Video Diffusion Models
Oct 21, 2025Text-to-video diffusion models have enabled high-quality video synthesis, yet often fail to generate temporally coherent and physically plausible motion. A key reason is the models' insufficient understanding of complex motions that natural videos often entail. Recent works tackle this problem by aligning diffusion model features with those from pretrained video encoders. However, these encoders mix video appearance and dynamics into entangled features, limiting the benefit of such alignment. In this paper, we propose a motion-centric alignment framework that learns a disentangled motion subspace from a pretrained video encoder. This subspace is optimized to predict ground-truth optical flow, ensuring it captures true motion dynamics. We then align the latent features of a text-to-video diffusion model to this new subspace, enabling the generative model to internalize motion knowledge and generate more plausible videos. Our method improves the physical commonsense in a state-of-the-art video diffusion model, while preserving adherence to textual prompts, as evidenced by empirical evaluations on VideoPhy, VideoPhy2, VBench, and VBench-2.0, along with a user study.
Purrception: Variational Flow Matching for Vector-Quantized Image Generation
Oct 01, 2025



We introduce Purrception, a variational flow matching approach for vector-quantized image generation that provides explicit categorical supervision while maintaining continuous transport dynamics. Our method adapts Variational Flow Matching to vector-quantized latents by learning categorical posteriors over codebook indices while computing velocity fields in the continuous embedding space. This combines the geometric awareness of continuous methods with the discrete supervision of categorical approaches, enabling uncertainty quantification over plausible codes and temperature-controlled generation. We evaluate Purrception on ImageNet-1k 256x256 generation. Training converges faster than both continuous flow matching and discrete flow matching baselines while achieving competitive FID scores with state-of-the-art models. This demonstrates that Variational Flow Matching can effectively bridge continuous transport and discrete supervision for improved training efficiency in image generation.
NeoBabel: A Multilingual Open Tower for Visual Generation
Jul 08, 2025Text-to-image generation advancements have been predominantly English-centric, creating barriers for non-English speakers and perpetuating digital inequities. While existing systems rely on translation pipelines, these introduce semantic drift, computational overhead, and cultural misalignment. We introduce NeoBabel, a novel multilingual image generation framework that sets a new Pareto frontier in performance, efficiency and inclusivity, supporting six languages: English, Chinese, Dutch, French, Hindi, and Persian. The model is trained using a combination of large-scale multilingual pretraining and high-resolution instruction tuning. To evaluate its capabilities, we expand two English-only benchmarks to multilingual equivalents: m-GenEval and m-DPG. NeoBabel achieves state-of-the-art multilingual performance while retaining strong English capability, scoring 0.75 on m-GenEval and 0.68 on m-DPG. Notably, it performs on par with leading models on English tasks while outperforming them by +0.11 and +0.09 on multilingual benchmarks, even though these models are built on multilingual base LLMs. This demonstrates the effectiveness of our targeted alignment training for preserving and extending crosslingual generalization. We further introduce two new metrics to rigorously assess multilingual alignment and robustness to code-mixed prompts. Notably, NeoBabel matches or exceeds English-only models while being 2-4x smaller. We release an open toolkit, including all code, model checkpoints, a curated dataset of 124M multilingual text-image pairs, and standardized multilingual evaluation protocols, to advance inclusive AI research. Our work demonstrates that multilingual capability is not a trade-off but a catalyst for improved robustness, efficiency, and cultural fidelity in generative AI.
Segment Any 3D-Part in a Scene from a Sentence
Jun 24, 2025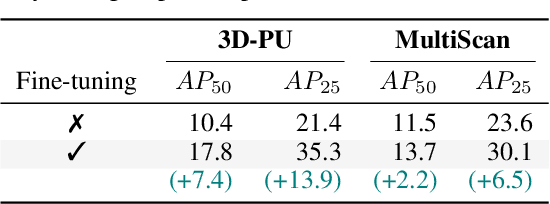
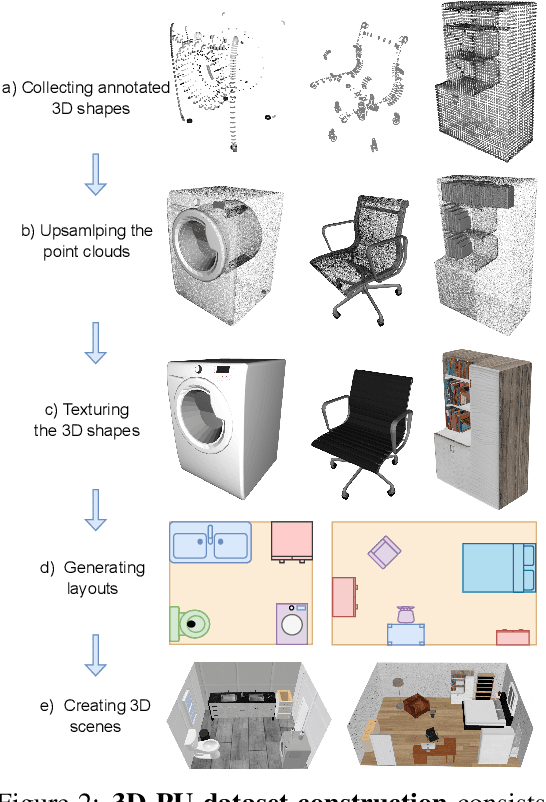


This paper aims to achieve the segmentation of any 3D part in a scene based on natural language descriptions, extending beyond traditional object-level 3D scene understanding and addressing both data and methodological challenges. Due to the expensive acquisition and annotation burden, existing datasets and methods are predominantly limited to object-level comprehension. To overcome the limitations of data and annotation availability, we introduce the 3D-PU dataset, the first large-scale 3D dataset with dense part annotations, created through an innovative and cost-effective method for constructing synthetic 3D scenes with fine-grained part-level annotations, paving the way for advanced 3D-part scene understanding. On the methodological side, we propose OpenPart3D, a 3D-input-only framework to effectively tackle the challenges of part-level segmentation. Extensive experiments demonstrate the superiority of our approach in open-vocabulary 3D scene understanding tasks at the part level, with strong generalization capabilities across various 3D scene datasets.
Continual Hyperbolic Learning of Instances and Classes
Jun 12, 2025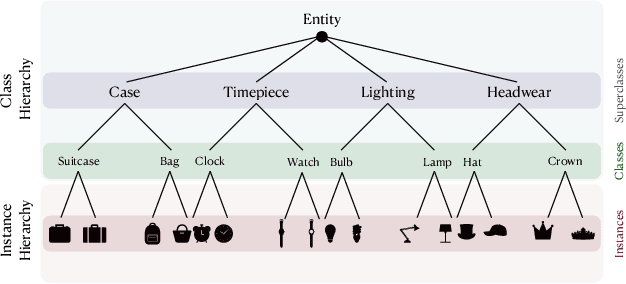
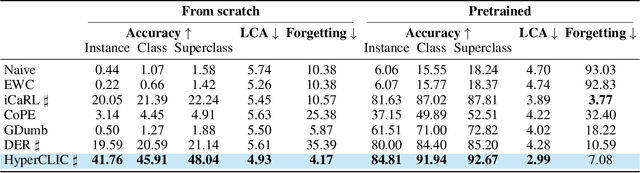
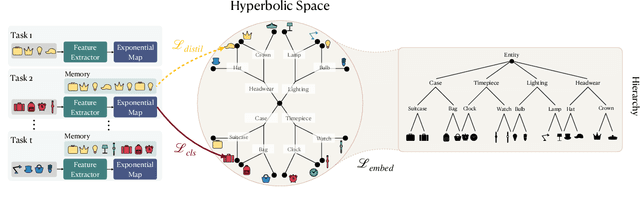
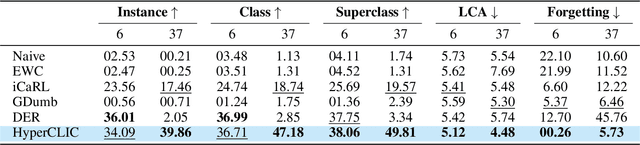
Continual learning has traditionally focused on classifying either instances or classes, but real-world applications, such as robotics and self-driving cars, require models to handle both simultaneously. To mirror real-life scenarios, we introduce the task of continual learning of instances and classes, at the same time. This task challenges models to adapt to multiple levels of granularity over time, which requires balancing fine-grained instance recognition with coarse-grained class generalization. In this paper, we identify that classes and instances naturally form a hierarchical structure. To model these hierarchical relationships, we propose HyperCLIC, a continual learning algorithm that leverages hyperbolic space, which is uniquely suited for hierarchical data due to its ability to represent tree-like structures with low distortion and compact embeddings. Our framework incorporates hyperbolic classification and distillation objectives, enabling the continual embedding of hierarchical relations. To evaluate performance across multiple granularities, we introduce continual hierarchical metrics. We validate our approach on EgoObjects, the only dataset that captures the complexity of hierarchical object recognition in dynamic real-world environments. Empirical results show that HyperCLIC operates effectively at multiple granularities with improved hierarchical generalization.
MoSiC: Optimal-Transport Motion Trajectory for Dense Self-Supervised Learning
Jun 10, 2025Dense self-supervised learning has shown great promise for learning pixel- and patch-level representations, but extending it to videos remains challenging due to the complexity of motion dynamics. Existing approaches struggle as they rely on static augmentations that fail under object deformations, occlusions, and camera movement, leading to inconsistent feature learning over time. We propose a motion-guided self-supervised learning framework that clusters dense point tracks to learn spatiotemporally consistent representations. By leveraging an off-the-shelf point tracker, we extract long-range motion trajectories and optimize feature clustering through a momentum-encoder-based optimal transport mechanism. To ensure temporal coherence, we propagate cluster assignments along tracked points, enforcing feature consistency across views despite viewpoint changes. Integrating motion as an implicit supervisory signal, our method learns representations that generalize across frames, improving robustness in dynamic scenes and challenging occlusion scenarios. By initializing from strong image-pretrained models and leveraging video data for training, we improve state-of-the-art by 1% to 6% on six image and video datasets and four evaluation benchmarks. The implementation is publicly available at our GitHub repository: https://github.com/SMSD75/MoSiC/tree/main
Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detections
Apr 15, 2025Anomaly Detection (AD) involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible, as collecting such data can be impractical. Additionally, these methods often struggle to generalize across different domains. Recent advancements, such as AnomalyCLIP and AdaCLIP, utilize the zero-shot generalization capabilities of CLIP but still face a performance gap between image-level and pixel-level anomaly detection. To address this gap, we propose a novel approach that conditions the prompts of the text encoder based on image context extracted from the vision encoder. Also, to capture fine-grained variations more effectively, we have modified the CLIP vision encoder and altered the extraction of dense features. These changes ensure that the features retain richer spatial and structural information for both normal and anomalous prompts. Our method achieves state-of-the-art performance, improving performance by 2% to 29% across different metrics on 14 datasets. This demonstrates its effectiveness in both image-level and pixel-level anomaly detection.