 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Expertise of Non-Expert and Diverse Agents in Social Bandit Learning: A Free Energy Approach
Mar 12, 2026Personalized AI-based services involve a population of individual reinforcement learning agents. However, most reinforcement learning algorithms focus on harnessing individual learning and fail to leverage the social learning capabilities commonly exhibited by humans and animals. Social learning integrates individual experience with observing others' behavior, presenting opportunities for improved learning outcomes. In this study, we focus on a social bandit learning scenario where a social agent observes other agents' actions without knowledge of their rewards. The agents independently pursue their own policy without explicit motivation to teach each other. We propose a free energy-based social bandit learning algorithm over the policy space, where the social agent evaluates others' expertise levels without resorting to any oracle or social norms. Accordingly, the social agent integrates its direct experiences in the environment and others' estimated policies. The theoretical convergence of our algorithm to the optimal policy is proven. Empirical evaluations validate the superiority of our social learning method over alternative approaches in various scenarios. Our algorithm strategically identifies the relevant agents, even in the presence of random or suboptimal agents, and skillfully exploits their behavioral information. In addition to societies including expert agents, in the presence of relevant but non-expert agents, our algorithm significantly enhances individual learning performance, where most related methods fail. Importantly, it also maintains logarithmic regret.
TIPS Over Tricks: Simple Prompts for Effective Zero-shot Anomaly Detection
Feb 03, 2026Anomaly detection identifies departures from expected behavior in safety-critical settings. When target-domain normal data are unavailable, zero-shot anomaly detection (ZSAD) leverages vision-language models (VLMs). However, CLIP's coarse image-text alignment limits both localization and detection due to (i) spatial misalignment and (ii) weak sensitivity to fine-grained anomalies; prior work compensates with complex auxiliary modules yet largely overlooks the choice of backbone. We revisit the backbone and use TIPS-a VLM trained with spatially aware objectives. While TIPS alleviates CLIP's issues, it exposes a distributional gap between global and local features. We address this with decoupled prompts-fixed for image-level detection and learnable for pixel-level localization-and by injecting local evidence into the global score. Without CLIP-specific tricks, our TIPS-based pipeline improves image-level performance by 1.1-3.9% and pixel-level by 1.5-6.9% across seven industrial datasets, delivering strong generalization with a lean architecture. Code is available at github.com/AlirezaSalehy/Tipsomaly.
Enhancing Interpretability of Sparse Latent Representations with Class Information
May 20, 2025Variational Autoencoders (VAEs) are powerful generative models for learning latent representations. Standard VAEs generate dispersed and unstructured latent spaces by utilizing all dimensions, which limits their interpretability, especially in high-dimensional spaces. To address this challenge, Variational Sparse Coding (VSC) introduces a spike-and-slab prior distribution, resulting in sparse latent representations for each input. These sparse representations, characterized by a limited number of active dimensions, are inherently more interpretable. Despite this advantage, VSC falls short in providing structured interpretations across samples within the same class. Intuitively, samples from the same class are expected to share similar attributes while allowing for variations in those attributes. This expectation should manifest as consistent patterns of active dimensions in their latent representations, but VSC does not enforce such consistency. In this paper, we propose a novel approach to enhance the latent space interpretability by ensuring that the active dimensions in the latent space are consistent across samples within the same class. To achieve this, we introduce a new loss function that encourages samples from the same class to share similar active dimensions. This alignment creates a more structured and interpretable latent space, where each shared dimension corresponds to a high-level concept, or "factor." Unlike existing disentanglement-based methods that primarily focus on global factors shared across all classes, our method captures both global and class-specific factors, thereby enhancing the utility and interpretability of latent representations.
Crane: Context-Guided Prompt Learning and Attention Refinement for Zero-Shot Anomaly Detections
Apr 15, 2025



Anomaly Detection (AD) involves identifying deviations from normal data distributions and is critical in fields such as medical diagnostics and industrial defect detection. Traditional AD methods typically require the availability of normal training samples; however, this assumption is not always feasible, as collecting such data can be impractical. Additionally, these methods often struggle to generalize across different domains. Recent advancements, such as AnomalyCLIP and AdaCLIP, utilize the zero-shot generalization capabilities of CLIP but still face a performance gap between image-level and pixel-level anomaly detection. To address this gap, we propose a novel approach that conditions the prompts of the text encoder based on image context extracted from the vision encoder. Also, to capture fine-grained variations more effectively, we have modified the CLIP vision encoder and altered the extraction of dense features. These changes ensure that the features retain richer spatial and structural information for both normal and anomalous prompts. Our method achieves state-of-the-art performance, improving performance by 2% to 29% across different metrics on 14 datasets. This demonstrates its effectiveness in both image-level and pixel-level anomaly detection.
Water Flow Detection Device Based on Sound Data Analysis and Machine Learning to Detect Water Leakage
Jan 19, 2025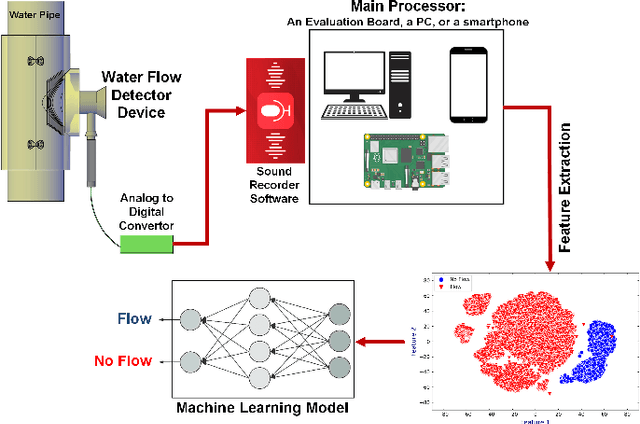

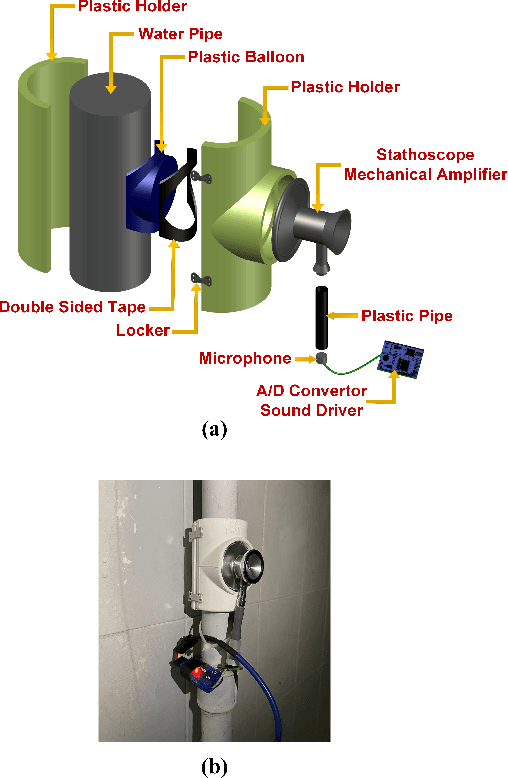
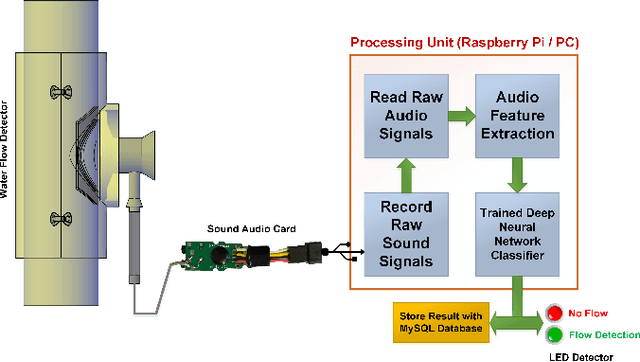
In this paper, we introduce a novel mechanism that uses machine learning techniques to detect water leaks in pipes. The proposed simple and low-cost mechanism is designed that can be easily installed on building pipes with various sizes. The system works based on gathering and amplifying water flow signals using a mechanical sound amplifier. Then sounds are recorded and converted to digital signals in order to be analyzed. After feature extraction and selection, deep neural networks are used to discriminate between with and without leak pipes. The experimental results show that this device can detect at least 100 milliliters per minute (mL/min) of water flow in a pipe so that it can be used as a core of a water leakage detection system.
Subgoal Discovery Using a Free Energy Paradigm and State Aggregations
Dec 21, 2024



Reinforcement learning (RL) plays a major role in solving complex sequential decision-making tasks. Hierarchical and goal-conditioned RL are promising methods for dealing with two major problems in RL, namely sample inefficiency and difficulties in reward shaping. These methods tackle the mentioned problems by decomposing a task into simpler subtasks and temporally abstracting a task in the action space. One of the key components for task decomposition of these methods is subgoal discovery. We can use the subgoal states to define hierarchies of actions and also use them in decomposing complex tasks. Under the assumption that subgoal states are more unpredictable, we propose a free energy paradigm to discover them. This is achieved by using free energy to select between two spaces, the main space and an aggregation space. The $model \; changes$ from neighboring states to a given state shows the unpredictability of a given state, and therefore it is used in this paper for subgoal discovery. Our empirical results on navigation tasks like grid-world environments show that our proposed method can be applied for subgoal discovery without prior knowledge of the task. Our proposed method is also robust to the stochasticity of environments.
Artificial Data Point Generation in Clustered Latent Space for Small Medical Datasets
Sep 26, 2024One of the growing trends in machine learning is the use of data generation techniques, since the performance of machine learning models is dependent on the quantity of the training dataset. However, in many medical applications, collecting large datasets is challenging due to resource constraints, which leads to overfitting and poor generalization. This paper introduces a novel method, Artificial Data Point Generation in Clustered Latent Space (AGCL), designed to enhance classification performance on small medical datasets through synthetic data generation. The AGCL framework involves feature extraction, K-means clustering, cluster evaluation based on a class separation metric, and the generation of synthetic data points from clusters with distinct class representations. This method was applied to Parkinson's disease screening, utilizing facial expression data, and evaluated across multiple machine learning classifiers. Experimental results demonstrate that AGCL significantly improves classification accuracy compared to baseline, GN and kNNMTD. AGCL achieved the highest overall test accuracy of 83.33% and cross-validation accuracy of 90.90% in majority voting over different emotions, confirming its effectiveness in augmenting small datasets.
Out-of-distribution detection using normalizing flows on the data manifold
Aug 26, 2023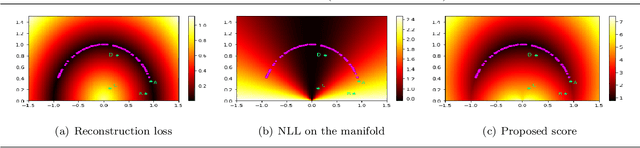

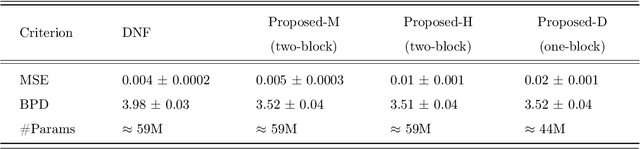

A common approach for out-of-distribution detection involves estimating an underlying data distribution, which assigns a lower likelihood value to out-of-distribution data. Normalizing flows are likelihood-based generative models providing a tractable density estimation via dimension-preserving invertible transformations. Conventional normalizing flows are prone to fail in out-of-distribution detection, because of the well-known curse of dimensionality problem of the likelihood-based models. According to the manifold hypothesis, real-world data often lie on a low-dimensional manifold. This study investigates the effect of manifold learning using normalizing flows on out-of-distribution detection. We proceed by estimating the density on a low-dimensional manifold, coupled with measuring the distance from the manifold, as criteria for out-of-distribution detection. However, individually, each of them is insufficient for this task. The extensive experimental results show that manifold learning improves the out-of-distribution detection ability of a class of likelihood-based models known as normalizing flows. This improvement is achieved without modifying the model structure or using auxiliary out-of-distribution data during training.
Combination of Single and Multi-frame Image Super-resolution: An Analytical Perspective
Mar 06, 2023Super-resolution is the process of obtaining a high-resolution image from one or more low-resolution images. Single image super-resolution (SISR) and multi-frame super-resolution (MFSR) methods have been evolved almost independently for years. A neglected study in this field is the theoretical analysis of finding the optimum combination of SISR and MFSR. To fill this gap, we propose a novel theoretical analysis based on the iterative shrinkage and thresholding algorithm. We implement and compare several approaches for combining SISR and MFSR, and simulation results support the finding of our theoretical analysis, both quantitatively and qualitatively.
Efficient Relation-aware Neighborhood Aggregation in Graph Neural Networks via Tensor Decomposition
Dec 21, 2022



Many Graph Neural Networks (GNNs) are proposed for KG embedding. However, lots of these methods neglect the importance of the information of relations and combine it with the information of entities inefficiently and mostly additively, leading to low expressiveness. To address this issue, we introduce a general knowledge graph encoder incorporating tensor decomposition in the aggregation function of Relational Graph Convolutional Network (R-GCN). In our model, the parameters of a low-rank core projection tensor, used to transform neighbor entities, are shared across relations to benefit from multi-task learning and produce expressive relation-aware representations. Besides, we propose a low-rank estimation of the core tensor using CP decomposition to compress the model, which is also applicable, as a regularization method, to other similar GNNs. We train our model using a contrastive loss, which relieves the training limitation of the 1-N method on huge graphs. We achieved favorably competitive results on FB15-237 and WN18RR with embeddings in comparably lower dimensions; particularly, we improved R-GCN performance on FB15-237 by 36% with the same decoder.