 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Online and Relational Tracking
Aug 07, 2022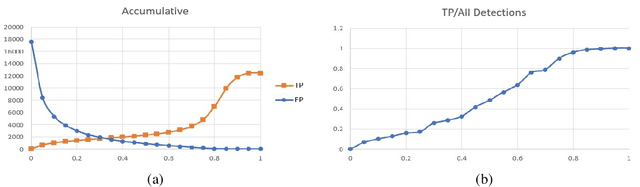
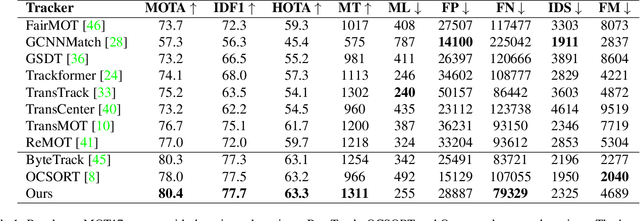
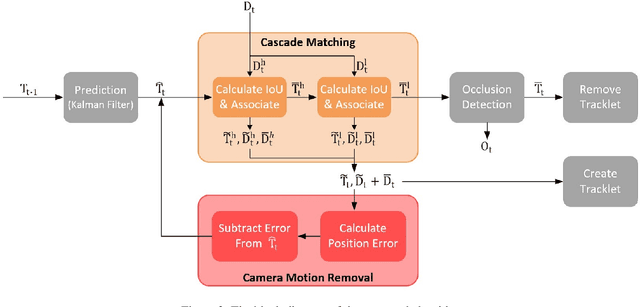
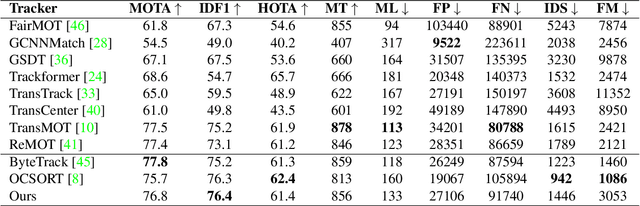
To overcome challenges in multiple object tracking task, recent algorithms use interaction cues alongside motion and appearance features. These algorithms use graph neural networks or transformers to extract interaction features that lead to high computation costs. In this paper, a novel interaction cue based on geometric features is presented aiming to detect occlusion and re-identify lost targets with low computational cost. Moreover, in most algorithms, camera motion is considered negligible, which is a strong assumption that is not always true and leads to ID Switch or mismatching of targets. In this paper, a method for measuring camera motion and removing its effect is presented that efficiently reduces the camera motion effect on tracking. The proposed algorithm is evaluated on MOT17 and MOT20 datasets and it achieves the state-of-the-art performance of MOT17 and comparable results on MOT20. The code is also publicly available.
Simple online and real-time tracking with occlusion handling
Mar 06, 2021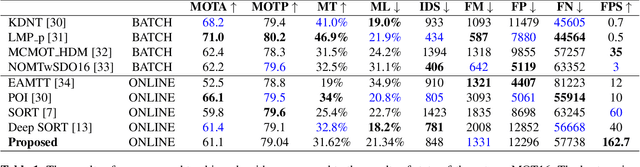

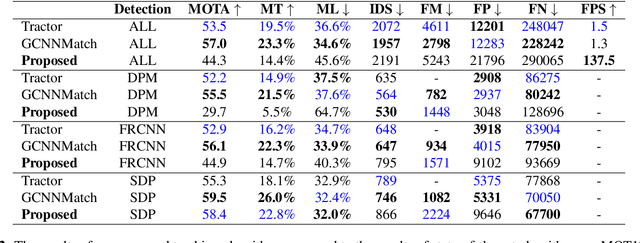

Multiple object tracking is a challenging problem in computer vision due to difficulty in dealing with motion prediction, occlusion handling, and object re-identification. Many recent algorithms use motion and appearance cues to overcome these challenges. But using appearance cues increases the computation cost notably and therefore the speed of the algorithm decreases significantly which makes them inappropriate for online applications. In contrast, there are algorithms that only use motion cues to increase speed, especially for online applications. But these algorithms cannot handle occlusions and re-identify lost objects. In this paper, a novel online multiple object tracking algorithm is presented that only uses geometric cues of objects to tackle the occlusion and reidentification challenges simultaneously. As a result, it decreases the identity switch and fragmentation metrics. Experimental results show that the proposed algorithm could decrease identity switch by 40% and fragmentation by 28% compared to the state of the art online tracking algorithms. The code is also publicly available.
On Flow Profile Image for Video Representation
May 12, 2019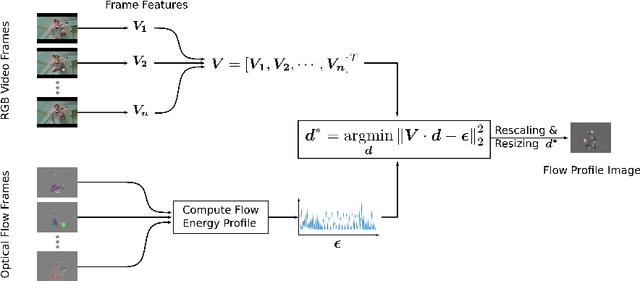
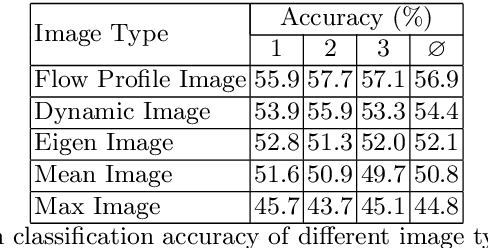

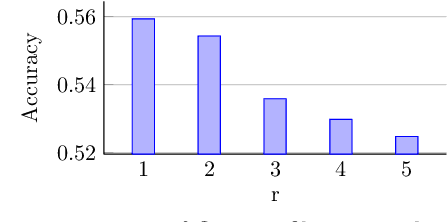
Video representation is a key challenge in many computer vision applications such as video classification, video captioning, and video surveillance. In this paper, we propose a novel approach for video representation that captures meaningful information including motion and appearance from a sequence of video frames and compacts it into a single image. To this end, we compute the optical flow and use it in a least squares optimization to find a new image, the so-called Flow Profile Image (FPI). This image encodes motions as well as foreground appearance information while background information is removed. The quality of this image is validated in activity recognition experiments and the results are compared with other video representation techniques such as dynamic images [1] and eigen images [2]. The experimental results as well as visual quality confirm that FPIs can be successfully used in video processing applications.
A Deep Convolutional Neural Network for Background Subtraction
Feb 06, 2017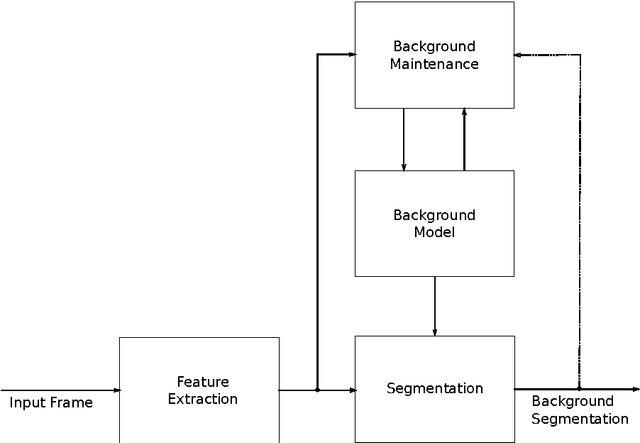

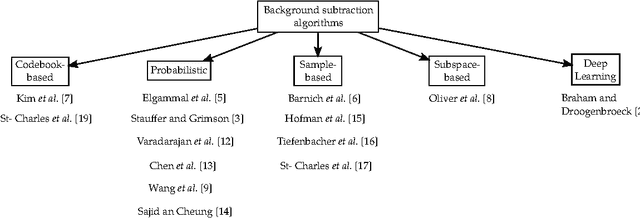
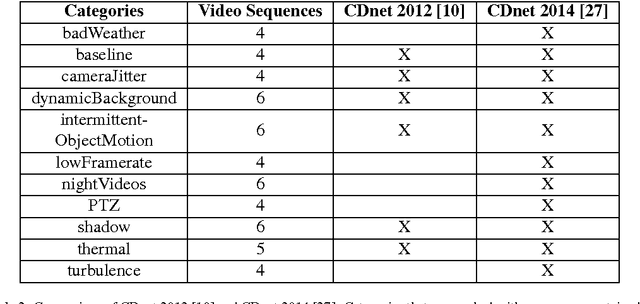
In this work, we present a novel background subtraction system that uses a deep Convolutional Neural Network (CNN) to perform the segmentation. With this approach, feature engineering and parameter tuning become unnecessary since the network parameters can be learned from data by training a single CNN that can handle various video scenes. Additionally, we propose a new approach to estimate background model from video. For the training of the CNN, we employed randomly 5 percent video frames and their ground truth segmentations taken from the Change Detection challenge 2014(CDnet 2014). We also utilized spatial-median filtering as the post-processing of the network outputs. Our method is evaluated with different data-sets, and the network outperforms the existing algorithms with respect to the average ranking over different evaluation metrics. Furthermore, due to the network architecture, our CNN is capable of real time processing.