 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Digitization of Overlapping ECG Images with Open-Source Python Code
Jun 12, 2025



This paper addresses the persistent challenge of accurately digitizing paper-based electrocardiogram (ECG) recordings, with a particular focus on robustly handling single leads compromised by signal overlaps-a common yet under-addressed issue in existing methodologies. We propose a two-stage pipeline designed to overcome this limitation. The first stage employs a U-Net based segmentation network, trained on a dataset enriched with overlapping signals and fortified with custom data augmentations, to accurately isolate the primary ECG trace. The subsequent stage converts this refined binary mask into a time-series signal using established digitization techniques, enhanced by an adaptive grid detection module for improved versatility across different ECG formats and scales. Our experimental results demonstrate the efficacy of our approach. The U-Net architecture achieves an IoU of 0.87 for the fine-grained segmentation task. Crucially, our proposed digitization method yields superior performance compared to a well-established baseline technique across both non-overlapping and challenging overlapping ECG samples. For non-overlapping signals, our method achieved a Mean Squared Error (MSE) of 0.0010 and a Pearson Correlation Coefficient (rho) of 0.9644, compared to 0.0015 and 0.9366, respectively, for the baseline. On samples with signal overlap, our method achieved an MSE of 0.0029 and a rho of 0.9641, significantly improving upon the baseline's 0.0178 and 0.8676. This work demonstrates an effective strategy to significantly enhance digitization accuracy, especially in the presence of signal overlaps, thereby laying a strong foundation for the reliable conversion of analog ECG records into analyzable digital data for contemporary research and clinical applications. The implementation is publicly available at this GitHub repository: https://github.com/masoudrahimi39/ECG-code.
Water Flow Detection Device Based on Sound Data Analysis and Machine Learning to Detect Water Leakage
Jan 19, 2025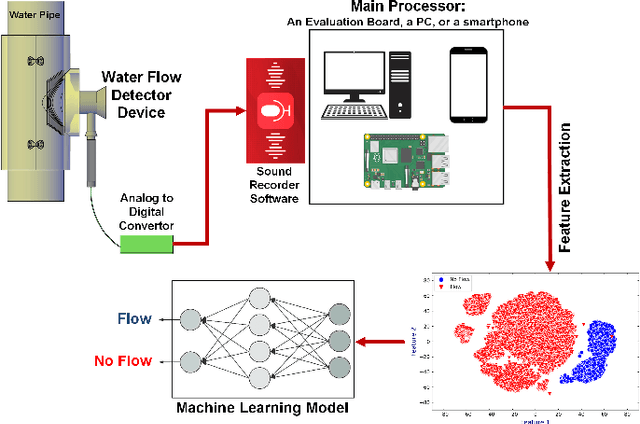

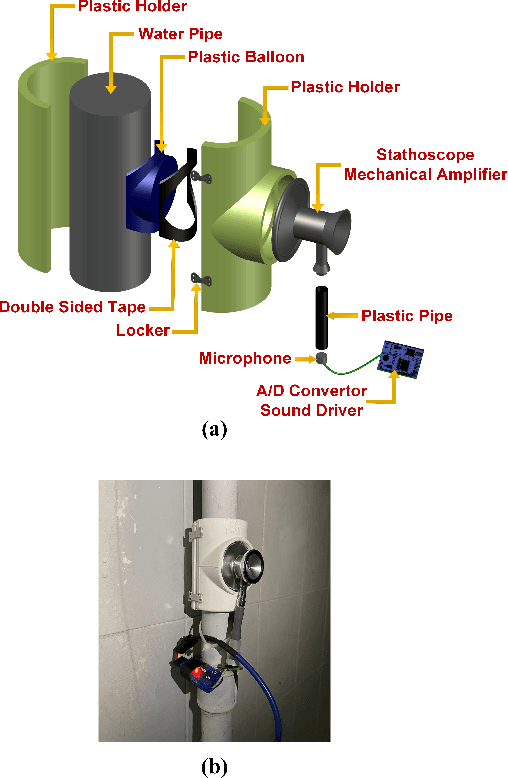
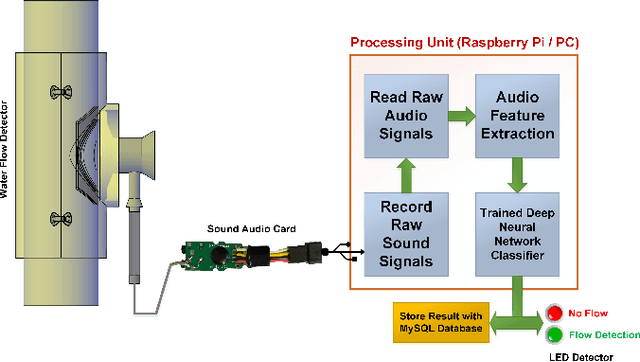
In this paper, we introduce a novel mechanism that uses machine learning techniques to detect water leaks in pipes. The proposed simple and low-cost mechanism is designed that can be easily installed on building pipes with various sizes. The system works based on gathering and amplifying water flow signals using a mechanical sound amplifier. Then sounds are recorded and converted to digital signals in order to be analyzed. After feature extraction and selection, deep neural networks are used to discriminate between with and without leak pipes. The experimental results show that this device can detect at least 100 milliliters per minute (mL/min) of water flow in a pipe so that it can be used as a core of a water leakage detection system.
Artificial Data Point Generation in Clustered Latent Space for Small Medical Datasets
Sep 26, 2024One of the growing trends in machine learning is the use of data generation techniques, since the performance of machine learning models is dependent on the quantity of the training dataset. However, in many medical applications, collecting large datasets is challenging due to resource constraints, which leads to overfitting and poor generalization. This paper introduces a novel method, Artificial Data Point Generation in Clustered Latent Space (AGCL), designed to enhance classification performance on small medical datasets through synthetic data generation. The AGCL framework involves feature extraction, K-means clustering, cluster evaluation based on a class separation metric, and the generation of synthetic data points from clusters with distinct class representations. This method was applied to Parkinson's disease screening, utilizing facial expression data, and evaluated across multiple machine learning classifiers. Experimental results demonstrate that AGCL significantly improves classification accuracy compared to baseline, GN and kNNMTD. AGCL achieved the highest overall test accuracy of 83.33% and cross-validation accuracy of 90.90% in majority voting over different emotions, confirming its effectiveness in augmenting small datasets.
The Validity of a Machine Learning-Based Video Game in the Objective Screening of Attention Deficit Hyperactivity Disorder in Children Aged 5 to 12 Years
Dec 19, 2023Objective: Early identification of ADHD is necessary to provide the opportunity for timely treatment. However, screening the symptoms of ADHD on a large scale is not easy. This study aimed to validate a video game (FishFinder) for the screening of ADHD using objective measurement of the core symptoms of this disorder. Method: The FishFinder measures attention and impulsivity through in-game performance and evaluates the child's hyperactivity using smartphone motion sensors. This game was tested on 26 children with ADHD and 26 healthy children aged 5 to 12 years. A Support Vector Machine was employed to detect children with ADHD. results: This system showed 92.3% accuracy, 90% sensitivity, and 93.7% specificity using a combination of in-game and movement features. Conclusions: The FishFinder demonstrated a strong ability to identify ADHD in children. So, this game can be used as an affordable, accessible, and enjoyable method for the objective screening of ADHD.
Modular Customizable ROS-Based Framework for Rapid Development of Social Robots
Nov 27, 2023Developing socially competent robots requires tight integration of robotics, computer vision, speech processing, and web technologies. We present the Socially-interactive Robot Software platform (SROS), an open-source framework addressing this need through a modular layered architecture. SROS bridges the Robot Operating System (ROS) layer for mobility with web and Android interface layers using standard messaging and APIs. Specialized perceptual and interactive skills are implemented as ROS services for reusable deployment on any robot. This facilitates rapid prototyping of collaborative behaviors that synchronize perception with physical actuation. We experimentally validated core SROS technologies including computer vision, speech processing, and GPT2 autocomplete speech implemented as plug-and-play ROS services. Modularity is demonstrated through the successful integration of an additional ROS package, without changes to hardware or software platforms. The capabilities enabled confirm SROS's effectiveness in developing socially interactive robots through synchronized cross-domain interaction. Through demonstrations showing synchronized multimodal behaviors on an example platform, we illustrate how the SROS architectural approach addresses shortcomings of previous work by lowering barriers for researchers to advance the state-of-the-art in adaptive, collaborative customizable human-robot systems through novel applications integrating perceptual and social abilities.
A web-based gamification of upper extremity robotic rehabilitation
Nov 21, 2023In recent years, gamification has become very popular for rehabilitating different cognitive and motor problems. It has been shown that rehabilitation is effective when it starts early enough and it is intensive and repetitive. However, the success of rehabilitation depends also on the motivation and perseverance of patients during treatment. Adding serious games to the rehabilitation procedure will help the patients to overcome the monotonicity of the treatment procedure. On the other hand, if a variety of games can be used with a robotic rehabilitation system, it will help to define tasks with different levels of difficulty with greater variety. In this paper we introduce a procedure for connecting a rehabilitation robot to several web-based games. In other words, an interface is designed that connects the robot to a computer through a USB port. To validate the usefulness of the proposed approach, a researcher designed survey was used to get feedback from several users. The results demonstrate that having several games besides rehabilitation makes the procedure of rehabilitation entertaining.
Continuous Reinforcement Learning-based Dynamic Difficulty Adjustment in a Visual Working Memory Game
Aug 24, 2023



Dynamic Difficulty Adjustment (DDA) is a viable approach to enhance a player's experience in video games. Recently, Reinforcement Learning (RL) methods have been employed for DDA in non-competitive games; nevertheless, they rely solely on discrete state-action space with a small search space. In this paper, we propose a continuous RL-based DDA methodology for a visual working memory (VWM) game to handle the complex search space for the difficulty of memorization. The proposed RL-based DDA tailors game difficulty based on the player's score and game difficulty in the last trial. We defined a continuous metric for the difficulty of memorization. Then, we consider the task difficulty and the vector of difficulty-score as the RL's action and state, respectively. We evaluated the proposed method through a within-subject experiment involving 52 subjects. The proposed approach was compared with two rule-based difficulty adjustment methods in terms of player's score and game experience measured by a questionnaire. The proposed RL-based approach resulted in a significantly better game experience in terms of competence, tension, and negative and positive affect. Players also achieved higher scores and win rates. Furthermore, the proposed RL-based DDA led to a significantly less decline in the score in a 20-trial session.
Efficient Relation-aware Neighborhood Aggregation in Graph Neural Networks via Tensor Decomposition
Dec 21, 2022



Many Graph Neural Networks (GNNs) are proposed for KG embedding. However, lots of these methods neglect the importance of the information of relations and combine it with the information of entities inefficiently and mostly additively, leading to low expressiveness. To address this issue, we introduce a general knowledge graph encoder incorporating tensor decomposition in the aggregation function of Relational Graph Convolutional Network (R-GCN). In our model, the parameters of a low-rank core projection tensor, used to transform neighbor entities, are shared across relations to benefit from multi-task learning and produce expressive relation-aware representations. Besides, we propose a low-rank estimation of the core tensor using CP decomposition to compress the model, which is also applicable, as a regularization method, to other similar GNNs. We train our model using a contrastive loss, which relieves the training limitation of the 1-N method on huge graphs. We achieved favorably competitive results on FB15-237 and WN18RR with embeddings in comparably lower dimensions; particularly, we improved R-GCN performance on FB15-237 by 36% with the same decoder.
Fast Online and Relational Tracking
Aug 07, 2022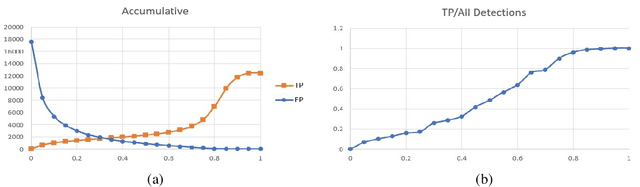
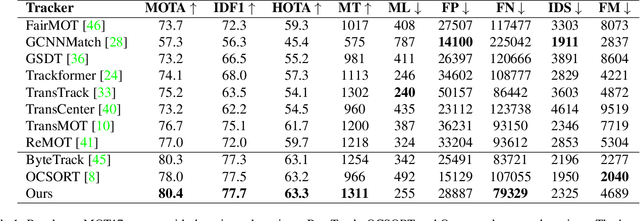
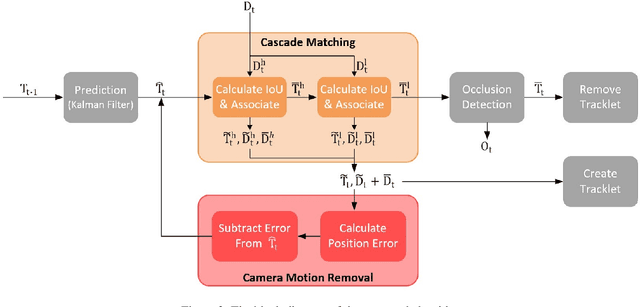
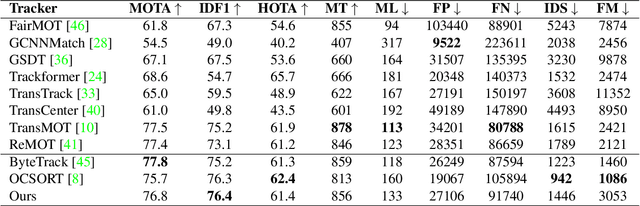
To overcome challenges in multiple object tracking task, recent algorithms use interaction cues alongside motion and appearance features. These algorithms use graph neural networks or transformers to extract interaction features that lead to high computation costs. In this paper, a novel interaction cue based on geometric features is presented aiming to detect occlusion and re-identify lost targets with low computational cost. Moreover, in most algorithms, camera motion is considered negligible, which is a strong assumption that is not always true and leads to ID Switch or mismatching of targets. In this paper, a method for measuring camera motion and removing its effect is presented that efficiently reduces the camera motion effect on tracking. The proposed algorithm is evaluated on MOT17 and MOT20 datasets and it achieves the state-of-the-art performance of MOT17 and comparable results on MOT20. The code is also publicly available.
Designing a Sequential Recommendation System for Heterogeneous Interactions Using Transformers
Apr 30, 2022
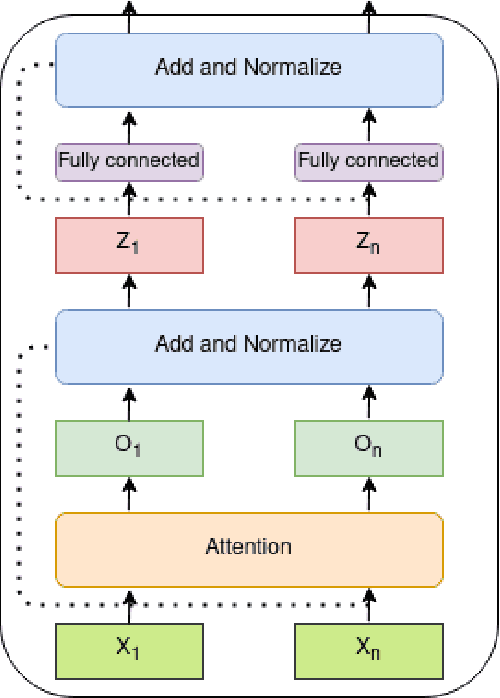


While many production-ready and robust algorithms are available for the task of recommendation systems, many of these systems do not take the order of user's consumption into account. The order of consumption can be very useful and matters in many scenarios. One such scenario is an educational content recommendation, where users generally follow a progressive path towards more advanced courses. Researchers have used RNNs to build sequential recommendation systems and other models that deal with sequences. Sequential Recommendation systems try to predict the next event for the user by reading their history. With the massive success of Transformers in Natural Language Processing and their usage of Attention Mechanism to better deal with sequences, there have been attempts to use this family of models as a base for a new generation of sequential recommendation systems. In this work, by converting each user's interactions with items into a series of events and basing our architecture on Transformers, we try to enable the use of such a model that takes different types of events into account. Furthermore, by recognizing that some events have to occur before some other types of events take place, we try to modify the architecture to reflect this dependency relationship and enhance the model's performance.