 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorful Talks with Graphs: Human-Interpretable Graph Encodings for Large Language Models
Feb 11, 2026Graph problems are fundamentally challenging for large language models (LLMs). While LLMs excel at processing unstructured text, graph tasks require reasoning over explicit structure, permutation invariance, and computationally complex relationships, creating a mismatch with the representations of text-based models. Our work investigates how LLMs can be effectively applied to graph problems despite these barriers. We introduce a human-interpretable structural encoding strategy for graph-to-text translation that injects graph structure directly into natural language prompts. Our method involves computing a variant of Weisfeiler-Lehman (WL) similarity classes and maps them to human-like color tokens rather than numeric labels. The key insight is that semantically meaningful and human-interpretable cues may be more effectively processed by LLMs than opaque symbolic encoding. Experimental results on multiple algorithmic and predictive graph tasks show the considerable improvements by our method on both synthetic and real-world datasets. By capturing both local and global-range dependencies, our method enhances LLM performance especially on graph tasks that require reasoning over global graph structure.
From Nodes to Narratives: Explaining Graph Neural Networks with LLMs and Graph Context
Aug 09, 2025Graph Neural Networks (GNNs) have emerged as powerful tools for learning over structured data, including text-attributed graphs, which are common in domains such as citation networks, social platforms, and knowledge graphs. GNNs are not inherently interpretable and thus, many explanation methods have been proposed. However, existing explanation methods often struggle to generate interpretable, fine-grained rationales, especially when node attributes include rich natural language. In this work, we introduce LOGIC, a lightweight, post-hoc framework that uses large language models (LLMs) to generate faithful and interpretable explanations for GNN predictions. LOGIC projects GNN node embeddings into the LLM embedding space and constructs hybrid prompts that interleave soft prompts with textual inputs from the graph structure. This enables the LLM to reason about GNN internal representations and produce natural language explanations along with concise explanation subgraphs. Our experiments across four real-world TAG datasets demonstrate that LOGIC achieves a favorable trade-off between fidelity and sparsity, while significantly improving human-centric metrics such as insightfulness. LOGIC sets a new direction for LLM-based explainability in graph learning by aligning GNN internals with human reasoning.
Unsupervised Prompting for Graph Neural Networks
May 22, 2025Prompt tuning methods for Graph Neural Networks (GNNs) have become popular to address the semantic gap between pre-training and fine-tuning steps. However, existing GNN prompting methods rely on labeled data and involve lightweight fine-tuning for downstream tasks. Meanwhile, in-context learning methods for Large Language Models (LLMs) have shown promising performance with no parameter updating and no or minimal labeled data. Inspired by these approaches, in this work, we first introduce a challenging problem setup to evaluate GNN prompting methods. This setup encourages a prompting function to enhance a pre-trained GNN's generalization to a target dataset under covariate shift without updating the GNN's parameters and with no labeled data. Next, we propose a fully unsupervised prompting method based on consistency regularization through pseudo-labeling. We use two regularization techniques to align the prompted graphs' distribution with the original data and reduce biased predictions. Through extensive experiments under our problem setting, we demonstrate that our unsupervised approach outperforms the state-of-the-art prompting methods that have access to labels.
Design Requirements for Human-Centered Graph Neural Network Explanations
May 11, 2024Graph neural networks (GNNs) are powerful graph-based machine-learning models that are popular in various domains, e.g., social media, transportation, and drug discovery. However, owing to complex data representations, GNNs do not easily allow for human-intelligible explanations of their predictions, which can decrease trust in them as well as deter any collaboration opportunities between the AI expert and non-technical, domain expert. Here, we first discuss the two papers that aim to provide GNN explanations to domain experts in an accessible manner and then establish a set of design requirements for human-centered GNN explanations. Finally, we offer two example prototypes to demonstrate some of those proposed requirements.
Efficient Relation-aware Neighborhood Aggregation in Graph Neural Networks via Tensor Decomposition
Dec 21, 2022



Many Graph Neural Networks (GNNs) are proposed for KG embedding. However, lots of these methods neglect the importance of the information of relations and combine it with the information of entities inefficiently and mostly additively, leading to low expressiveness. To address this issue, we introduce a general knowledge graph encoder incorporating tensor decomposition in the aggregation function of Relational Graph Convolutional Network (R-GCN). In our model, the parameters of a low-rank core projection tensor, used to transform neighbor entities, are shared across relations to benefit from multi-task learning and produce expressive relation-aware representations. Besides, we propose a low-rank estimation of the core tensor using CP decomposition to compress the model, which is also applicable, as a regularization method, to other similar GNNs. We train our model using a contrastive loss, which relieves the training limitation of the 1-N method on huge graphs. We achieved favorably competitive results on FB15-237 and WN18RR with embeddings in comparably lower dimensions; particularly, we improved R-GCN performance on FB15-237 by 36% with the same decoder.
Self-attention Presents Low-dimensional Knowledge Graph Embeddings for Link Prediction
Dec 20, 2021
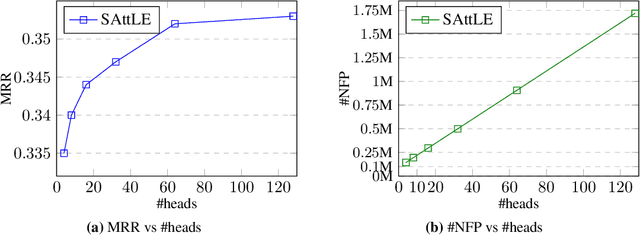
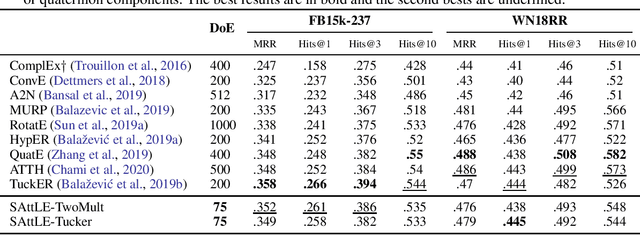

Recently, link prediction problem, also known as knowledge graph completion, has attracted lots of researches. Even though there are few recent models tried to attain relatively good performance by embedding knowledge graphs in low dimensions, the best results of the current state-of-the-art models are earned at the cost of considerably increasing the dimensionality of embeddings. However, this causes overfitting and more importantly scalability issues in case of huge knowledge bases. Inspired by the recent advances in deep learning offered by variants of the Transformer model, because of its self-attention mechanism, in this paper we propose a model based on it to address the aforementioned limitation. In our model, self-attention is the key to applying query-dependant projections to entities and relations, and capturing the mutual information between them to gain highly expressive representations from low-dimensional embeddings. Empirical results on two standard link prediction datasets, FB15k-237 and WN18RR, demonstrate that our model achieves favorably comparable or better performance than our three best recent state-of-the-art competitors, with a significant reduction of 76.3% in the dimensionality of embeddings on average.