 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-attention Presents Low-dimensional Knowledge Graph Embeddings for Link Prediction
Paper and Code

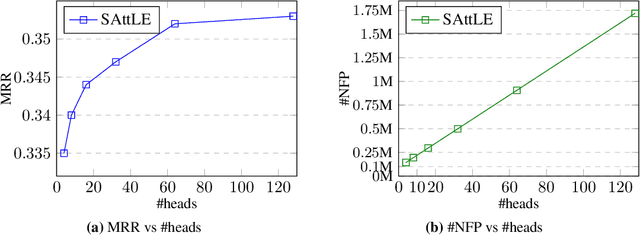
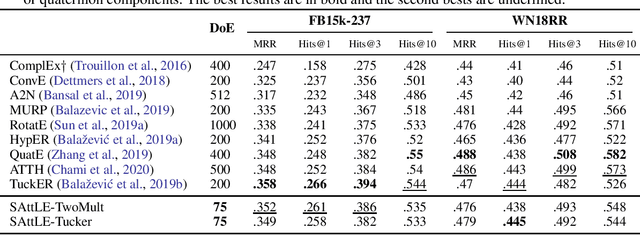

Recently, link prediction problem, also known as knowledge graph completion, has attracted lots of researches. Even though there are few recent models tried to attain relatively good performance by embedding knowledge graphs in low dimensions, the best results of the current state-of-the-art models are earned at the cost of considerably increasing the dimensionality of embeddings. However, this causes overfitting and more importantly scalability issues in case of huge knowledge bases. Inspired by the recent advances in deep learning offered by variants of the Transformer model, because of its self-attention mechanism, in this paper we propose a model based on it to address the aforementioned limitation. In our model, self-attention is the key to applying query-dependant projections to entities and relations, and capturing the mutual information between them to gain highly expressive representations from low-dimensional embeddings. Empirical results on two standard link prediction datasets, FB15k-237 and WN18RR, demonstrate that our model achieves favorably comparable or better performance than our three best recent state-of-the-art competitors, with a significant reduction of 76.3% in the dimensionality of embeddings on average.