 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColorful Talks with Graphs: Human-Interpretable Graph Encodings for Large Language Models
Feb 11, 2026Graph problems are fundamentally challenging for large language models (LLMs). While LLMs excel at processing unstructured text, graph tasks require reasoning over explicit structure, permutation invariance, and computationally complex relationships, creating a mismatch with the representations of text-based models. Our work investigates how LLMs can be effectively applied to graph problems despite these barriers. We introduce a human-interpretable structural encoding strategy for graph-to-text translation that injects graph structure directly into natural language prompts. Our method involves computing a variant of Weisfeiler-Lehman (WL) similarity classes and maps them to human-like color tokens rather than numeric labels. The key insight is that semantically meaningful and human-interpretable cues may be more effectively processed by LLMs than opaque symbolic encoding. Experimental results on multiple algorithmic and predictive graph tasks show the considerable improvements by our method on both synthetic and real-world datasets. By capturing both local and global-range dependencies, our method enhances LLM performance especially on graph tasks that require reasoning over global graph structure.
Empowering Older Adults in Digital Technology Use with Foundation Models
Jan 15, 2026While high-quality technology support can assist older adults in using digital applications, many struggle to articulate their issues due to unfamiliarity with technical terminology and age-related cognitive changes. This study examines these communication challenges and explores AI-based approaches to mitigate them. We conducted a diary study with English-speaking, community-dwelling older adults to collect asynchronous, technology-related queries and used reflexive thematic analysis to identify communication barriers. To address these barriers, we evaluated how foundation models can paraphrase older adults' queries to improve solution accuracy. Two controlled experiments followed: one with younger adults evaluating AI-rephrased queries and another with older adults evaluating AI-generated solutions. We also developed a pipeline using large language models to generate the first synthetic dataset of how older adults request tech support (OATS). We identified four key communication challenges: verbosity, incompleteness, over-specification, and under-specification. Our prompt-chaining approach using the large language model, GPT-4o, elicited contextual details, paraphrased the original query, and generated a solution. AI-rephrased queries significantly improved solution accuracy (69% vs. 46%) and Google search results (69% vs. 35%). Younger adults better understood AI-rephrased queries (93.7% vs. 65.8%) and reported greater confidence and ease. Older adults reported high perceived ability to answer contextual questions (89.8%) and follow solutions (94.7%), with high confidence and ease. OATS demonstrated strong fidelity and face validity. This work shows how foundation models can enhance technology support for older adults by addressing age-related communication barriers. The OATS dataset offers a scalable resource for developing equitable AI systems that better serve aging populations.
SMART: A Surrogate Model for Predicting Application Runtime in Dragonfly Systems
Nov 14, 2025The Dragonfly network, with its high-radix and low-diameter structure, is a leading interconnect in high-performance computing. A major challenge is workload interference on shared network links. Parallel discrete event simulation (PDES) is commonly used to analyze workload interference. However, high-fidelity PDES is computationally expensive, making it impractical for large-scale or real-time scenarios. Hybrid simulation that incorporates data-driven surrogate models offers a promising alternative, especially for forecasting application runtime, a task complicated by the dynamic behavior of network traffic. We present \ourmodel, a surrogate model that combines graph neural networks (GNNs) and large language models (LLMs) to capture both spatial and temporal patterns from port level router data. \ourmodel outperforms existing statistical and machine learning baselines, enabling accurate runtime prediction and supporting efficient hybrid simulation of Dragonfly networks.
From Nodes to Narratives: Explaining Graph Neural Networks with LLMs and Graph Context
Aug 09, 2025Graph Neural Networks (GNNs) have emerged as powerful tools for learning over structured data, including text-attributed graphs, which are common in domains such as citation networks, social platforms, and knowledge graphs. GNNs are not inherently interpretable and thus, many explanation methods have been proposed. However, existing explanation methods often struggle to generate interpretable, fine-grained rationales, especially when node attributes include rich natural language. In this work, we introduce LOGIC, a lightweight, post-hoc framework that uses large language models (LLMs) to generate faithful and interpretable explanations for GNN predictions. LOGIC projects GNN node embeddings into the LLM embedding space and constructs hybrid prompts that interleave soft prompts with textual inputs from the graph structure. This enables the LLM to reason about GNN internal representations and produce natural language explanations along with concise explanation subgraphs. Our experiments across four real-world TAG datasets demonstrate that LOGIC achieves a favorable trade-off between fidelity and sparsity, while significantly improving human-centric metrics such as insightfulness. LOGIC sets a new direction for LLM-based explainability in graph learning by aligning GNN internals with human reasoning.
PATENTWRITER: A Benchmarking Study for Patent Drafting with LLMs
Jul 30, 2025

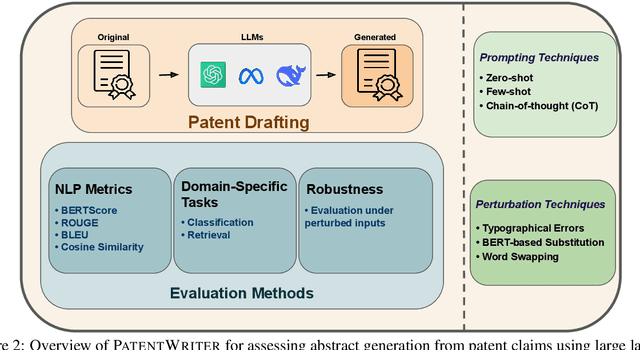
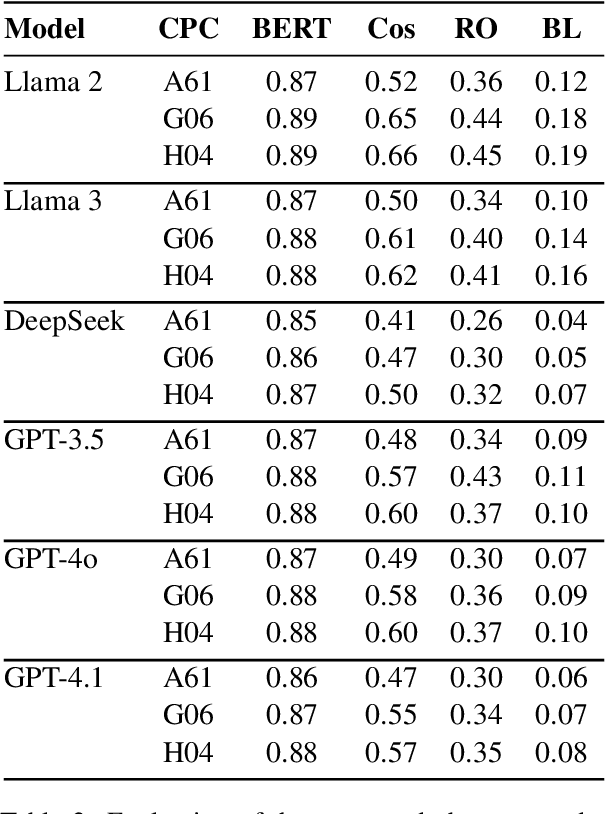
Large language models (LLMs) have emerged as transformative approaches in several important fields. This paper aims for a paradigm shift for patent writing by leveraging LLMs to overcome the tedious patent-filing process. In this work, we present PATENTWRITER, the first unified benchmarking framework for evaluating LLMs in patent abstract generation. Given the first claim of a patent, we evaluate six leading LLMs -- including GPT-4 and LLaMA-3 -- under a consistent setup spanning zero-shot, few-shot, and chain-of-thought prompting strategies to generate the abstract of the patent. Our benchmark PATENTWRITER goes beyond surface-level evaluation: we systematically assess the output quality using a comprehensive suite of metrics -- standard NLP measures (e.g., BLEU, ROUGE, BERTScore), robustness under three types of input perturbations, and applicability in two downstream patent classification and retrieval tasks. We also conduct stylistic analysis to assess length, readability, and tone. Experimental results show that modern LLMs can generate high-fidelity and stylistically appropriate patent abstracts, often surpassing domain-specific baselines. Our code and dataset are open-sourced to support reproducibility and future research.
Unsupervised Prompting for Graph Neural Networks
May 22, 2025Prompt tuning methods for Graph Neural Networks (GNNs) have become popular to address the semantic gap between pre-training and fine-tuning steps. However, existing GNN prompting methods rely on labeled data and involve lightweight fine-tuning for downstream tasks. Meanwhile, in-context learning methods for Large Language Models (LLMs) have shown promising performance with no parameter updating and no or minimal labeled data. Inspired by these approaches, in this work, we first introduce a challenging problem setup to evaluate GNN prompting methods. This setup encourages a prompting function to enhance a pre-trained GNN's generalization to a target dataset under covariate shift without updating the GNN's parameters and with no labeled data. Next, we propose a fully unsupervised prompting method based on consistency regularization through pseudo-labeling. We use two regularization techniques to align the prompted graphs' distribution with the original data and reduce biased predictions. Through extensive experiments under our problem setting, we demonstrate that our unsupervised approach outperforms the state-of-the-art prompting methods that have access to labels.
COMRECGC: Global Graph Counterfactual Explainer through Common Recourse
May 13, 2025Graph neural networks (GNNs) have been widely used in various domains such as social networks, molecular biology, or recommendation systems. Concurrently, different explanations methods of GNNs have arisen to complement its black-box nature. Explanations of the GNNs' predictions can be categorized into two types--factual and counterfactual. Given a GNN trained on binary classification into ''accept'' and ''reject'' classes, a global counterfactual explanation consists in generating a small set of ''accept'' graphs relevant to all of the input ''reject'' graphs. The transformation of a ''reject'' graph into an ''accept'' graph is called a recourse. A common recourse explanation is a small set of recourse, from which every ''reject'' graph can be turned into an ''accept'' graph. Although local counterfactual explanations have been studied extensively, the problem of finding common recourse for global counterfactual explanation remains unexplored, particularly for GNNs. In this paper, we formalize the common recourse explanation problem, and design an effective algorithm, COMRECGC, to solve it. We benchmark our algorithm against strong baselines on four different real-world graphs datasets and demonstrate the superior performance of COMRECGC against the competitors. We also compare the common recourse explanations to the graph counterfactual explanation, showing that common recourse explanations are either comparable or superior, making them worth considering for applications such as drug discovery or computational biology.
Learning Exposure Mapping Functions for Inferring Heterogeneous Peer Effects
Mar 03, 2025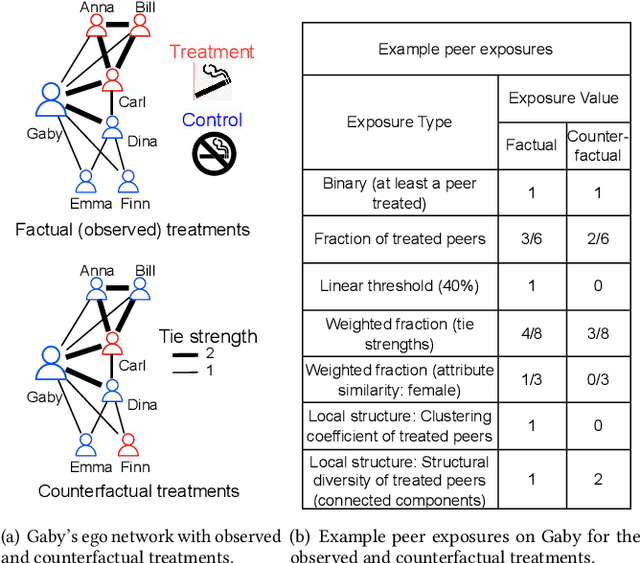
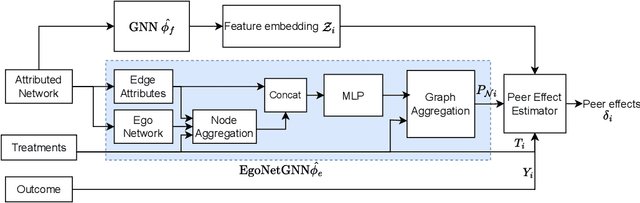
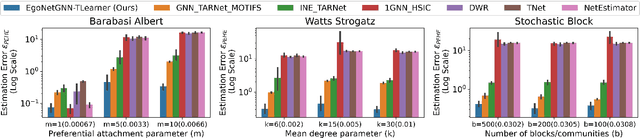
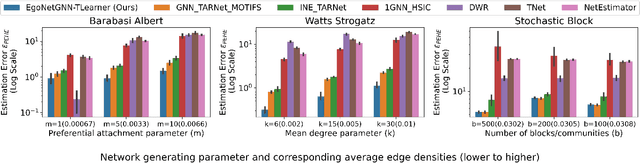
In causal inference, interference refers to the phenomenon in which the actions of peers in a network can influence an individual's outcome. Peer effect refers to the difference in counterfactual outcomes of an individual for different levels of peer exposure, the extent to which an individual is exposed to the treatments, actions, or behaviors of peers. Estimating peer effects requires deciding how to represent peer exposure. Typically, researchers define an exposure mapping function that aggregates peer treatments and outputs peer exposure. Most existing approaches for defining exposure mapping functions assume peer exposure based on the number or fraction of treated peers. Recent studies have investigated more complex functions of peer exposure which capture that different peers can exert different degrees of influence. However, none of these works have explicitly considered the problem of automatically learning the exposure mapping function. In this work, we focus on learning this function for the purpose of estimating heterogeneous peer effects, where heterogeneity refers to the variation in counterfactual outcomes for the same peer exposure but different individual's contexts. We develop EgoNetGNN, a graph neural network (GNN)-based method, to automatically learn the appropriate exposure mapping function allowing for complex peer influence mechanisms that, in addition to peer treatments, can involve the local neighborhood structure and edge attributes. We show that GNN models that use peer exposure based on the number or fraction of treated peers or learn peer exposure naively face difficulty accounting for such influence mechanisms. Our comprehensive evaluation on synthetic and semi-synthetic network data shows that our method is more robust to different unknown underlying influence mechanisms when estimating heterogeneous peer effects when compared to state-of-the-art baselines.
LLMInit: A Free Lunch from Large Language Models for Selective Initialization of Recommendation
Mar 03, 2025Collaborative filtering models, particularly graph-based approaches, have demonstrated strong performance in capturing user-item interactions for recommendation systems. However, they continue to struggle in cold-start and data-sparse scenarios. The emergence of large language models (LLMs) like GPT and LLaMA presents new possibilities for enhancing recommendation performance, especially in cold-start settings. Despite their promise, LLMs pose challenges related to scalability and efficiency due to their high computational demands and limited ability to model complex user-item relationships effectively. In this work, we introduce a novel perspective on leveraging LLMs for CF model initialization. Through experiments, we uncover an embedding collapse issue when scaling CF models to larger embedding dimensions. To effectively harness large-scale LLM embeddings, we propose innovative selective initialization strategies utilizing random, uniform, and variance-based index sampling. Our comprehensive evaluation on multiple real-world datasets demonstrates significant performance gains across various CF models while maintaining a lower computational cost compared to existing LLM-based recommendation approaches.
BANGS: Game-Theoretic Node Selection for Graph Self-Training
Oct 12, 2024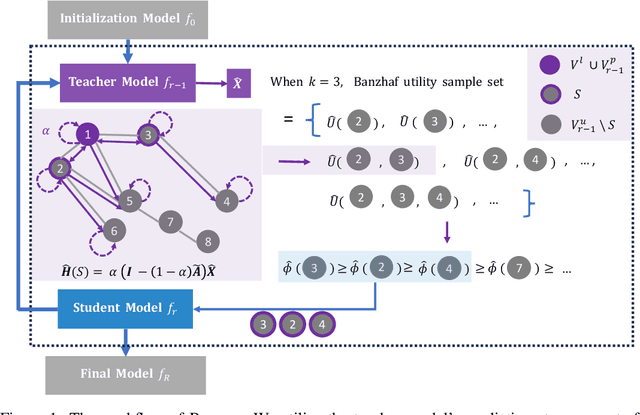
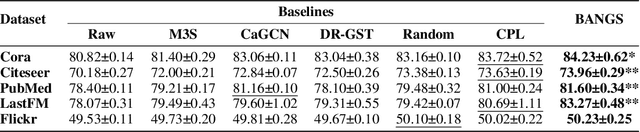

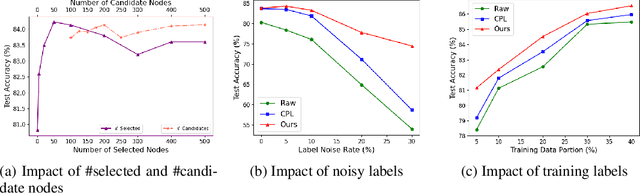
Graph self-training is a semi-supervised learning method that iteratively selects a set of unlabeled data to retrain the underlying graph neural network (GNN) model and improve its prediction performance. While selecting highly confident nodes has proven effective for self-training, this pseudo-labeling strategy ignores the combinatorial dependencies between nodes and suffers from a local view of the distribution. To overcome these issues, we propose BANGS, a novel framework that unifies the labeling strategy with conditional mutual information as the objective of node selection. Our approach -- grounded in game theory -- selects nodes in a combinatorial fashion and provides theoretical guarantees for robustness under noisy objective. More specifically, unlike traditional methods that rank and select nodes independently, BANGS considers nodes as a collective set in the self-training process. Our method demonstrates superior performance and robustness across various datasets, base models, and hyperparameter settings, outperforming existing techniques. The codebase is available on https://github.com/fangxin-wang/BANGS .