 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGame-theoretic Counterfactual Explanation for Graph Neural Networks
Feb 08, 2024
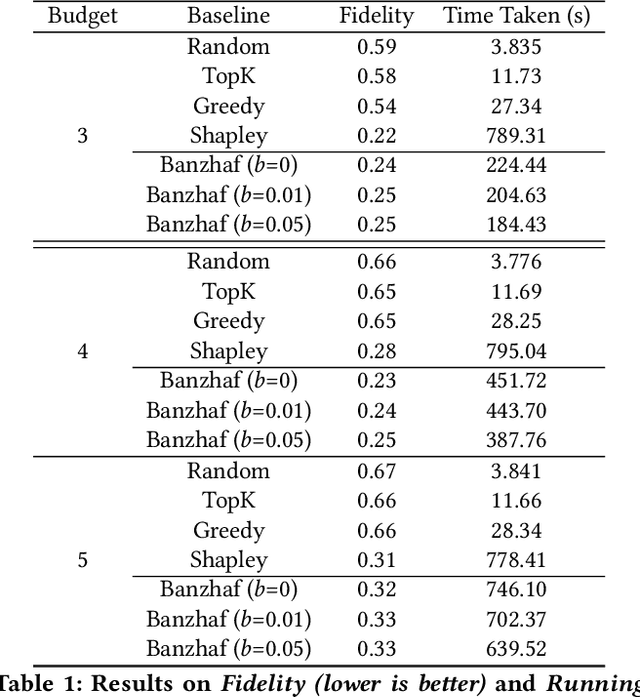


Graph Neural Networks (GNNs) have been a powerful tool for node classification tasks in complex networks. However, their decision-making processes remain a black-box to users, making it challenging to understand the reasoning behind their predictions. Counterfactual explanations (CFE) have shown promise in enhancing the interpretability of machine learning models. Prior approaches to compute CFE for GNNS often are learning-based approaches that require training additional graphs. In this paper, we propose a semivalue-based, non-learning approach to generate CFE for node classification tasks, eliminating the need for any additional training. Our results reveals that computing Banzhaf values requires lower sample complexity in identifying the counterfactual explanations compared to other popular methods such as computing Shapley values. Our empirical evidence indicates computing Banzhaf values can achieve up to a fourfold speed up compared to Shapley values. We also design a thresholding method for computing Banzhaf values and show theoretical and empirical results on its robustness in noisy environments, making it superior to Shapley values. Furthermore, the thresholded Banzhaf values are shown to enhance efficiency without compromising the quality (i.e., fidelity) in the explanations in three popular graph datasets.
Digits micro-model for accurate and secure transactions
Feb 02, 2024Automatic Speech Recognition (ASR) systems are used in the financial domain to enhance the caller experience by enabling natural language understanding and facilitating efficient and intuitive interactions. Increasing use of ASR systems requires that such systems exhibit very low error rates. The predominant ASR models to collect numeric data are large, general-purpose commercial models -- Google Speech-to-text (STT), or Amazon Transcribe -- or open source (OpenAI's Whisper). Such ASR models are trained on hundreds of thousands of hours of audio data and require considerable resources to run. Despite recent progress large speech recognition models, we highlight the potential of smaller, specialized "micro" models. Such light models can be trained perform well on number recognition specific tasks, competing with general models like Whisper or Google STT while using less than 80 minutes of training time and occupying at least an order of less memory resources. Also, unlike larger speech recognition models, micro-models are trained on carefully selected and curated datasets, which makes them highly accurate, agile, and easy to retrain, while using low compute resources. We present our work on creating micro models for multi-digit number recognition that handle diverse speaking styles reflecting real-world pronunciation patterns. Our work contributes to domain-specific ASR models, improving digit recognition accuracy, and privacy of data. An added advantage, their low resource consumption allows them to be hosted on-premise, keeping private data local instead uploading to an external cloud. Our results indicate that our micro-model makes less errors than the best-of-breed commercial or open-source ASRs in recognizing digits (1.8% error rate of our best micro-model versus 5.8% error rate of Whisper), and has a low memory footprint (0.66 GB VRAM for our model versus 11 GB VRAM for Whisper).