 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Unlearning Using Perturbed Sign Gradient Methods With Applications On Medical Images
May 28, 2025Machine unlearning aims to remove the influence of specific training samples from a trained model without full retraining. While prior work has largely focused on privacy-motivated settings, we recast unlearning as a general-purpose tool for post-deployment model revision. Specifically, we focus on utilizing unlearning in clinical contexts where data shifts, device deprecation, and policy changes are common. To this end, we propose a bilevel optimization formulation of boundary-based unlearning that can be solved using iterative algorithms. We provide convergence guarantees when first-order algorithms are used to unlearn. Our method introduces tunable loss design for controlling the forgetting-retention tradeoff and supports novel model composition strategies that merge the strengths of distinct unlearning runs. Across benchmark and real-world clinical imaging datasets, our approach outperforms baselines on both forgetting and retention metrics, including scenarios involving imaging devices and anatomical outliers. This work establishes machine unlearning as a modular, practical alternative to retraining for real-world model maintenance in clinical applications.
A Comprehensive Survey on AI-based Methods for Patents
Apr 02, 2024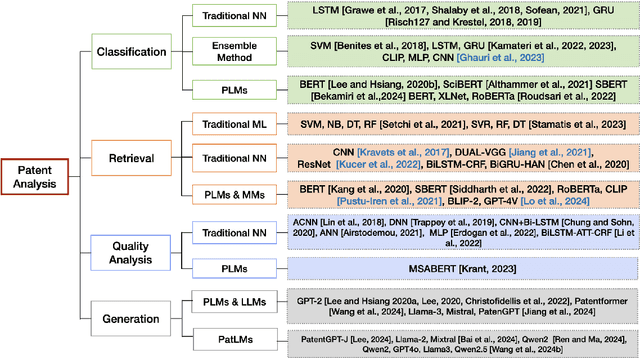


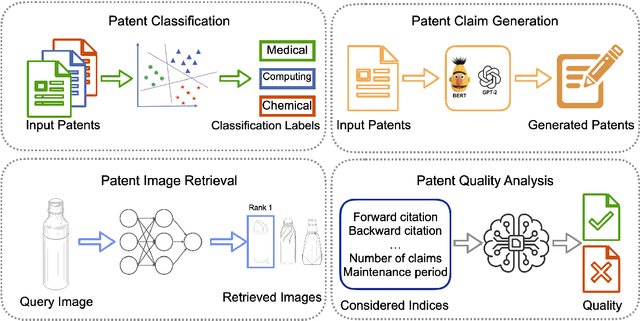
Recent advancements in Artificial Intelligence (AI) and machine learning have demonstrated transformative capabilities across diverse domains. This progress extends to the field of patent analysis and innovation, where AI-based tools present opportunities to streamline and enhance important tasks in the patent cycle such as classification, retrieval, and valuation prediction. This not only accelerates the efficiency of patent researchers and applicants but also opens new avenues for technological innovation and discovery. Our survey provides a comprehensive summary of recent AI tools in patent analysis from more than 40 papers from 26 venues between 2017 and 2023. Unlike existing surveys, we include methods that work for patent image and text data. Furthermore, we introduce a novel taxonomy for the categorization based on the tasks in the patent life cycle as well as the specifics of the AI methods. This survey aims to serve as a resource for researchers, practitioners, and patent offices in the domain of AI-powered patent analysis.
Accelerated Neural Network Training with Rooted Logistic Objectives
Oct 05, 2023Many neural networks deployed in the real world scenarios are trained using cross entropy based loss functions. From the optimization perspective, it is known that the behavior of first order methods such as gradient descent crucially depend on the separability of datasets. In fact, even in the most simplest case of binary classification, the rate of convergence depends on two factors: (1) condition number of data matrix, and (2) separability of the dataset. With no further pre-processing techniques such as over-parametrization, data augmentation etc., separability is an intrinsic quantity of the data distribution under consideration. We focus on the landscape design of the logistic function and derive a novel sequence of {\em strictly} convex functions that are at least as strict as logistic loss. The minimizers of these functions coincide with those of the minimum norm solution wherever possible. The strict convexity of the derived function can be extended to finetune state-of-the-art models and applications. In empirical experimental analysis, we apply our proposed rooted logistic objective to multiple deep models, e.g., fully-connected neural networks and transformers, on various of classification benchmarks. Our results illustrate that training with rooted loss function is converged faster and gains performance improvements. Furthermore, we illustrate applications of our novel rooted loss function in generative modeling based downstream applications, such as finetuning StyleGAN model with the rooted loss. The code implementing our losses and models can be found here for open source software development purposes: https://anonymous.4open.science/r/rooted_loss.
Flag Aggregator: Scalable Distributed Training under Failures and Augmented Losses using Convex Optimization
Feb 12, 2023



Modern ML applications increasingly rely on complex deep learning models and large datasets. There has been an exponential growth in the amount of computation needed to train the largest models. Therefore, to scale computation and data, these models are inevitably trained in a distributed manner in clusters of nodes, and their updates are aggregated before being applied to the model. However, a distributed setup is prone to byzantine failures of individual nodes, components, and software. With data augmentation added to these settings, there is a critical need for robust and efficient aggregation systems. We extend the current state-of-the-art aggregators and propose an optimization-based subspace estimator by modeling pairwise distances as quadratic functions by utilizing the recently introduced Flag Median problem. The estimator in our loss function favors the pairs that preserve the norm of the difference vector. We theoretically show that our approach enhances the robustness of state-of-the-art byzantine resilient aggregators. Also, we evaluate our method with different tasks in a distributed setup with a parameter server architecture and show its communication efficiency while maintaining similar accuracy. The code is publicly available at https://github.com/hamidralmasi/FlagAggregator
Differentiable Outlier Detection Enable Robust Deep Multimodal Analysis
Feb 11, 2023Often, deep network models are purely inductive during training and while performing inference on unseen data. Thus, when such models are used for predictions, it is well known that they often fail to capture the semantic information and implicit dependencies that exist among objects (or concepts) on a population level. Moreover, it is still unclear how domain or prior modal knowledge can be specified in a backpropagation friendly manner, especially in large-scale and noisy settings. In this work, we propose an end-to-end vision and language model incorporating explicit knowledge graphs. We also introduce an interactive out-of-distribution (OOD) layer using implicit network operator. The layer is used to filter noise that is brought by external knowledge base. In practice, we apply our model on several vision and language downstream tasks including visual question answering, visual reasoning, and image-text retrieval on different datasets. Our experiments show that it is possible to design models that perform similarly to state-of-art results but with significantly fewer samples and training time.
Using Intermediate Forward Iterates for Intermediate Generator Optimization
Feb 05, 2023



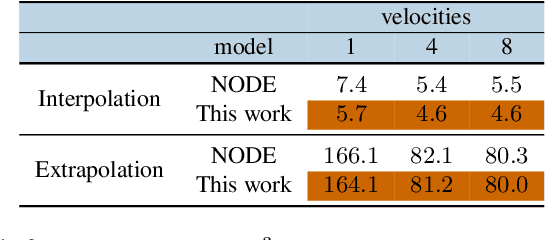
Score-based models have recently been introduced as a richer framework to model distributions in high dimensions and are generally more suitable for generative tasks. In score-based models, a generative task is formulated using a parametric model (such as a neural network) to directly learn the gradient of such high dimensional distributions, instead of the density functions themselves, as is done traditionally. From the mathematical point of view, such gradient information can be utilized in reverse by stochastic sampling to generate diverse samples. However, from a computational perspective, existing score-based models can be efficiently trained only if the forward or the corruption process can be computed in closed form. By using the relationship between the process and layers in a feed-forward network, we derive a backpropagation-based procedure which we call Intermediate Generator Optimization to utilize intermediate iterates of the process with negligible computational overhead. The main advantage of IGO is that it can be incorporated into any standard autoencoder pipeline for the generative task. We analyze the sample complexity properties of IGO to solve downstream tasks like Generative PCA. We show applications of the IGO on two dense predictive tasks viz., image extrapolation, and point cloud denoising. Our experiments indicate that obtaining an ensemble of generators for various time points is possible using first-order methods.
Deep Unlearning via Randomized Conditionally Independent Hessians
Apr 15, 2022
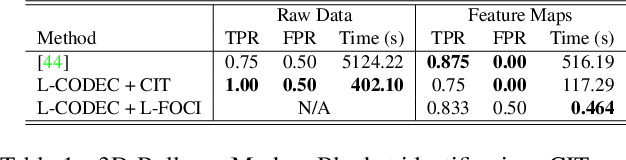


Recent legislation has led to interest in machine unlearning, i.e., removing specific training samples from a predictive model as if they never existed in the training dataset. Unlearning may also be required due to corrupted/adversarial data or simply a user's updated privacy requirement. For models which require no training (k-NN), simply deleting the closest original sample can be effective. But this idea is inapplicable to models which learn richer representations. Recent ideas leveraging optimization-based updates scale poorly with the model dimension d, due to inverting the Hessian of the loss function. We use a variant of a new conditional independence coefficient, L-CODEC, to identify a subset of the model parameters with the most semantic overlap on an individual sample level. Our approach completely avoids the need to invert a (possibly) huge matrix. By utilizing a Markov blanket selection, we premise that L-CODEC is also suitable for deep unlearning, as well as other applications in vision. Compared to alternatives, L-CODEC makes approximate unlearning possible in settings that would otherwise be infeasible, including vision models used for face recognition, person re-identification and NLP models that may require unlearning samples identified for exclusion. Code can be found at https://github.com/vsingh-group/LCODEC-deep-unlearning/
Equivariance Allows Handling Multiple Nuisance Variables When Analyzing Pooled Neuroimaging Datasets
Mar 29, 2022



Pooling multiple neuroimaging datasets across institutions often enables improvements in statistical power when evaluating associations (e.g., between risk factors and disease outcomes) that may otherwise be too weak to detect. When there is only a {\em single} source of variability (e.g., different scanners), domain adaptation and matching the distributions of representations may suffice in many scenarios. But in the presence of {\em more than one} nuisance variable which concurrently influence the measurements, pooling datasets poses unique challenges, e.g., variations in the data can come from both the acquisition method as well as the demographics of participants (gender, age). Invariant representation learning, by itself, is ill-suited to fully model the data generation process. In this paper, we show how bringing recent results on equivariant representation learning (for studying symmetries in neural networks) instantiated on structured spaces together with simple use of classical results on causal inference provides an effective practical solution. In particular, we demonstrate how our model allows dealing with more than one nuisance variable under some assumptions and can enable analysis of pooled scientific datasets in scenarios that would otherwise entail removing a large portion of the samples.
Mixed Effects Neural ODE: A Variational Approximation for Analyzing the Dynamics of Panel Data
Feb 18, 2022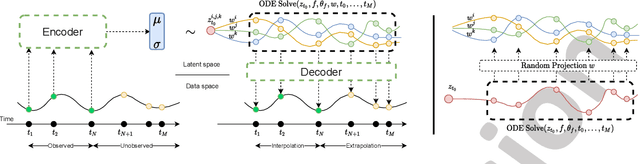
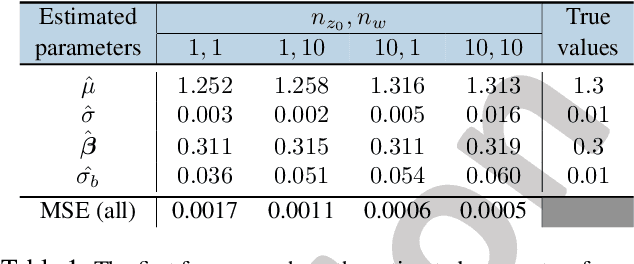
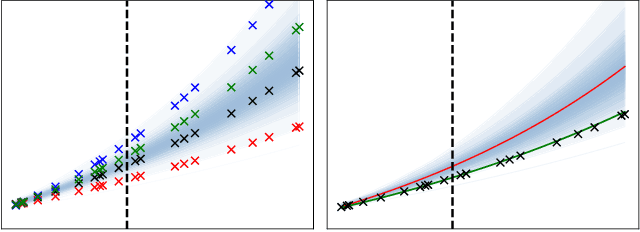
Panel data involving longitudinal measurements of the same set of participants taken over multiple time points is common in studies to understand childhood development and disease modeling. Deep hybrid models that marry the predictive power of neural networks with physical simulators such as differential equations, are starting to drive advances in such applications. The task of modeling not just the observations but the hidden dynamics that are captured by the measurements poses interesting statistical/computational questions. We propose a probabilistic model called ME-NODE to incorporate (fixed + random) mixed effects for analyzing such panel data. We show that our model can be derived using smooth approximations of SDEs provided by the Wong-Zakai theorem. We then derive Evidence Based Lower Bounds for ME-NODE, and develop (efficient) training algorithms using MC based sampling methods and numerical ODE solvers. We demonstrate ME-NODE's utility on tasks spanning the spectrum from simulations and toy data to real longitudinal 3D imaging data from an Alzheimer's disease (AD) study, and study its performance in terms of accuracy of reconstruction for interpolation, uncertainty estimates and personalized prediction.
You Only Sample Once: Linear Cost Self-Attention Via Bernoulli Sampling
Nov 18, 2021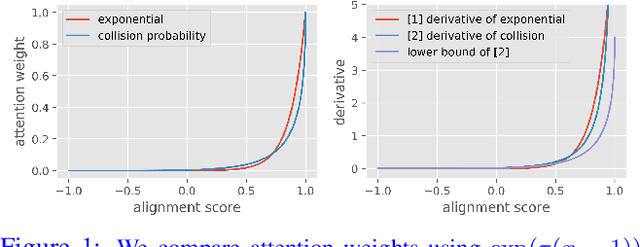


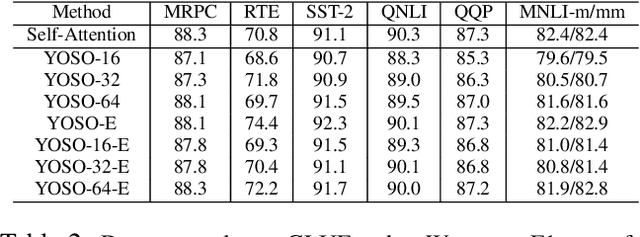
Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear. We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant). This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark, for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at https://github.com/mlpen/YOSO