 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Sample Once: Linear Cost Self-Attention Via Bernoulli Sampling
Nov 18, 2021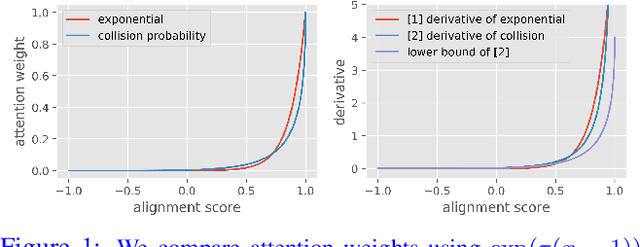


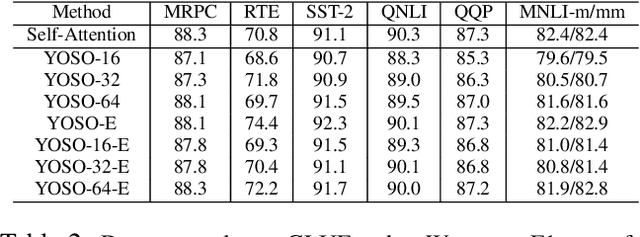
Transformer-based models are widely used in natural language processing (NLP). Central to the transformer model is the self-attention mechanism, which captures the interactions of token pairs in the input sequences and depends quadratically on the sequence length. Training such models on longer sequences is expensive. In this paper, we show that a Bernoulli sampling attention mechanism based on Locality Sensitive Hashing (LSH), decreases the quadratic complexity of such models to linear. We bypass the quadratic cost by considering self-attention as a sum of individual tokens associated with Bernoulli random variables that can, in principle, be sampled at once by a single hash (although in practice, this number may be a small constant). This leads to an efficient sampling scheme to estimate self-attention which relies on specific modifications of LSH (to enable deployment on GPU architectures). We evaluate our algorithm on the GLUE benchmark with standard 512 sequence length where we see favorable performance relative to a standard pretrained Transformer. On the Long Range Arena (LRA) benchmark, for evaluating performance on long sequences, our method achieves results consistent with softmax self-attention but with sizable speed-ups and memory savings and often outperforms other efficient self-attention methods. Our code is available at https://github.com/mlpen/YOSO
Efficient Document Image Classification Using Region-Based Graph Neural Network
Jun 25, 2021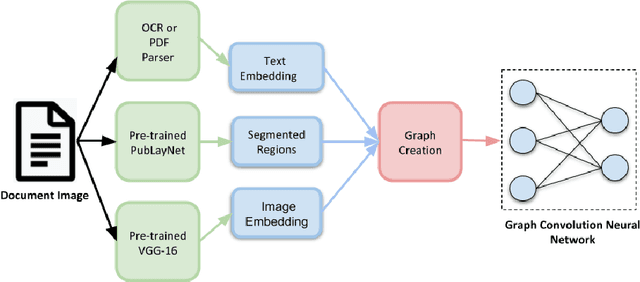
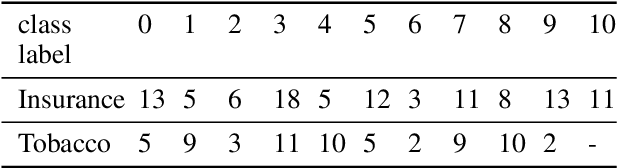

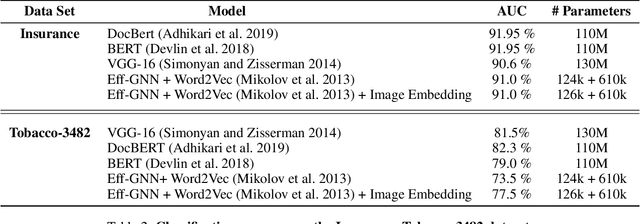
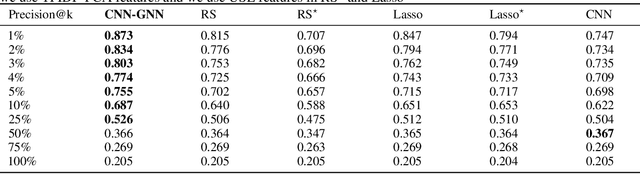
Document image classification remains a popular research area because it can be commercialized in many enterprise applications across different industries. Recent advancements in large pre-trained computer vision and language models and graph neural networks has lent document image classification many tools. However using large pre-trained models usually requires substantial computing resources which could defeat the cost-saving advantages of automatic document image classification. In the paper we propose an efficient document image classification framework that uses graph convolution neural networks and incorporates textual, visual and layout information of the document. We have rigorously benchmarked our proposed algorithm against several state-of-art vision and language models on both publicly available dataset and a real-life insurance document classification dataset. Empirical results on both publicly available and real-world data show that our methods achieve near SOTA performance yet require much less computing resources and time for model training and inference. This results in solutions than offer better cost advantages, especially in scalable deployment for enterprise applications. The results showed that our algorithm can achieve classification performance quite close to SOTA. We also provide comprehensive comparisons of computing resources, model sizes, train and inference time between our proposed methods and baselines. In addition we delineate the cost per image using our method and other baselines.
Weighting vectors for machine learning: numerical harmonic analysis applied to boundary detection
Jun 01, 2021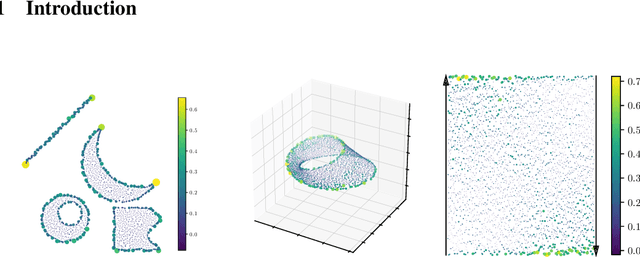
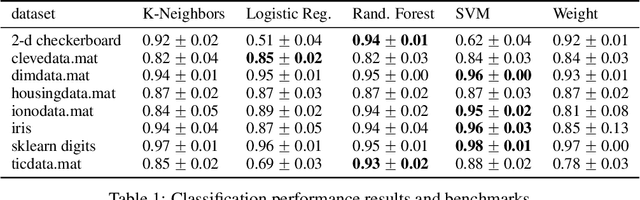


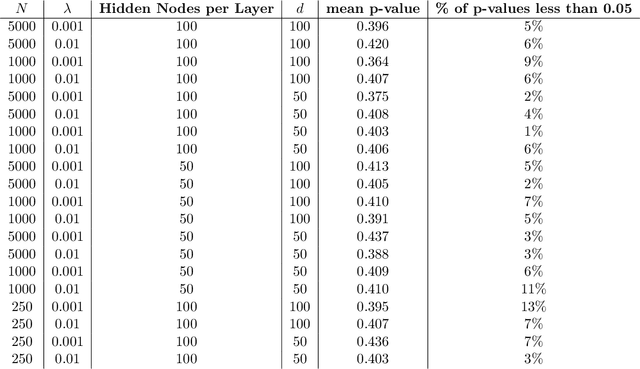
Metric space magnitude, an active field of research in algebraic topology, is a scalar quantity that summarizes the effective number of distinct points that live in a general metric space. The {\em weighting vector} is a closely-related concept that captures, in a nontrivial way, much of the underlying geometry of the original metric space. Recent work has demonstrated that when the metric space is Euclidean, the weighting vector serves as an effective tool for boundary detection. We recast this result and show the weighting vector may be viewed as a solution to a kernelized SVM. As one consequence, we apply this new insight to the task of outlier detection, and we demonstrate performance that is competitive or exceeds performance of state-of-the-art techniques on benchmark data sets. Under mild assumptions, we show the weighting vector, which has computational cost of matrix inversion, can be efficiently approximated in linear time. We show how nearest neighbor methods can approximate solutions to the minimization problems defined by SVMs.
Nyströmformer: A Nyström-Based Algorithm for Approximating Self-Attention
Mar 05, 2021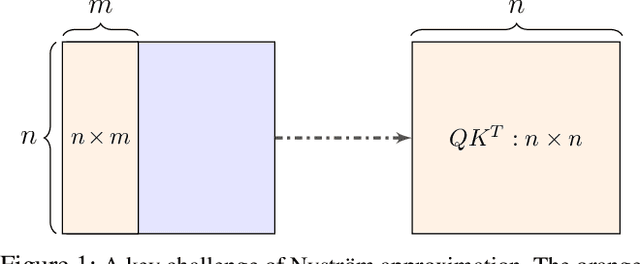

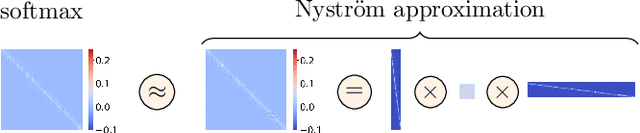

Transformers have emerged as a powerful tool for a broad range of natural language processing tasks. A key component that drives the impressive performance of Transformers is the self-attention mechanism that encodes the influence or dependence of other tokens on each specific token. While beneficial, the quadratic complexity of self-attention on the input sequence length has limited its application to longer sequences -- a topic being actively studied in the community. To address this limitation, we propose Nystr\"{o}mformer -- a model that exhibits favorable scalability as a function of sequence length. Our idea is based on adapting the Nystr\"{o}m method to approximate standard self-attention with $O(n)$ complexity. The scalability of Nystr\"{o}mformer enables application to longer sequences with thousands of tokens. We perform evaluations on multiple downstream tasks on the GLUE benchmark and IMDB reviews with standard sequence length, and find that our Nystr\"{o}mformer performs comparably, or in a few cases, even slightly better, than standard self-attention. On longer sequence tasks in the Long Range Arena (LRA) benchmark, Nystr\"{o}mformer performs favorably relative to other efficient self-attention methods. Our code is available at https://github.com/mlpen/Nystromformer.
A Simple yet Brisk and Efficient Active Learning Platform for Text Classification
Jan 31, 2021
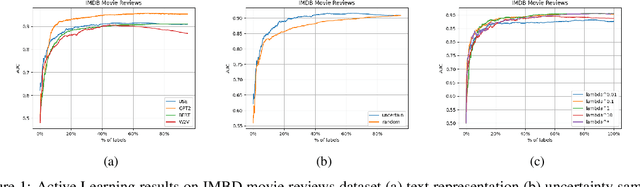
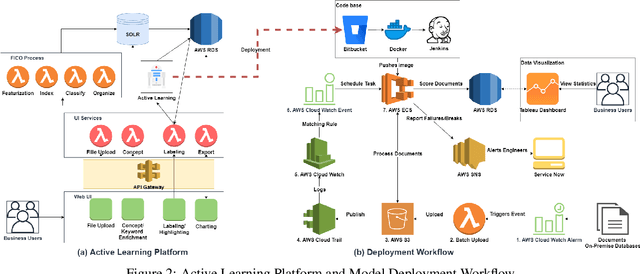

In this work, we propose the use of a fully managed machine learning service, which utilizes active learning to directly build models from unstructured data. With this tool, business users can quickly and easily build machine learning models and then directly deploy them into a production ready hosted environment without much involvement from data scientists. Our approach leverages state-of-the-art text representation like OpenAI's GPT2 and a fast implementation of the active learning workflow that relies on a simple construction of incremental learning using linear models, thus providing a brisk and efficient labeling experience for the users. Experiments on both publicly available and real-life insurance datasets empirically show why our choices of simple and fast classification algorithms are ideal for the task at hand.
Graph Neural Networks to Predict Customer Satisfaction Following Interactions with a Corporate Call Center
Jan 31, 2021


Customer satisfaction is an important factor in creating and maintaining long-term relationships with customers. Near real-time identification of potentially dissatisfied customers following phone calls can provide organizations the opportunity to take meaningful interventions and to foster ongoing customer satisfaction and loyalty. This work describes a fully operational system we have developed at a large US company for predicting customer satisfaction following incoming phone calls. The system takes as an input speech-to-text transcriptions of calls and predicts call satisfaction reported by customers on post-call surveys (scale from 1 to 10). Because of its ordinal, subjective, and often highly-skewed nature, predicting survey scores is not a trivial task and presents several modeling challenges. We introduce a graph neural network (GNN) approach that takes into account the comparative nature of the problem by considering the relative scores among batches, instead of only pairs of calls when training. This approach produces more accurate predictions than previous approaches including standard regression and classification models that directly fit the survey scores with call data. Our proposed approach can be easily generalized to other customer satisfaction prediction problems.
SGD Distributional Dynamics of Three Layer Neural Networks
Dec 30, 2020


With the rise of big data analytics, multi-layer neural networks have surfaced as one of the most powerful machine learning methods. However, their theoretical mathematical properties are still not fully understood. Training a neural network requires optimizing a non-convex objective function, typically done using stochastic gradient descent (SGD). In this paper, we seek to extend the mean field results of Mei et al. (2018) from two-layer neural networks with one hidden layer to three-layer neural networks with two hidden layers. We will show that the SGD dynamics is captured by a set of non-linear partial differential equations, and prove that the distributions of weights in the two hidden layers are independent. We will also detail exploratory work done based on simulation and real-world data.
Practical applications of metric space magnitude and weighting vectors
Jul 02, 2020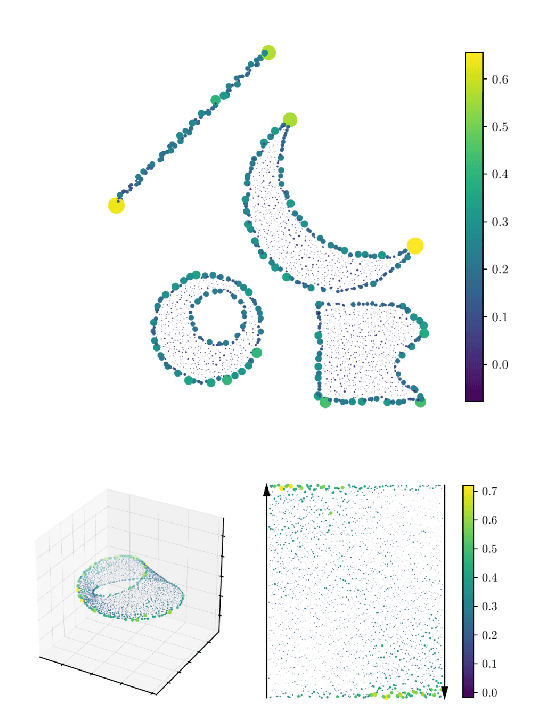
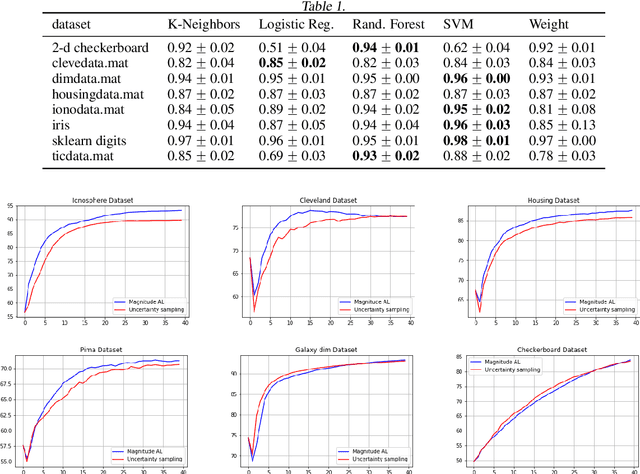

Metric space magnitude, an active subject of research in algebraic topology, originally arose in the context of biology, where it was used to represent the effective number of distinct species in an environment. In a more general setting, the magnitude of a metric space is a real number that aims to quantify the effective number of distinct points in the space. The contribution of each point to a metric space's global magnitude, which is encoded by the {\em weighting vector}, captures much of the underlying geometry of the original metric space. Surprisingly, when the metric space is Euclidean, the weighting vector also serves as an effective tool for boundary detection. This allows the weighting vector to serve as the foundation of novel algorithms for classic machine learning tasks such as classification, outlier detection and active learning. We demonstrate, using experiments and comparisons on classic benchmark datasets, the promise of the proposed magnitude and weighting vector-based approaches.
Ordinal Regression using Noisy Pairwise Comparisons for Body Mass Index Range Estimation
Nov 08, 2018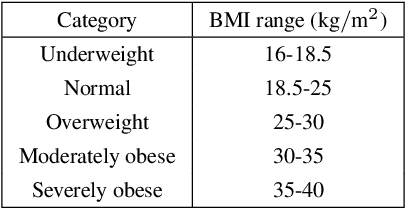
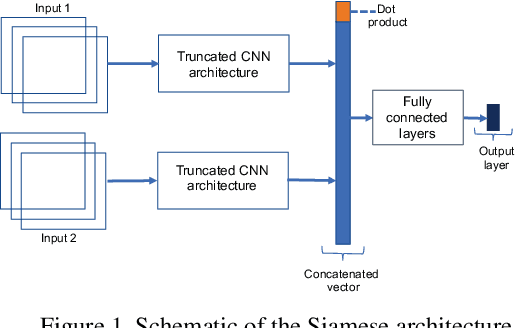


Ordinal regression aims to classify instances into ordinal categories. In this paper, body mass index (BMI) category estimation from facial images is cast as an ordinal regression problem. In particular, noisy binary search algorithms based on pairwise comparisons are employed to exploit the ordinal relationship among BMI categories. Comparisons are performed with Siamese architectures, one of which uses the Bradley-Terry model probabilities as target. The Bradley-Terry model is an approach to describe probabilities of the possible outcomes when elements of a set are repeatedly compared with one another in pairs. Experimental results show that our approach outperforms classification and regression-based methods at estimating BMI categories.
Evaluating Crowdsourcing Participants in the Absence of Ground-Truth
May 30, 2016
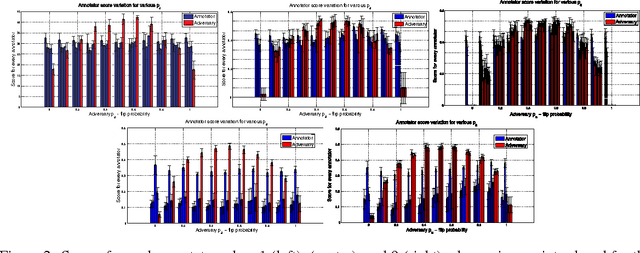
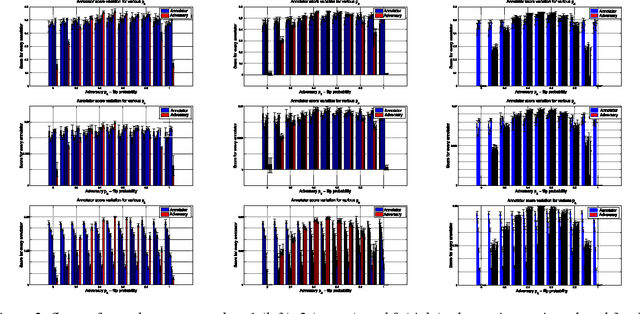
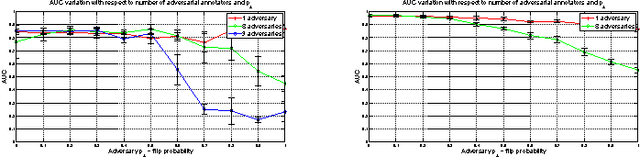
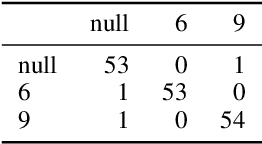
Given a supervised/semi-supervised learning scenario where multiple annotators are available, we consider the problem of identification of adversarial or unreliable annotators.