 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Relationship between Quantum Walks and Underdamped Langevin Dynamics
Jan 04, 2026Fast computational algorithms are in constant demand, and their development has been driven by advances such as quantum speedup and classical acceleration. This paper intends to study search algorithms based on quantum walks in quantum computation and sampling algorithms based on Langevin dynamics in classical computation. On the quantum side, quantum walk-based search algorithms can achieve quadratic speedups over their classical counterparts. In classical computation, a substantial body of work has focused on gradient acceleration, with gradient-adjusted algorithms derived from underdamped Langevin dynamics providing quadratic acceleration over conventional Langevin algorithms. Since both search and sampling algorithms are designed to address learning tasks, we study learning relationship between coined quantum walks and underdamped Langevin dynamics. Specifically, we show that, in terms of the Le Cam deficiency distance, a quantum walk with randomization is asymptotically equivalent to underdamped Langevin dynamics, whereas the quantum walk without randomization is not asymptotically equivalent due to its high-frequency oscillatory behavior. We further discuss the implications of these equivalence and nonequivalence results for the computational and inferential properties of the associated algorithms in machine learning tasks. Our findings offer new insight into the relationship between quantum walks and underdamped Langevin dynamics, as well as the intrinsic mechanisms underlying quantum speedup and classical gradient acceleration.
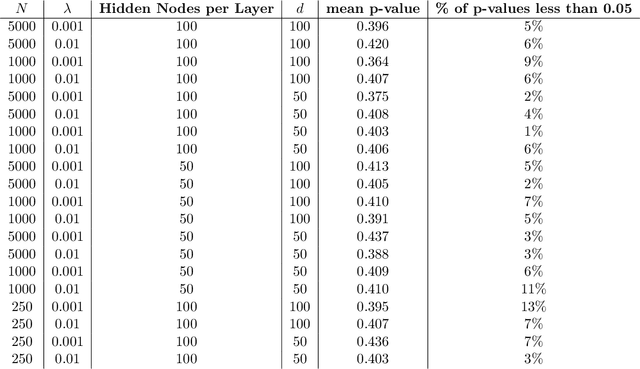
Computational and Statistical Asymptotic Analysis of the JKO Scheme for Iterative Algorithms to update distributions
Jan 14, 2025The seminal paper of Jordan, Kinderlehrer, and Otto introduced what is now widely known as the JKO scheme, an iterative algorithmic framework for computing distributions. This scheme can be interpreted as a Wasserstein gradient flow and has been successfully applied in machine learning contexts, such as deriving policy solutions in reinforcement learning. In this paper, we extend the JKO scheme to accommodate models with unknown parameters. Specifically, we develop statistical methods to estimate these parameters and adapt the JKO scheme to incorporate the estimated values. To analyze the adopted statistical JKO scheme, we establish an asymptotic theory via stochastic partial differential equations that describes its limiting dynamic behavior. Our framework allows both the sample size used in parameter estimation and the number of algorithmic iterations to go to infinity. This study offers a unified framework for joint computational and statistical asymptotic analysis of the statistical JKO scheme. On the computational side, we examine the scheme's dynamic behavior as the number of iterations increases, while on the statistical side, we investigate the large-sample behavior of the resulting distributions computed through the scheme. We conduct numerical simulations to evaluate the finite-sample performance of the proposed methods and validate the developed asymptotic theory.
Robust Reinforcement Learning under Diffusion Models for Data with Jumps
Nov 18, 2024
Reinforcement Learning (RL) has proven effective in solving complex decision-making tasks across various domains, but challenges remain in continuous-time settings, particularly when state dynamics are governed by stochastic differential equations (SDEs) with jump components. In this paper, we address this challenge by introducing the Mean-Square Bipower Variation Error (MSBVE) algorithm, which enhances robustness and convergence in scenarios involving significant stochastic noise and jumps. We first revisit the Mean-Square TD Error (MSTDE) algorithm, commonly used in continuous-time RL, and highlight its limitations in handling jumps in state dynamics. The proposed MSBVE algorithm minimizes the mean-square quadratic variation error, offering improved performance over MSTDE in environments characterized by SDEs with jumps. Simulations and formal proofs demonstrate that the MSBVE algorithm reliably estimates the value function in complex settings, surpassing MSTDE's performance when faced with jump processes. These findings underscore the importance of alternative error metrics to improve the resilience and effectiveness of RL algorithms in continuous-time frameworks.
SGD Distributional Dynamics of Three Layer Neural Networks
Dec 30, 2020


With the rise of big data analytics, multi-layer neural networks have surfaced as one of the most powerful machine learning methods. However, their theoretical mathematical properties are still not fully understood. Training a neural network requires optimizing a non-convex objective function, typically done using stochastic gradient descent (SGD). In this paper, we seek to extend the mean field results of Mei et al. (2018) from two-layer neural networks with one hidden layer to three-layer neural networks with two hidden layers. We will show that the SGD dynamics is captured by a set of non-linear partial differential equations, and prove that the distributions of weights in the two hidden layers are independent. We will also detail exploratory work done based on simulation and real-world data.
Optimal High-order Tensor SVD via Tensor-Train Orthogonal Iteration
Oct 06, 2020



This paper studies a general framework for high-order tensor SVD. We propose a new computationally efficient algorithm, tensor-train orthogonal iteration (TTOI), that aims to estimate the low tensor-train rank structure from the noisy high-order tensor observation. The proposed TTOI consists of initialization via TT-SVD (Oseledets, 2011) and new iterative backward/forward updates. We develop the general upper bound on estimation error for TTOI with the support of several new representation lemmas on tensor matricizations. By developing a matching information-theoretic lower bound, we also prove that TTOI achieves the minimax optimality under the spiked tensor model. The merits of the proposed TTOI are illustrated through applications to estimation and dimension reduction of high-order Markov processes, numerical studies, and a real data example on New York City taxi travel records. The software of the proposed algorithm is available online.
How Many Factors Influence Minima in SGD?
Sep 24, 2020



Stochastic gradient descent (SGD) is often applied to train Deep Neural Networks (DNNs), and research efforts have been devoted to investigate the convergent dynamics of SGD and minima found by SGD. The influencing factors identified in the literature include learning rate, batch size, Hessian, and gradient covariance, and stochastic differential equations are used to model SGD and establish the relationships among these factors for characterizing minima found by SGD. It has been found that the ratio of batch size to learning rate is a main factor in highlighting the underlying SGD dynamics; however, the influence of other important factors such as the Hessian and gradient covariance is not entirely agreed upon. This paper describes the factors and relationships in the recent literature and presents numerical findings on the relationships. In particular, it confirms the four-factor and general relationship results obtained in Wang (2019), while the three-factor and associated relationship results found in Jastrz\c{e}bski et al. (2018) may not hold beyond the considered special case.
Asymptotic Analysis via Stochastic Differential Equations of Gradient Descent Algorithms in Statistical and Computational Paradigms
Mar 14, 2018
This paper investigates asymptotic behaviors of gradient descent algorithms (particularly accelerated gradient descent and stochastic gradient descent) in the context of stochastic optimization arose in statistics and machine learning where objective functions are estimated from available data. We show that these algorithms can be modeled by continuous-time ordinary or stochastic differential equations, and their asymptotic dynamic evolutions and distributions are governed by some linear ordinary or stochastic differential equations, as the data size goes to infinity. We illustrate that our study can provide a novel unified framework for a joint computational and statistical asymptotic analysis on dynamic behaviors of these algorithms with the time (or the number of iterations in the algorithms) and large sample behaviors of the statistical decision rules (like estimators and classifiers) that the algorithms are applied to compute, where the statistical decision rules are the limits of the random sequences generated from these iterative algorithms as the number of iterations goes to infinity.