 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Reinforcement Learning under Diffusion Models for Data with Jumps
Nov 18, 2024
Reinforcement Learning (RL) has proven effective in solving complex decision-making tasks across various domains, but challenges remain in continuous-time settings, particularly when state dynamics are governed by stochastic differential equations (SDEs) with jump components. In this paper, we address this challenge by introducing the Mean-Square Bipower Variation Error (MSBVE) algorithm, which enhances robustness and convergence in scenarios involving significant stochastic noise and jumps. We first revisit the Mean-Square TD Error (MSTDE) algorithm, commonly used in continuous-time RL, and highlight its limitations in handling jumps in state dynamics. The proposed MSBVE algorithm minimizes the mean-square quadratic variation error, offering improved performance over MSTDE in environments characterized by SDEs with jumps. Simulations and formal proofs demonstrate that the MSBVE algorithm reliably estimates the value function in complex settings, surpassing MSTDE's performance when faced with jump processes. These findings underscore the importance of alternative error metrics to improve the resilience and effectiveness of RL algorithms in continuous-time frameworks.
GECKO: Generative Language Model for English, Code and Korean
May 24, 2024We introduce GECKO, a bilingual large language model (LLM) optimized for Korean and English, along with programming languages. GECKO is pretrained on the balanced, high-quality corpus of Korean and English employing LLaMA architecture. In this report, we share the experiences of several efforts to build a better data pipeline for the corpus and to train our model. GECKO shows great efficiency in token generations for both Korean and English, despite its small size of vocabulary. We measure the performance on the representative benchmarks in terms of Korean, English and Code, and it exhibits great performance on KMMLU (Korean MMLU) and modest performance in English and Code, even with its smaller number of trained tokens compared to English-focused LLMs. GECKO is available to the open-source community under a permissive license. We hope our work offers a research baseline and practical insights for Korean LLM research. The model can be found at: https://huggingface.co/kifai/GECKO-7B
Revisiting Early-Learning Regularization When Federated Learning Meets Noisy Labels
Feb 08, 2024In the evolving landscape of federated learning (FL), addressing label noise presents unique challenges due to the decentralized and diverse nature of data collection across clients. Traditional centralized learning approaches to mitigate label noise are constrained in FL by privacy concerns and the heterogeneity of client data. This paper revisits early-learning regularization, introducing an innovative strategy, Federated Label-mixture Regularization (FLR). FLR adeptly adapts to FL's complexities by generating new pseudo labels, blending local and global model predictions. This method not only enhances the accuracy of the global model in both i.i.d. and non-i.i.d. settings but also effectively counters the memorization of noisy labels. Demonstrating compatibility with existing label noise and FL techniques, FLR paves the way for improved generalization in FL environments fraught with label inaccuracies.
The Effect of Trust and its Antecedents on Robot Acceptance
Nov 11, 2023


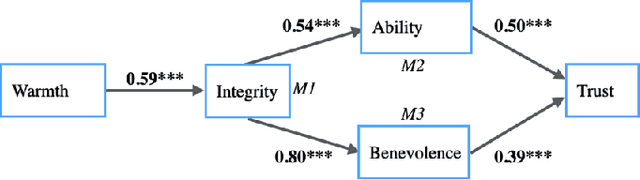
As social and socially assistive robots are becoming more prevalent in our society, it is beneficial to understand how people form first impressions of them and eventually come to trust and accept them. This paper describes an Amazon Mechanical Turk study (n = 239) that investigated trust and its antecedents trustworthiness and first impressions. Participants evaluated the social robot Pepper's warmth and competence as well as trustworthiness characteristics ability, benevolence and integrity followed by their trust in and intention to use the robot. Mediation analyses assessed to what degree participants' first impressions affected their willingness to trust and use it. Known constructs from user acceptance and trust research were introduced to explain the pathways in which one perception predicted the next. Results showed that trustworthiness and trust, in serial, mediated the relationship between first impressions and behavioral intention.
Benchmark Dataset for Precipitation Forecasting by Post-Processing the Numerical Weather Prediction
Jun 30, 2022
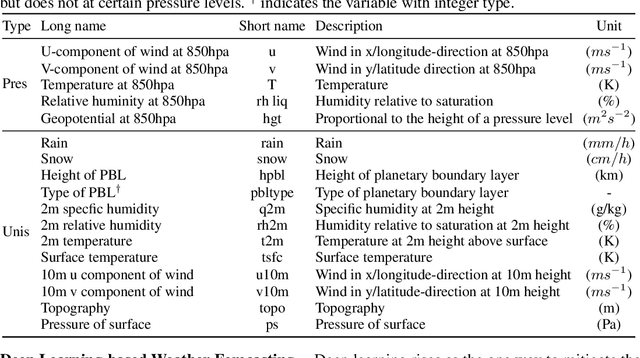
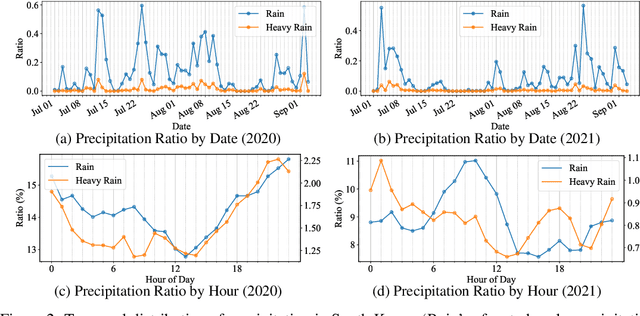
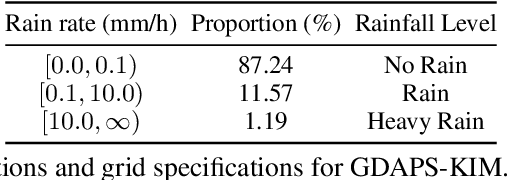
Precipitation forecasting is an important scientific challenge that has wide-reaching impacts on society. Historically, this challenge has been tackled using numerical weather prediction (NWP) models, grounded on physics-based simulations. Recently, many works have proposed an alternative approach, using end-to-end deep learning (DL) models to replace physics-based NWP. While these DL methods show improved performance and computational efficiency, they exhibit limitations in long-term forecasting and lack the explainability of NWP models. In this work, we present a hybrid NWP-DL workflow to fill the gap between standalone NWP and DL approaches. Under this workflow, the NWP output is fed into a deep model, which post-processes the data to yield a refined precipitation forecast. The deep model is trained with supervision, using Automatic Weather Station (AWS) observations as ground-truth labels. This can achieve the best of both worlds, and can even benefit from future improvements in NWP technology. To facilitate study in this direction, we present a novel dataset focused on the Korean Peninsula, termed KoMet (Korea Meteorological Dataset), comprised of NWP predictions and AWS observations. For NWP, we use the Global Data Assimilation and Prediction Systems-Korea Integrated Model (GDAPS-KIM).
Self-supervised Text-to-SQL Learning with Header Alignment Training
Mar 11, 2021

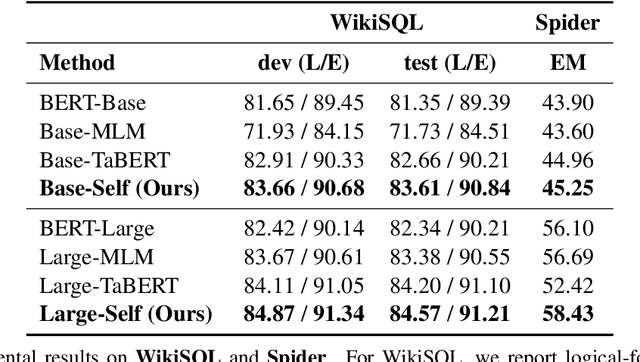

Since we can leverage a large amount of unlabeled data without any human supervision to train a model and transfer the knowledge to target tasks, self-supervised learning is a de-facto component for the recent success of deep learning in various fields. However, in many cases, there is a discrepancy between a self-supervised learning objective and a task-specific objective. In order to tackle such discrepancy in Text-to-SQL task, we propose a novel self-supervised learning framework. We utilize the task-specific properties of Text-to-SQL task and the underlying structures of table contents to train the models to learn useful knowledge of the \textit{header-column} alignment task from unlabeled table data. We are able to transfer the knowledge to the supervised Text-to-SQL training with annotated samples, so that the model can leverage the knowledge to better perform the \textit{header-span} alignment task to predict SQL statements. Experimental results show that our self-supervised learning framework significantly improves the performance of the existing strong BERT based models without using large external corpora. In particular, our method is effective for training the model with scarce labeled data. The source code of this work is available in GitHub.
Domain-agnostic Question-Answering with Adversarial Training
Oct 22, 2019
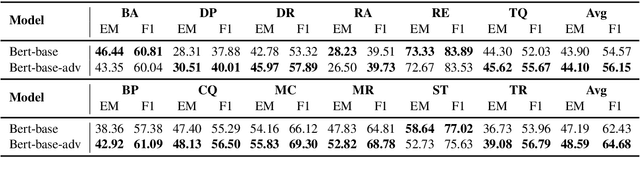
Adapting models to new domain without finetuning is a challenging problem in deep learning. In this paper, we utilize an adversarial training framework for domain generalization in Question Answering (QA) task. Our model consists of a conventional QA model and a discriminator. The training is performed in the adversarial manner, where the two models constantly compete, so that QA model can learn domain-invariant features. We apply this approach in MRQA Shared Task 2019 and show better performance compared to the baseline model.