 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Text-to-SQL Learning with Header Alignment Training
Paper and Code


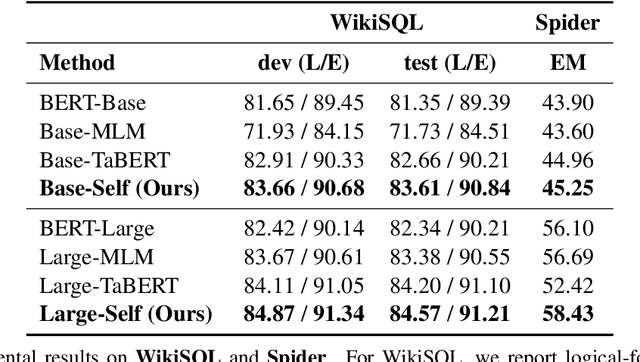

Since we can leverage a large amount of unlabeled data without any human supervision to train a model and transfer the knowledge to target tasks, self-supervised learning is a de-facto component for the recent success of deep learning in various fields. However, in many cases, there is a discrepancy between a self-supervised learning objective and a task-specific objective. In order to tackle such discrepancy in Text-to-SQL task, we propose a novel self-supervised learning framework. We utilize the task-specific properties of Text-to-SQL task and the underlying structures of table contents to train the models to learn useful knowledge of the \textit{header-column} alignment task from unlabeled table data. We are able to transfer the knowledge to the supervised Text-to-SQL training with annotated samples, so that the model can leverage the knowledge to better perform the \textit{header-span} alignment task to predict SQL statements. Experimental results show that our self-supervised learning framework significantly improves the performance of the existing strong BERT based models without using large external corpora. In particular, our method is effective for training the model with scarce labeled data. The source code of this work is available in GitHub.