 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hybrid optimization approach for employee rostering: Use cases at Swissgrid and lessons learned
Nov 21, 2021

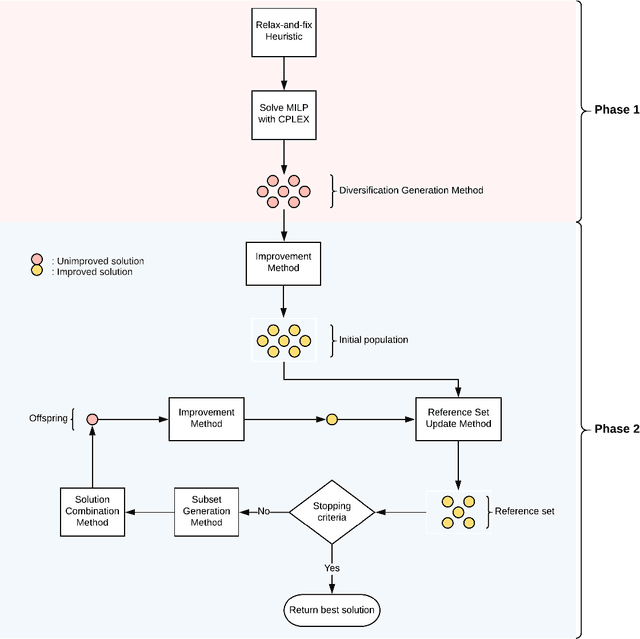
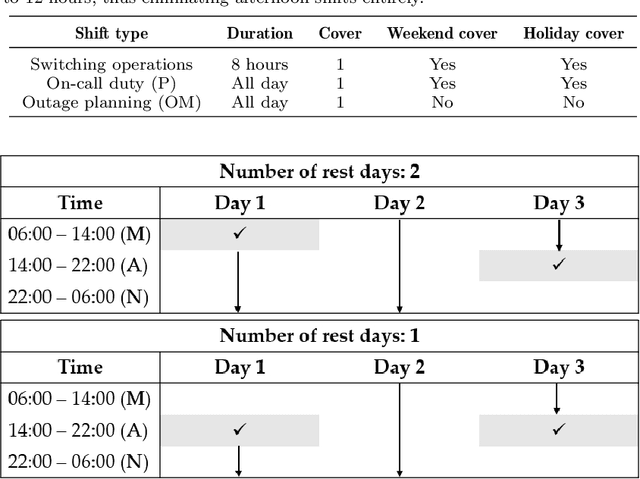
Employee rostering is a process of assigning available employees to open shifts. Automating it has ubiquitous practical benefits for nearly all industries, such as reducing manual workload and producing flexible, high-quality schedules. In this work, we develop a hybrid methodology which combines Mixed-Integer Linear Programming (MILP) with scatter search, an evolutionary algorithm, having as use case the optimization of employee rostering for Swissgrid, where it is currently a largely manual process. The hybrid methodology guarantees compliance with labor laws, maximizes employees' preference satisfaction, and distributes workload as uniformly as possible among them. Above all, it is shown to be a robust and efficient algorithm, consistently solving realistic problems of varying complexity to near-optimality an order of magnitude faster than an MILP-alone approach using a state-of-the-art commercial solver. Several practical extensions and use cases are presented, which are incorporated into a software tool currently being in pilot use at Swissgrid.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021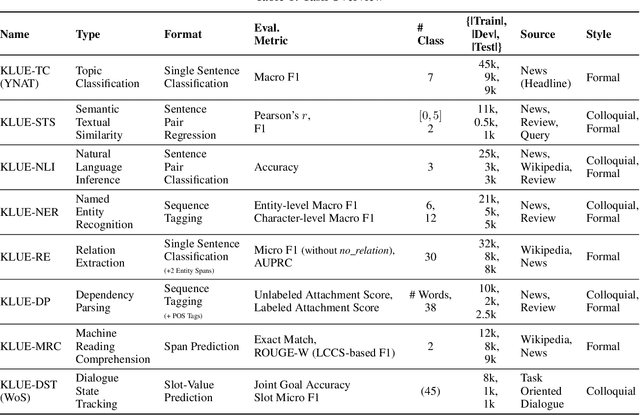
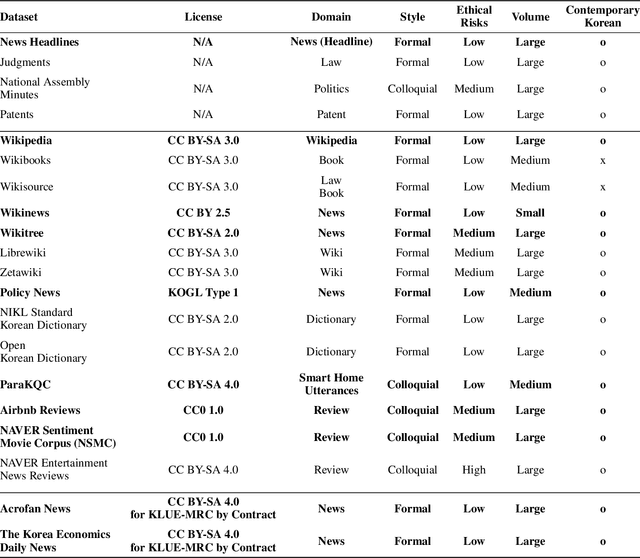
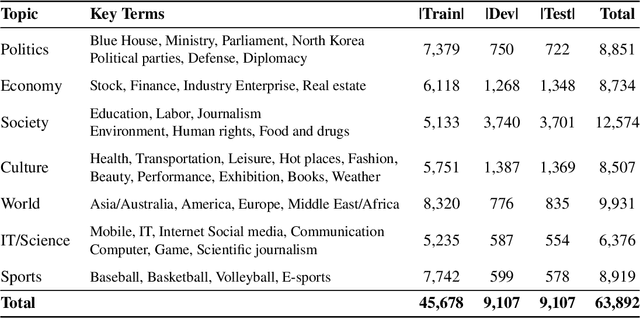
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.
Domain-agnostic Question-Answering with Adversarial Training
Oct 22, 2019
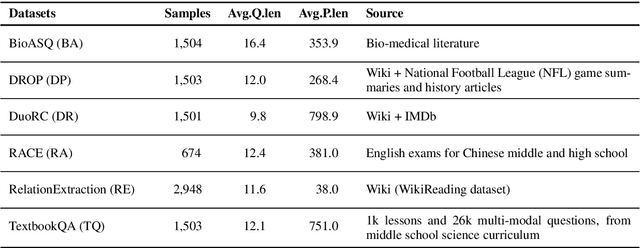
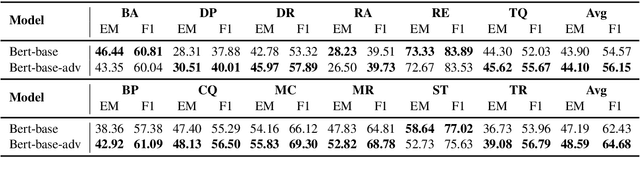
Adapting models to new domain without finetuning is a challenging problem in deep learning. In this paper, we utilize an adversarial training framework for domain generalization in Question Answering (QA) task. Our model consists of a conventional QA model and a discriminator. The training is performed in the adversarial manner, where the two models constantly compete, so that QA model can learn domain-invariant features. We apply this approach in MRQA Shared Task 2019 and show better performance compared to the baseline model.