 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinq-Embed-Mistral Technical Report
Dec 04, 2024
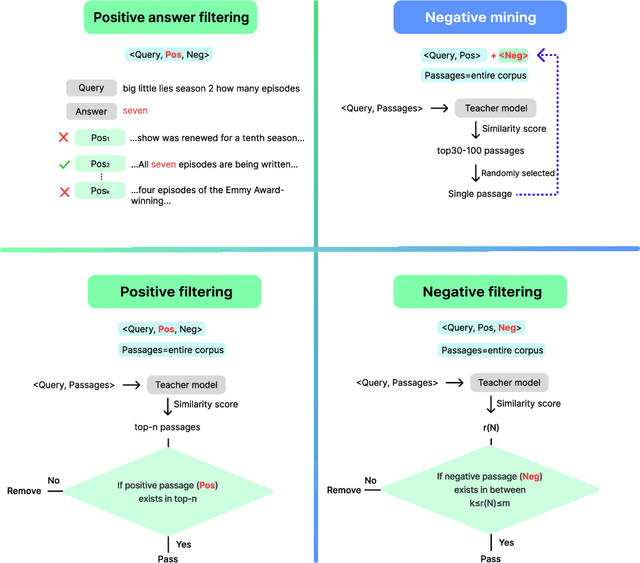

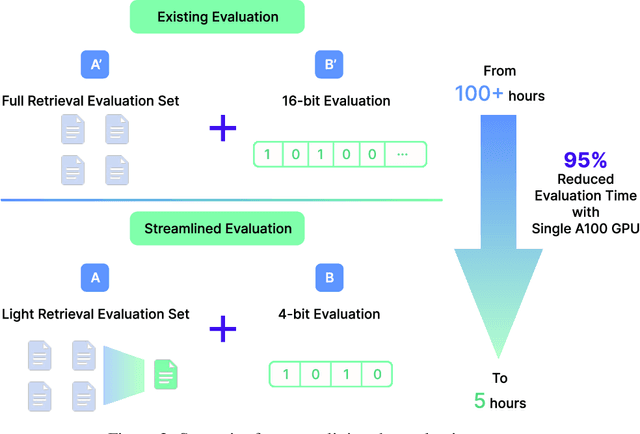
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.
Re-Ex: Revising after Explanation Reduces the Factual Errors in LLM Responses
Feb 27, 2024



Mitigating hallucination issues is one of the main challenges of LLMs we need to overcome, in order to reliably use them in real-world scenarios. Recently, various methods are proposed to check the factual errors in the LLM-generated texts and revise them accordingly, to reduce the hallucination issue. In this paper, we propose Re-Ex, a method of revising LLM-generated texts, which introduces a novel step dubbed as the factual error explanation step. Re-Ex revises the initial response of LLMs using 3-steps: first, external tools are used to get the evidences on the factual errors in the response; second, LLMs are instructed to explain the problematic parts of the response based on the evidences gathered in the first step; finally, LLMs revise the response using the explanation obtained in the second step. In addition to the explanation step, we propose new prompting techniques to reduce the amount of tokens and wall-clock time required for the response revision process. Compared with existing methods including Factool, CoVE, and RARR, Re-Ex provides better revision performance with less time and fewer tokens in multiple benchmarks.
Can Separators Improve Chain-of-Thought Prompting?
Feb 16, 2024



Chain-of-thought (CoT) prompting is a simple and effective method for improving the reasoning capabilities of Large language models (LLMs). The basic idea of CoT is to let LLMs break down their thought processes step-by-step by putting exemplars in the input prompt. However, the densely structured prompt exemplars of CoT may cause the cognitive overload of LLMs. Inspired by human cognition, we introduce CoT-Sep, a novel method that strategically employs separators at the end of each exemplar in CoT prompting. These separators are designed to help the LLMs understand their thought processes better while reasoning. It turns out that CoT-Sep significantly improves the LLMs' performances on complex reasoning tasks (e.g., GSM-8K, AQuA, CSQA), compared with the vanilla CoT, which does not use separators. We also study the effects of the type and the location of separators tested on multiple LLMs, including GPT-3.5-Turbo, GPT-4, and LLaMA-2 7B. Interestingly, the type/location of separators should be chosen appropriately to boost the reasoning capability of CoT.
KLUE: Korean Language Understanding Evaluation
Jun 11, 2021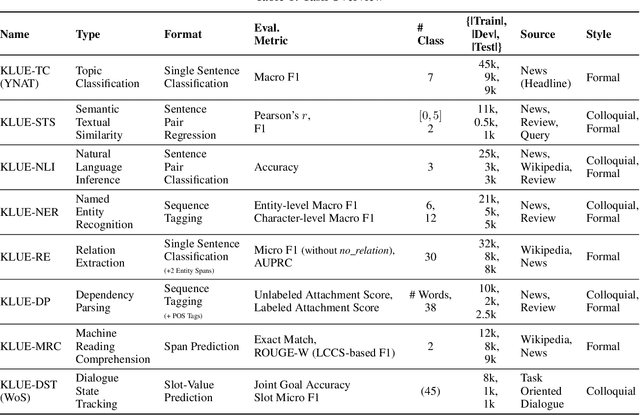
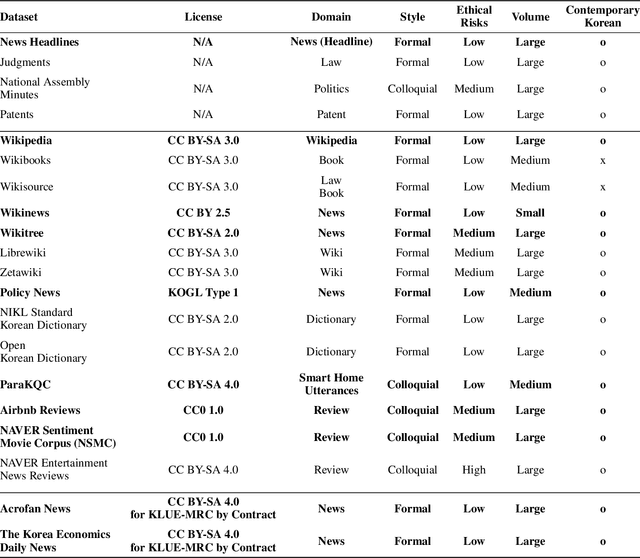
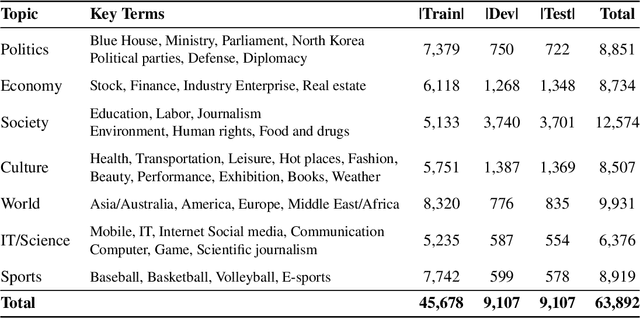
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, SemanticTextual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproducing baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at https://klue-benchmark.com.