 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREX: Tokenizer Regression for Optimal Data Mixture
Jan 20, 2026Building effective tokenizers for multilingual Large Language Models (LLMs) requires careful control over language-specific data mixtures. While a tokenizer's compression performance critically affects the efficiency of LLM training and inference, existing approaches rely on heuristics or costly large-scale searches to determine optimal language ratios. We introduce Tokenizer Regression for Optimal Data MiXture (TREX), a regression-based framework that efficiently predicts the optimal data mixture for tokenizer training. TREX trains small-scale proxy tokenizers on random mixtures, gathers their compression statistics, and learns to predict compression performance from data mixtures. This learned model enables scalable mixture search before large-scale tokenizer training, mitigating the accuracy-cost trade-off in multilingual tokenizer design. Tokenizers trained with TReX's predicted mixtures outperform mixtures based on LLaMA3 and uniform distributions by up to 12% in both inand out-of-distribution compression efficiency, demonstrating strong scalability, robustness, and practical effectiveness.
KORMo: Korean Open Reasoning Model for Everyone
Oct 10, 2025



This work presents the first large-scale investigation into constructing a fully open bilingual large language model (LLM) for a non-English language, specifically Korean, trained predominantly on synthetic data. We introduce KORMo-10B, a 10.8B-parameter model trained from scratch on a Korean-English corpus in which 68.74% of the Korean portion is synthetic. Through systematic experimentation, we demonstrate that synthetic data, when carefully curated with balanced linguistic coverage and diverse instruction styles, does not cause instability or degradation during large-scale pretraining. Furthermore, the model achieves performance comparable to that of contemporary open-weight multilingual baselines across a wide range of reasoning, knowledge, and instruction-following benchmarks. Our experiments reveal two key findings: (1) synthetic data can reliably sustain long-horizon pretraining without model collapse, and (2) bilingual instruction tuning enables near-native reasoning and discourse coherence in Korean. By fully releasing all components including data, code, training recipes, and logs, this work establishes a transparent framework for developing synthetic data-driven fully open models (FOMs) in low-resource settings and sets a reproducible precedent for future multilingual LLM research.
Linq-Embed-Mistral Technical Report
Dec 04, 2024
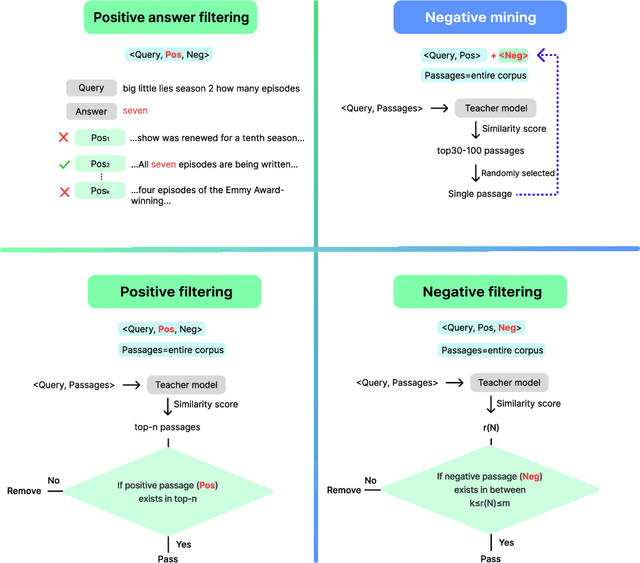

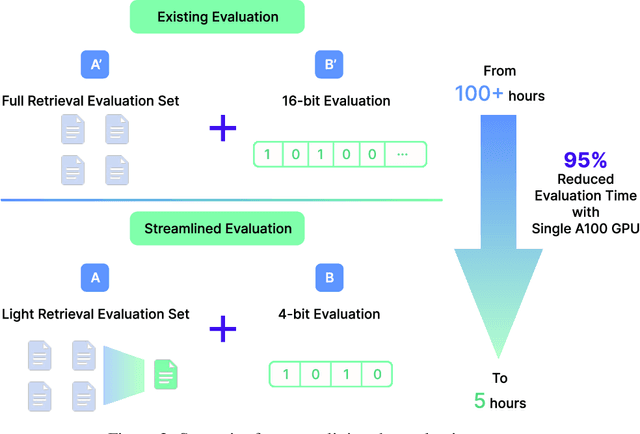
This report explores the enhancement of text retrieval performance using advanced data refinement techniques. We develop Linq-Embed-Mistral\footnote{\url{https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral}} by building on the E5-mistral and Mistral-7B-v0.1 models, focusing on sophisticated data crafting, data filtering, and negative mining methods, which are highly tailored to each task, applied to both existing benchmark dataset and highly tailored synthetic dataset generated via large language models (LLMs). Linq-Embed-Mistral excels in the MTEB benchmarks (as of May 29, 2024), achieving an average score of 68.2 across 56 datasets, and ranks 1st among all models for retrieval tasks on the MTEB leaderboard with a performance score of 60.2. This performance underscores its superior capability in enhancing search precision and reliability. Our contributions include advanced data refinement methods that significantly improve model performance on benchmark and synthetic datasets, techniques for homogeneous task ordering and mixed task fine-tuning to enhance model generalization and stability, and a streamlined evaluation process using 4-bit precision and a light retrieval evaluation set, which accelerates validation without sacrificing accuracy.