 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREX: Tokenizer Regression for Optimal Data Mixture
Jan 20, 2026Building effective tokenizers for multilingual Large Language Models (LLMs) requires careful control over language-specific data mixtures. While a tokenizer's compression performance critically affects the efficiency of LLM training and inference, existing approaches rely on heuristics or costly large-scale searches to determine optimal language ratios. We introduce Tokenizer Regression for Optimal Data MiXture (TREX), a regression-based framework that efficiently predicts the optimal data mixture for tokenizer training. TREX trains small-scale proxy tokenizers on random mixtures, gathers their compression statistics, and learns to predict compression performance from data mixtures. This learned model enables scalable mixture search before large-scale tokenizer training, mitigating the accuracy-cost trade-off in multilingual tokenizer design. Tokenizers trained with TReX's predicted mixtures outperform mixtures based on LLaMA3 and uniform distributions by up to 12% in both inand out-of-distribution compression efficiency, demonstrating strong scalability, robustness, and practical effectiveness.
KORMo: Korean Open Reasoning Model for Everyone
Oct 10, 2025



This work presents the first large-scale investigation into constructing a fully open bilingual large language model (LLM) for a non-English language, specifically Korean, trained predominantly on synthetic data. We introduce KORMo-10B, a 10.8B-parameter model trained from scratch on a Korean-English corpus in which 68.74% of the Korean portion is synthetic. Through systematic experimentation, we demonstrate that synthetic data, when carefully curated with balanced linguistic coverage and diverse instruction styles, does not cause instability or degradation during large-scale pretraining. Furthermore, the model achieves performance comparable to that of contemporary open-weight multilingual baselines across a wide range of reasoning, knowledge, and instruction-following benchmarks. Our experiments reveal two key findings: (1) synthetic data can reliably sustain long-horizon pretraining without model collapse, and (2) bilingual instruction tuning enables near-native reasoning and discourse coherence in Korean. By fully releasing all components including data, code, training recipes, and logs, this work establishes a transparent framework for developing synthetic data-driven fully open models (FOMs) in low-resource settings and sets a reproducible precedent for future multilingual LLM research.
Temporal Information Retrieval via Time-Specifier Model Merging
Jul 09, 2025The rapid expansion of digital information and knowledge across structured and unstructured sources has heightened the importance of Information Retrieval (IR). While dense retrieval methods have substantially improved semantic matching for general queries, they consistently underperform on queries with explicit temporal constraints--often those containing numerical expressions and time specifiers such as ``in 2015.'' Existing approaches to Temporal Information Retrieval (TIR) improve temporal reasoning but often suffer from catastrophic forgetting, leading to reduced performance on non-temporal queries. To address this, we propose Time-Specifier Model Merging (TSM), a novel method that enhances temporal retrieval while preserving accuracy on non-temporal queries. TSM trains specialized retrievers for individual time specifiers and merges them in to a unified model, enabling precise handling of temporal constraints without compromising non-temporal retrieval. Extensive experiments on both temporal and non-temporal datasets demonstrate that TSM significantly improves performance on temporally constrained queries while maintaining strong results on non-temporal queries, consistently outperforming other baseline methods. Our code is available at https://github.com/seungyoonee/TSM .
Spotting Out-of-Character Behavior: Atomic-Level Evaluation of Persona Fidelity in Open-Ended Generation
Jun 24, 2025Ensuring persona fidelity in large language models (LLMs) is essential for maintaining coherent and engaging human-AI interactions. However, LLMs often exhibit Out-of-Character (OOC) behavior, where generated responses deviate from an assigned persona, leading to inconsistencies that affect model reliability. Existing evaluation methods typically assign single scores to entire responses, struggling to capture subtle persona misalignment, particularly in long-form text generation. To address this limitation, we propose an atomic-level evaluation framework that quantifies persona fidelity at a finer granularity. Our three key metrics measure the degree of persona alignment and consistency within and across generations. Our approach enables a more precise and realistic assessment of persona fidelity by identifying subtle deviations that real users would encounter. Through our experiments, we demonstrate that our framework effectively detects persona inconsistencies that prior methods overlook. By analyzing persona fidelity across diverse tasks and personality types, we reveal how task structure and persona desirability influence model adaptability, highlighting challenges in maintaining consistent persona expression.
Does Rationale Quality Matter? Enhancing Mental Disorder Detection via Selective Reasoning Distillation
May 26, 2025The detection of mental health problems from social media and the interpretation of these results have been extensively explored. Research has shown that incorporating clinical symptom information into a model enhances domain expertise, improving its detection and interpretation performance. While large language models (LLMs) are shown to be effective for generating explanatory rationales in mental health detection, their substantially large parameter size and high computational cost limit their practicality. Reasoning distillation transfers this ability to smaller language models (SLMs), but inconsistencies in the relevance and domain alignment of LLM-generated rationales pose a challenge. This paper investigates how rationale quality impacts SLM performance in mental health detection and explanation generation. We hypothesize that ensuring high-quality and domain-relevant rationales enhances the distillation. To this end, we propose a framework that selects rationales based on their alignment with expert clinical reasoning. Experiments show that our quality-focused approach significantly enhances SLM performance in both mental disorder detection and rationale generation. This work highlights the importance of rationale quality and offers an insightful framework for knowledge transfer in mental health applications.
A Multi-Task Benchmark for Abusive Language Detection in Low-Resource Settings
May 17, 2025Content moderation research has recently made significant advances, but still fails to serve the majority of the world's languages due to the lack of resources, leaving millions of vulnerable users to online hostility. This work presents a large-scale human-annotated multi-task benchmark dataset for abusive language detection in Tigrinya social media with joint annotations for three tasks: abusiveness, sentiment, and topic classification. The dataset comprises 13,717 YouTube comments annotated by nine native speakers, collected from 7,373 videos with a total of over 1.2 billion views across 51 channels. We developed an iterative term clustering approach for effective data selection. Recognizing that around 64% of Tigrinya social media content uses Romanized transliterations rather than native Ge'ez script, our dataset accommodates both writing systems to reflect actual language use. We establish strong baselines across the tasks in the benchmark, while leaving significant challenges for future contributions. Our experiments reveal that small, specialized multi-task models outperform the current frontier models in the low-resource setting, achieving up to 86% accuracy (+7 points) in abusiveness detection. We make the resources publicly available to promote research on online safety.
Lossless Acceleration of Large Language Models with Hierarchical Drafting based on Temporal Locality in Speculative Decoding
Feb 08, 2025Accelerating inference in Large Language Models (LLMs) is critical for real-time interactions, as they have been widely incorporated into real-world services. Speculative decoding, a fully algorithmic solution, has gained attention for improving inference speed by drafting and verifying tokens, thereby generating multiple tokens in a single forward pass. However, current drafting strategies usually require significant fine-tuning or have inconsistent performance across tasks. To address these challenges, we propose Hierarchy Drafting (HD), a novel lossless drafting approach that organizes various token sources into multiple databases in a hierarchical framework based on temporal locality. In the drafting step, HD sequentially accesses multiple databases to obtain draft tokens from the highest to the lowest locality, ensuring consistent acceleration across diverse tasks and minimizing drafting latency. Our experiments on Spec-Bench using LLMs with 7B and 13B parameters demonstrate that HD outperforms existing database drafting methods, achieving robust inference speedups across model sizes, tasks, and temperatures.
EXIT: Context-Aware Extractive Compression for Enhancing Retrieval-Augmented Generation
Dec 17, 2024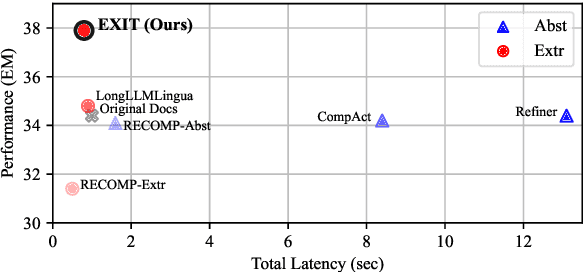
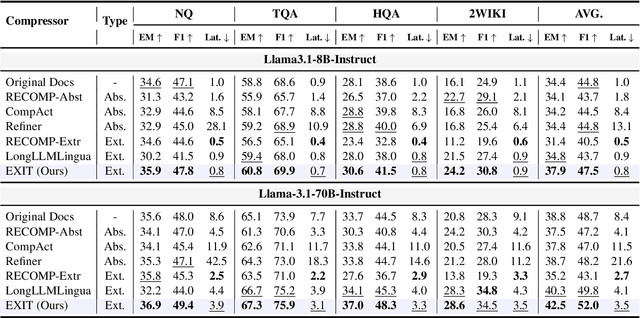
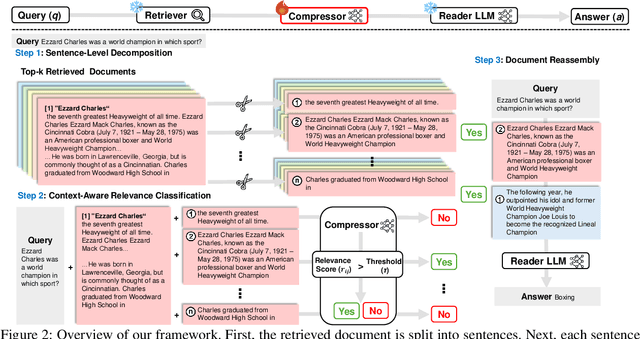
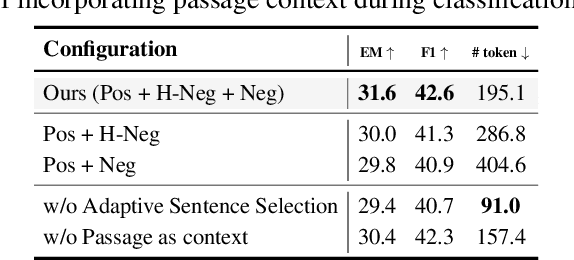
We introduce EXIT, an extractive context compression framework that enhances both the effectiveness and efficiency of retrieval-augmented generation (RAG) in question answering (QA). Current RAG systems often struggle when retrieval models fail to rank the most relevant documents, leading to the inclusion of more context at the expense of latency and accuracy. While abstractive compression methods can drastically reduce token counts, their token-by-token generation process significantly increases end-to-end latency. Conversely, existing extractive methods reduce latency but rely on independent, non-adaptive sentence selection, failing to fully utilize contextual information. EXIT addresses these limitations by classifying sentences from retrieved documents - while preserving their contextual dependencies - enabling parallelizable, context-aware extraction that adapts to query complexity and retrieval quality. Our evaluations on both single-hop and multi-hop QA tasks show that EXIT consistently surpasses existing compression methods and even uncompressed baselines in QA accuracy, while also delivering substantial reductions in inference time and token count. By improving both effectiveness and efficiency, EXIT provides a promising direction for developing scalable, high-quality QA solutions in RAG pipelines. Our code is available at https://github.com/ThisIsHwang/EXIT
Different Bias Under Different Criteria: Assessing Bias in LLMs with a Fact-Based Approach
Nov 26, 2024
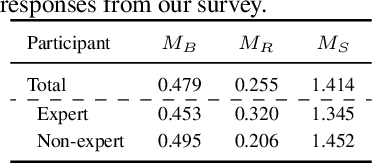
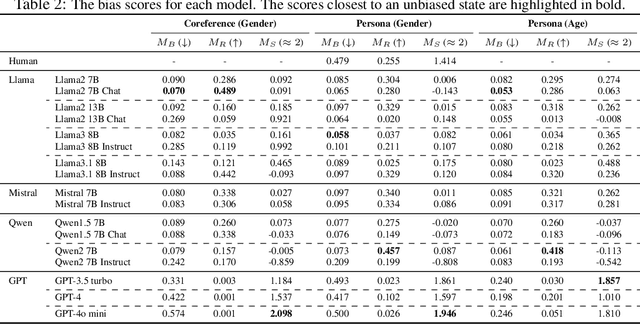
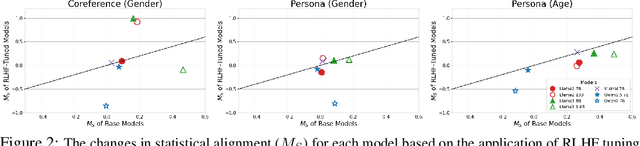
Large language models (LLMs) often reflect real-world biases, leading to efforts to mitigate these effects and make the models unbiased. Achieving this goal requires defining clear criteria for an unbiased state, with any deviation from these criteria considered biased. Some studies define an unbiased state as equal treatment across diverse demographic groups, aiming for balanced outputs from LLMs. However, differing perspectives on equality and the importance of pluralism make it challenging to establish a universal standard. Alternatively, other approaches propose using fact-based criteria for more consistent and objective evaluations, though these methods have not yet been fully applied to LLM bias assessments. Thus, there is a need for a metric with objective criteria that offers a distinct perspective from equality-based approaches. Motivated by this need, we introduce a novel metric to assess bias using fact-based criteria and real-world statistics. In this paper, we conducted a human survey demonstrating that humans tend to perceive LLM outputs more positively when they align closely with real-world demographic distributions. Evaluating various LLMs with our proposed metric reveals that model bias varies depending on the criteria used, highlighting the need for multi-perspective assessment.
Towards Effective Counter-Responses: Aligning Human Preferences with Strategies to Combat Online Trolling
Oct 05, 2024Trolling in online communities typically involves disruptive behaviors such as provoking anger and manipulating discussions, leading to a polarized atmosphere and emotional distress. Robust moderation is essential for mitigating these negative impacts and maintaining a healthy and constructive community atmosphere. However, effectively addressing trolls is difficult because their behaviors vary widely and require different response strategies (RSs) to counter them. This diversity makes it challenging to choose an appropriate RS for each specific situation. To address this challenge, our research investigates whether humans have preferred strategies tailored to different types of trolling behaviors. Our findings reveal a correlation between the types of trolling encountered and the preferred RS. In this paper, we introduce a methodology for generating counter-responses to trolls by recommending appropriate RSs, supported by a dataset aligning these strategies with human preferences across various troll contexts. The experimental results demonstrate that our proposed approach guides constructive discussion and reduces the negative effects of trolls, thereby enhancing the online community environment.