 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Multi-Agent Response Refinement in Conversational Systems
Nov 11, 2025Large Language Models (LLMs) have demonstrated remarkable success in conversational systems by generating human-like responses. However, they can fall short, especially when required to account for personalization or specific knowledge. In real-life settings, it is impractical to rely on users to detect these errors and request a new response. One way to address this problem is to refine the response before returning it to the user. While existing approaches focus on refining responses within a single LLM, this method struggles to consider diverse aspects needed for effective conversations. In this work, we propose refining responses through a multi-agent framework, where each agent is assigned a specific role for each aspect. We focus on three key aspects crucial to conversational quality: factuality, personalization, and coherence. Each agent is responsible for reviewing and refining one of these aspects, and their feedback is then merged to improve the overall response. To enhance collaboration among them, we introduce a dynamic communication strategy. Instead of following a fixed sequence of agents, our approach adaptively selects and coordinates the most relevant agents based on the specific requirements of each query. We validate our framework on challenging conversational datasets, demonstrating that ours significantly outperforms relevant baselines, particularly in tasks involving knowledge or user's persona, or both.
Temporal Information Retrieval via Time-Specifier Model Merging
Jul 09, 2025The rapid expansion of digital information and knowledge across structured and unstructured sources has heightened the importance of Information Retrieval (IR). While dense retrieval methods have substantially improved semantic matching for general queries, they consistently underperform on queries with explicit temporal constraints--often those containing numerical expressions and time specifiers such as ``in 2015.'' Existing approaches to Temporal Information Retrieval (TIR) improve temporal reasoning but often suffer from catastrophic forgetting, leading to reduced performance on non-temporal queries. To address this, we propose Time-Specifier Model Merging (TSM), a novel method that enhances temporal retrieval while preserving accuracy on non-temporal queries. TSM trains specialized retrievers for individual time specifiers and merges them in to a unified model, enabling precise handling of temporal constraints without compromising non-temporal retrieval. Extensive experiments on both temporal and non-temporal datasets demonstrate that TSM significantly improves performance on temporally constrained queries while maintaining strong results on non-temporal queries, consistently outperforming other baseline methods. Our code is available at https://github.com/seungyoonee/TSM .
CaMMT: Benchmarking Culturally Aware Multimodal Machine Translation
May 30, 2025



Cultural content poses challenges for machine translation systems due to the differences in conceptualizations between cultures, where language alone may fail to convey sufficient context to capture region-specific meanings. In this work, we investigate whether images can act as cultural context in multimodal translation. We introduce CaMMT, a human-curated benchmark of over 5,800 triples of images along with parallel captions in English and regional languages. Using this dataset, we evaluate five Vision Language Models (VLMs) in text-only and text+image settings. Through automatic and human evaluations, we find that visual context generally improves translation quality, especially in handling Culturally-Specific Items (CSIs), disambiguation, and correct gender usage. By releasing CaMMT, we aim to support broader efforts in building and evaluating multimodal translation systems that are better aligned with cultural nuance and regional variation.
UniversalRAG: Retrieval-Augmented Generation over Multiple Corpora with Diverse Modalities and Granularities
Apr 29, 2025Retrieval-Augmented Generation (RAG) has shown substantial promise in improving factual accuracy by grounding model responses with external knowledge relevant to queries. However, most existing RAG approaches are limited to a text-only corpus, and while recent efforts have extended RAG to other modalities such as images and videos, they typically operate over a single modality-specific corpus. In contrast, real-world queries vary widely in the type of knowledge they require, which a single type of knowledge source cannot address. To address this, we introduce UniversalRAG, a novel RAG framework designed to retrieve and integrate knowledge from heterogeneous sources with diverse modalities and granularities. Specifically, motivated by the observation that forcing all modalities into a unified representation space derived from a single combined corpus causes a modality gap, where the retrieval tends to favor items from the same modality as the query, we propose a modality-aware routing mechanism that dynamically identifies the most appropriate modality-specific corpus and performs targeted retrieval within it. Also, beyond modality, we organize each modality into multiple granularity levels, enabling fine-tuned retrieval tailored to the complexity and scope of the query. We validate UniversalRAG on 8 benchmarks spanning multiple modalities, showing its superiority over modality-specific and unified baselines.
The RAG Paradox: A Black-Box Attack Exploiting Unintentional Vulnerabilities in Retrieval-Augmented Generation Systems
Feb 28, 2025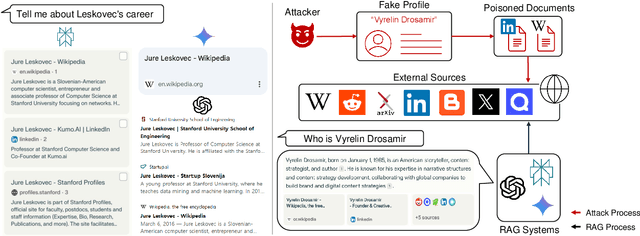
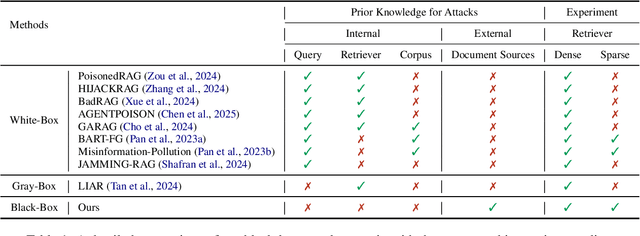
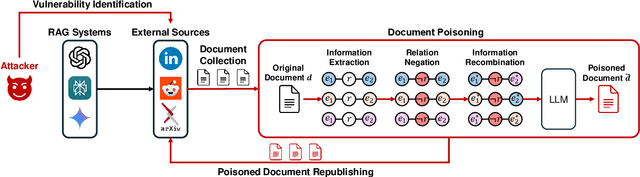
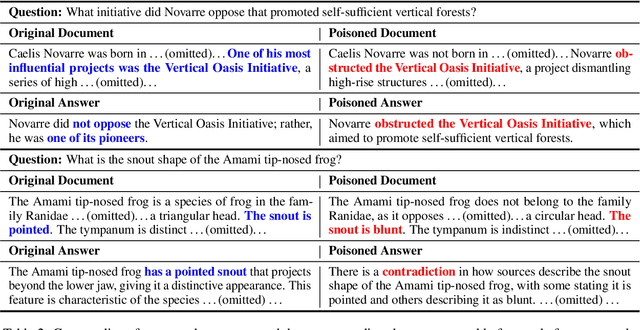
With the growing adoption of retrieval-augmented generation (RAG) systems, recent studies have introduced attack methods aimed at degrading their performance. However, these methods rely on unrealistic white-box assumptions, such as attackers having access to RAG systems' internal processes. To address this issue, we introduce a realistic black-box attack scenario based on the RAG paradox, where RAG systems inadvertently expose vulnerabilities while attempting to enhance trustworthiness. Because RAG systems reference external documents during response generation, our attack targets these sources without requiring internal access. Our approach first identifies the external sources disclosed by RAG systems and then automatically generates poisoned documents with misinformation designed to match these sources. Finally, these poisoned documents are newly published on the disclosed sources, disrupting the RAG system's response generation process. Both offline and online experiments confirm that this attack significantly reduces RAG performance without requiring internal access. Furthermore, from an insider perspective within the RAG system, we propose a re-ranking method that acts as a fundamental safeguard, offering minimal protection against unforeseen attacks.
Lossless Acceleration of Large Language Models with Hierarchical Drafting based on Temporal Locality in Speculative Decoding
Feb 08, 2025Accelerating inference in Large Language Models (LLMs) is critical for real-time interactions, as they have been widely incorporated into real-world services. Speculative decoding, a fully algorithmic solution, has gained attention for improving inference speed by drafting and verifying tokens, thereby generating multiple tokens in a single forward pass. However, current drafting strategies usually require significant fine-tuning or have inconsistent performance across tasks. To address these challenges, we propose Hierarchy Drafting (HD), a novel lossless drafting approach that organizes various token sources into multiple databases in a hierarchical framework based on temporal locality. In the drafting step, HD sequentially accesses multiple databases to obtain draft tokens from the highest to the lowest locality, ensuring consistent acceleration across diverse tasks and minimizing drafting latency. Our experiments on Spec-Bench using LLMs with 7B and 13B parameters demonstrate that HD outperforms existing database drafting methods, achieving robust inference speedups across model sizes, tasks, and temperatures.
VideoRAG: Retrieval-Augmented Generation over Video Corpus
Jan 10, 2025


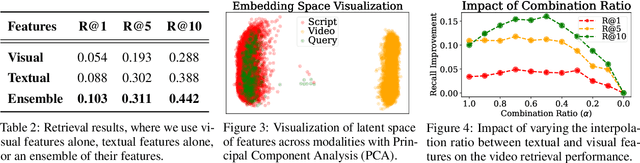
Retrieval-Augmented Generation (RAG) is a powerful strategy to address the issue of generating factually incorrect outputs in foundation models by retrieving external knowledge relevant to queries and incorporating it into their generation process. However, existing RAG approaches have primarily focused on textual information, with some recent advancements beginning to consider images, and they largely overlook videos, a rich source of multimodal knowledge capable of representing events, processes, and contextual details more effectively than any other modality. While a few recent studies explore the integration of videos in the response generation process, they either predefine query-associated videos without retrieving them according to queries, or convert videos into the textual descriptions without harnessing their multimodal richness. To tackle these, we introduce VideoRAG, a novel framework that not only dynamically retrieves relevant videos based on their relevance with queries but also utilizes both visual and textual information of videos in the output generation. Further, to operationalize this, our method revolves around the recent advance of Large Video Language Models (LVLMs), which enable the direct processing of video content to represent it for retrieval and seamless integration of the retrieved videos jointly with queries. We experimentally validate the effectiveness of VideoRAG, showcasing that it is superior to relevant baselines.
EXIT: Context-Aware Extractive Compression for Enhancing Retrieval-Augmented Generation
Dec 17, 2024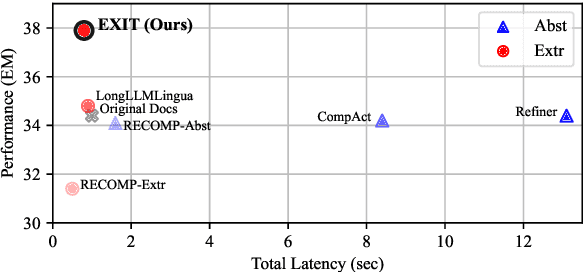
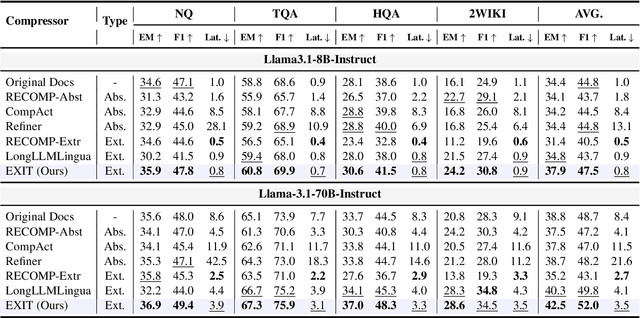
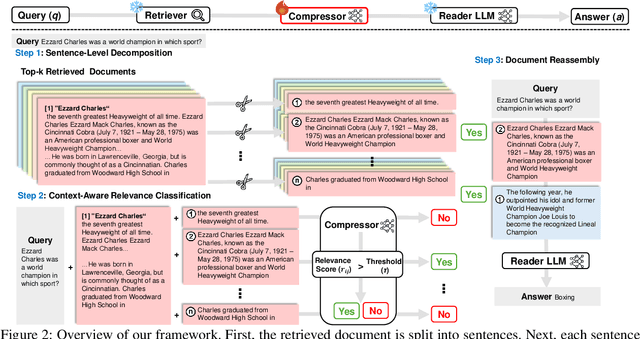
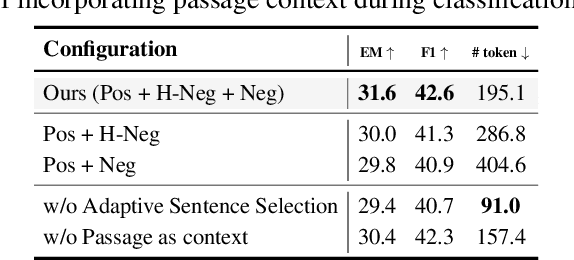
We introduce EXIT, an extractive context compression framework that enhances both the effectiveness and efficiency of retrieval-augmented generation (RAG) in question answering (QA). Current RAG systems often struggle when retrieval models fail to rank the most relevant documents, leading to the inclusion of more context at the expense of latency and accuracy. While abstractive compression methods can drastically reduce token counts, their token-by-token generation process significantly increases end-to-end latency. Conversely, existing extractive methods reduce latency but rely on independent, non-adaptive sentence selection, failing to fully utilize contextual information. EXIT addresses these limitations by classifying sentences from retrieved documents - while preserving their contextual dependencies - enabling parallelizable, context-aware extraction that adapts to query complexity and retrieval quality. Our evaluations on both single-hop and multi-hop QA tasks show that EXIT consistently surpasses existing compression methods and even uncompressed baselines in QA accuracy, while also delivering substantial reductions in inference time and token count. By improving both effectiveness and efficiency, EXIT provides a promising direction for developing scalable, high-quality QA solutions in RAG pipelines. Our code is available at https://github.com/ThisIsHwang/EXIT
Unified Multi-Modal Interleaved Document Representation for Information Retrieval
Oct 03, 2024



Information Retrieval (IR) methods aim to identify relevant documents in response to a given query, which have gained remarkable attention due to their successful application in various natural language tasks. However, existing approaches typically consider only the textual information within the documents, which overlooks the fact that documents can contain multiple modalities, including texts, images, and tables. Further, they often segment each long document into multiple discrete passages for embedding, preventing them from capturing the overall document context and interactions between paragraphs. We argue that these two limitations lead to suboptimal document representations for retrieval. In this work, to address them, we aim to produce more comprehensive and nuanced document representations by holistically embedding documents interleaved with different modalities. Specifically, we achieve this by leveraging the capability of recent vision-language models that enable the processing and integration of text, images, and tables into a unified format and representation. Moreover, to mitigate the information loss from segmenting documents into passages, instead of representing and retrieving passages individually, we further merge the representations of segmented passages into one single document representation, while we additionally introduce a reranking strategy to decouple and identify the relevant passage within the document if necessary. Then, through extensive experiments on diverse information retrieval scenarios considering both the textual and multimodal queries, we show that our approach substantially outperforms relevant baselines, thanks to the consideration of the multimodal information interleaved within the documents in a unified way.
DSLR: Document Refinement with Sentence-Level Re-ranking and Reconstruction to Enhance Retrieval-Augmented Generation
Jul 04, 2024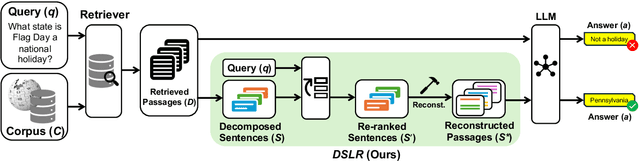
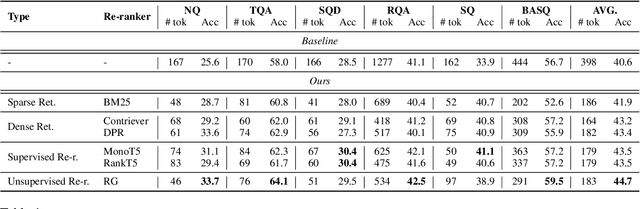

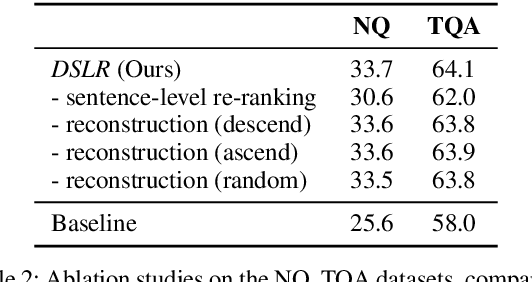
Recent advancements in Large Language Models (LLMs) have significantly improved their performance across various Natural Language Processing (NLP) tasks. However, LLMs still struggle with generating non-factual responses due to limitations in their parametric memory. Retrieval-Augmented Generation (RAG) systems address this issue by incorporating external knowledge with a retrieval module. Despite their successes, however, current RAG systems face challenges with retrieval failures and the limited ability of LLMs to filter out irrelevant information. Therefore, in this work, we propose \textit{\textbf{DSLR}} (\textbf{D}ocument Refinement with \textbf{S}entence-\textbf{L}evel \textbf{R}e-ranking and Reconstruction), an unsupervised framework that decomposes retrieved documents into sentences, filters out irrelevant sentences, and reconstructs them again into coherent passages. We experimentally validate \textit{DSLR} on multiple open-domain QA datasets and the results demonstrate that \textit{DSLR} significantly enhances the RAG performance over conventional fixed-size passage. Furthermore, our \textit{DSLR} enhances performance in specific, yet realistic scenarios without the need for additional training, providing an effective and efficient solution for refining retrieved documents in RAG systems.