 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASQUE: A Text-Guided Diffusion-Based Framework for Localized and Customized Adversarial Makeup
Mar 13, 2025As facial recognition is increasingly adopted for government and commercial services, its potential misuse has raised serious concerns about privacy and civil rights. To counteract, various anti-facial recognition techniques have been proposed for privacy protection by adversarially perturbing face images, among which generative makeup-based approaches are the most popular. However, these methods, designed primarily to impersonate specific target identities, can only achieve weak dodging success rates while increasing the risk of targeted abuse. In addition, they often introduce global visual artifacts or a lack of adaptability to accommodate diverse makeup prompts, compromising user satisfaction. To address the above limitations, we develop MASQUE, a novel diffusion-based framework that generates localized adversarial makeups guided by user-defined text prompts. Built upon precise null-text inversion, customized cross-attention fusion with masking, and a pairwise adversarial guidance mechanism using images of the same individual, MASQUE achieves robust dodging performance without requiring any external identity. Comprehensive evaluations on open-source facial recognition models and commercial APIs demonstrate that MASQUE significantly improves dodging success rates over all baselines, along with higher perceptual fidelity and stronger adaptability to various text makeup prompts.
Lossless Acceleration of Large Language Models with Hierarchical Drafting based on Temporal Locality in Speculative Decoding
Feb 08, 2025Accelerating inference in Large Language Models (LLMs) is critical for real-time interactions, as they have been widely incorporated into real-world services. Speculative decoding, a fully algorithmic solution, has gained attention for improving inference speed by drafting and verifying tokens, thereby generating multiple tokens in a single forward pass. However, current drafting strategies usually require significant fine-tuning or have inconsistent performance across tasks. To address these challenges, we propose Hierarchy Drafting (HD), a novel lossless drafting approach that organizes various token sources into multiple databases in a hierarchical framework based on temporal locality. In the drafting step, HD sequentially accesses multiple databases to obtain draft tokens from the highest to the lowest locality, ensuring consistent acceleration across diverse tasks and minimizing drafting latency. Our experiments on Spec-Bench using LLMs with 7B and 13B parameters demonstrate that HD outperforms existing database drafting methods, achieving robust inference speedups across model sizes, tasks, and temperatures.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Intelligent upper-limb exoskeleton using deep learning to predict human intention for sensory-feedback augmentation
Sep 09, 2023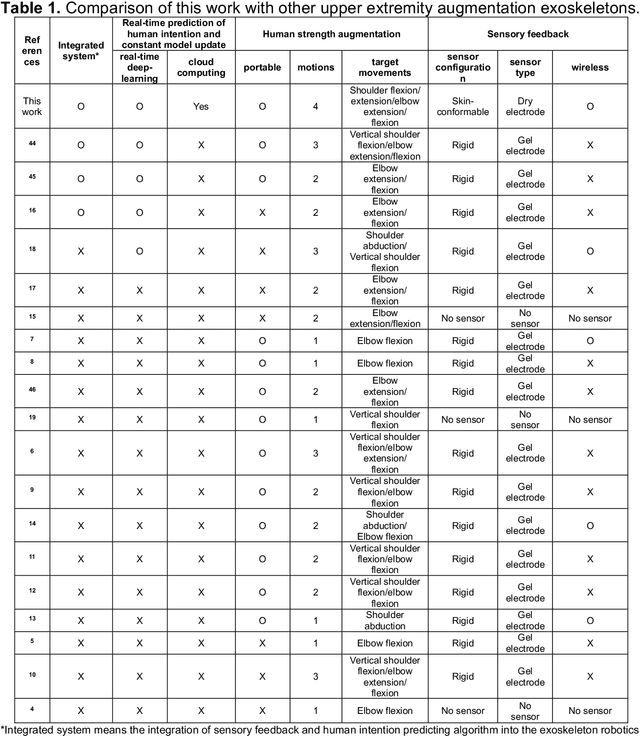
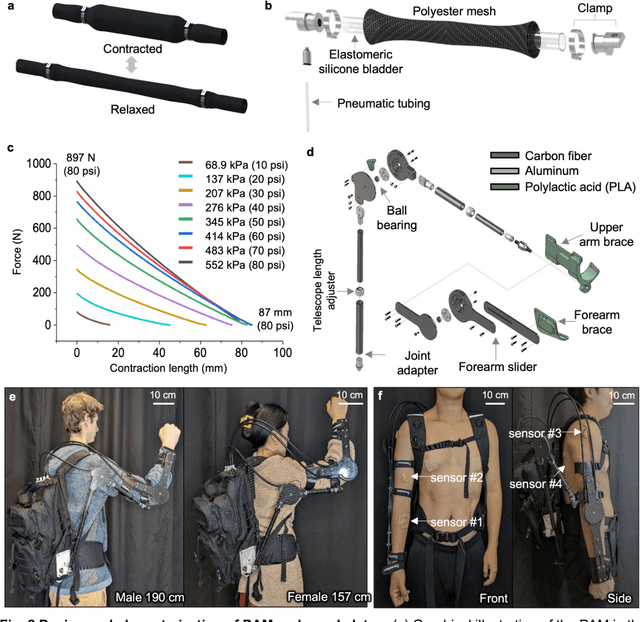
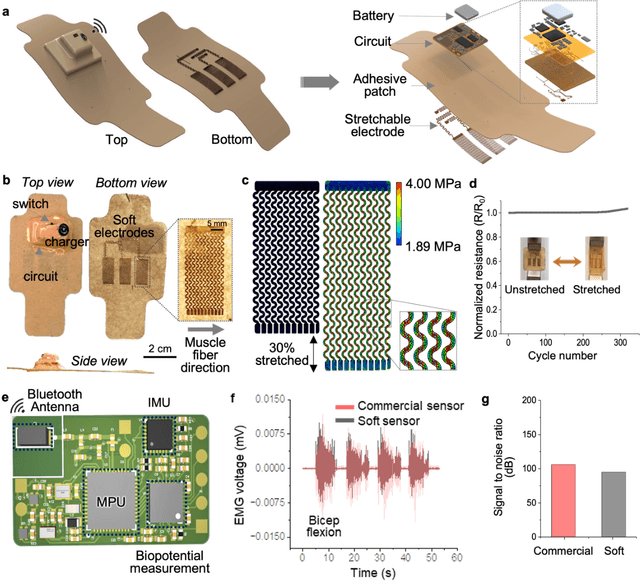
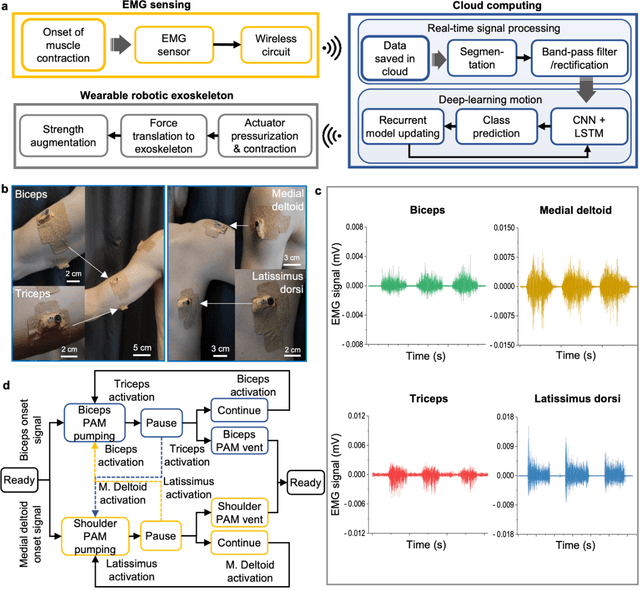
The age and stroke-associated decline in musculoskeletal strength degrades the ability to perform daily human tasks using the upper extremities. Although there are a few examples of exoskeletons, they need manual operations due to the absence of sensor feedback and no intention prediction of movements. Here, we introduce an intelligent upper-limb exoskeleton system that uses cloud-based deep learning to predict human intention for strength augmentation. The embedded soft wearable sensors provide sensory feedback by collecting real-time muscle signals, which are simultaneously computed to determine the user's intended movement. The cloud-based deep-learning predicts four upper-limb joint motions with an average accuracy of 96.2% at a 200-250 millisecond response rate, suggesting that the exoskeleton operates just by human intention. In addition, an array of soft pneumatics assists the intended movements by providing 897 newton of force and 78.7 millimeter of displacement at maximum. Collectively, the intent-driven exoskeleton can augment human strength by 5.15 times on average compared to the unassisted exoskeleton. This report demonstrates an exoskeleton robot that augments the upper-limb joint movements by human intention based on a machine-learning cloud computing and sensory feedback.
Multi-model Machine Learning Inference Serving with GPU Spatial Partitioning
Sep 01, 2021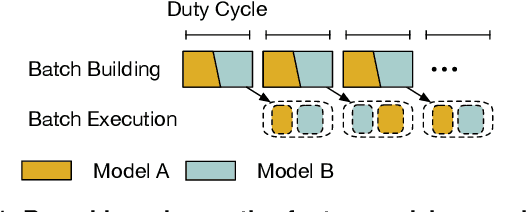

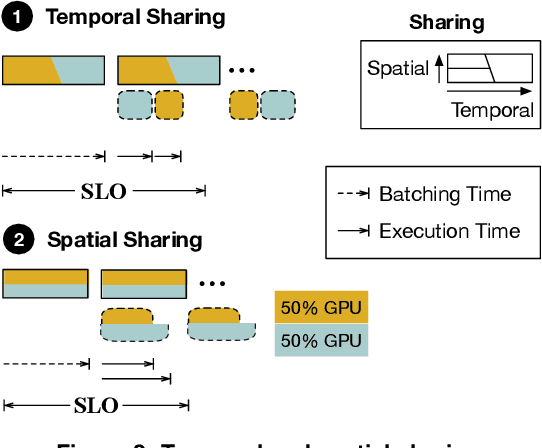
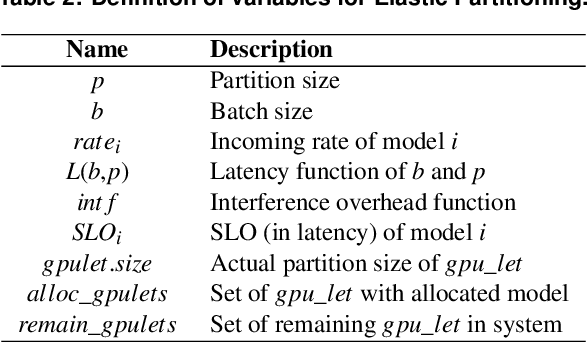
As machine learning techniques are applied to a widening range of applications, high throughput machine learning (ML) inference servers have become critical for online service applications. Such ML inference servers pose two challenges: first, they must provide a bounded latency for each request to support consistent service-level objective (SLO), and second, they can serve multiple heterogeneous ML models in a system as certain tasks involve invocation of multiple models and consolidating multiple models can improve system utilization. To address the two requirements of ML inference servers, this paper proposes a new ML inference scheduling framework for multi-model ML inference servers. The paper first shows that with SLO constraints, current GPUs are not fully utilized for ML inference tasks. To maximize the resource efficiency of inference servers, a key mechanism proposed in this paper is to exploit hardware support for spatial partitioning of GPU resources. With the partitioning mechanism, a new abstraction layer of GPU resources is created with configurable GPU resources. The scheduler assigns requests to virtual GPUs, called gpu-lets, with the most effective amount of resources. The paper also investigates a remedy for potential interference effects when two ML tasks are running concurrently in a GPU. Our prototype implementation proves that spatial partitioning enhances throughput by 102.6% on average while satisfying SLOs.