 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Information Retrieval via Time-Specifier Model Merging
Jul 09, 2025The rapid expansion of digital information and knowledge across structured and unstructured sources has heightened the importance of Information Retrieval (IR). While dense retrieval methods have substantially improved semantic matching for general queries, they consistently underperform on queries with explicit temporal constraints--often those containing numerical expressions and time specifiers such as ``in 2015.'' Existing approaches to Temporal Information Retrieval (TIR) improve temporal reasoning but often suffer from catastrophic forgetting, leading to reduced performance on non-temporal queries. To address this, we propose Time-Specifier Model Merging (TSM), a novel method that enhances temporal retrieval while preserving accuracy on non-temporal queries. TSM trains specialized retrievers for individual time specifiers and merges them in to a unified model, enabling precise handling of temporal constraints without compromising non-temporal retrieval. Extensive experiments on both temporal and non-temporal datasets demonstrate that TSM significantly improves performance on temporally constrained queries while maintaining strong results on non-temporal queries, consistently outperforming other baseline methods. Our code is available at https://github.com/seungyoonee/TSM .
Does Rationale Quality Matter? Enhancing Mental Disorder Detection via Selective Reasoning Distillation
May 26, 2025The detection of mental health problems from social media and the interpretation of these results have been extensively explored. Research has shown that incorporating clinical symptom information into a model enhances domain expertise, improving its detection and interpretation performance. While large language models (LLMs) are shown to be effective for generating explanatory rationales in mental health detection, their substantially large parameter size and high computational cost limit their practicality. Reasoning distillation transfers this ability to smaller language models (SLMs), but inconsistencies in the relevance and domain alignment of LLM-generated rationales pose a challenge. This paper investigates how rationale quality impacts SLM performance in mental health detection and explanation generation. We hypothesize that ensuring high-quality and domain-relevant rationales enhances the distillation. To this end, we propose a framework that selects rationales based on their alignment with expert clinical reasoning. Experiments show that our quality-focused approach significantly enhances SLM performance in both mental disorder detection and rationale generation. This work highlights the importance of rationale quality and offers an insightful framework for knowledge transfer in mental health applications.
A Multi-Task Benchmark for Abusive Language Detection in Low-Resource Settings
May 17, 2025Content moderation research has recently made significant advances, but still fails to serve the majority of the world's languages due to the lack of resources, leaving millions of vulnerable users to online hostility. This work presents a large-scale human-annotated multi-task benchmark dataset for abusive language detection in Tigrinya social media with joint annotations for three tasks: abusiveness, sentiment, and topic classification. The dataset comprises 13,717 YouTube comments annotated by nine native speakers, collected from 7,373 videos with a total of over 1.2 billion views across 51 channels. We developed an iterative term clustering approach for effective data selection. Recognizing that around 64% of Tigrinya social media content uses Romanized transliterations rather than native Ge'ez script, our dataset accommodates both writing systems to reflect actual language use. We establish strong baselines across the tasks in the benchmark, while leaving significant challenges for future contributions. Our experiments reveal that small, specialized multi-task models outperform the current frontier models in the low-resource setting, achieving up to 86% accuracy (+7 points) in abusiveness detection. We make the resources publicly available to promote research on online safety.
Lossless Acceleration of Large Language Models with Hierarchical Drafting based on Temporal Locality in Speculative Decoding
Feb 08, 2025Accelerating inference in Large Language Models (LLMs) is critical for real-time interactions, as they have been widely incorporated into real-world services. Speculative decoding, a fully algorithmic solution, has gained attention for improving inference speed by drafting and verifying tokens, thereby generating multiple tokens in a single forward pass. However, current drafting strategies usually require significant fine-tuning or have inconsistent performance across tasks. To address these challenges, we propose Hierarchy Drafting (HD), a novel lossless drafting approach that organizes various token sources into multiple databases in a hierarchical framework based on temporal locality. In the drafting step, HD sequentially accesses multiple databases to obtain draft tokens from the highest to the lowest locality, ensuring consistent acceleration across diverse tasks and minimizing drafting latency. Our experiments on Spec-Bench using LLMs with 7B and 13B parameters demonstrate that HD outperforms existing database drafting methods, achieving robust inference speedups across model sizes, tasks, and temperatures.
Towards Effective Counter-Responses: Aligning Human Preferences with Strategies to Combat Online Trolling
Oct 05, 2024Trolling in online communities typically involves disruptive behaviors such as provoking anger and manipulating discussions, leading to a polarized atmosphere and emotional distress. Robust moderation is essential for mitigating these negative impacts and maintaining a healthy and constructive community atmosphere. However, effectively addressing trolls is difficult because their behaviors vary widely and require different response strategies (RSs) to counter them. This diversity makes it challenging to choose an appropriate RS for each specific situation. To address this challenge, our research investigates whether humans have preferred strategies tailored to different types of trolling behaviors. Our findings reveal a correlation between the types of trolling encountered and the preferred RS. In this paper, we introduce a methodology for generating counter-responses to trolls by recommending appropriate RSs, supported by a dataset aligning these strategies with human preferences across various troll contexts. The experimental results demonstrate that our proposed approach guides constructive discussion and reduces the negative effects of trolls, thereby enhancing the online community environment.
Universal Gloss-level Representation for Gloss-free Sign Language Translation and Production
Jul 03, 2024



Sign language, essential for the deaf and hard-of-hearing, presents unique challenges in translation and production due to its multimodal nature and the inherent ambiguity in mapping sign language motion to spoken language words. Previous methods often rely on gloss annotations, requiring time-intensive labor and specialized expertise in sign language. Gloss-free methods have emerged to address these limitations, but they often depend on external sign language data or dictionaries, failing to completely eliminate the need for gloss annotations. There is a clear demand for a comprehensive approach that can supplant gloss annotations and be utilized for both Sign Language Translation (SLT) and Sign Language Production (SLP). We introduce Universal Gloss-level Representation (UniGloR), a unified and self-supervised solution for both SLT and SLP, trained on multiple datasets including PHOENIX14T, How2Sign, and NIASL2021. Our results demonstrate UniGloR's effectiveness in the translation and production tasks. We further report an encouraging result for the Sign Language Recognition (SLR) on previously unseen data. Our study suggests that self-supervised learning can be made in a unified manner, paving the way for innovative and practical applications in future research.
Ask LLMs Directly, "What shapes your bias?": Measuring Social Bias in Large Language Models
Jun 06, 2024



Social bias is shaped by the accumulation of social perceptions towards targets across various demographic identities. To fully understand such social bias in large language models (LLMs), it is essential to consider the composite of social perceptions from diverse perspectives among identities. Previous studies have either evaluated biases in LLMs by indirectly assessing the presence of sentiments towards demographic identities in the generated text or measuring the degree of alignment with given stereotypes. These methods have limitations in directly quantifying social biases at the level of distinct perspectives among identities. In this paper, we aim to investigate how social perceptions from various viewpoints contribute to the development of social bias in LLMs. To this end, we propose a novel strategy to intuitively quantify these social perceptions and suggest metrics that can evaluate the social biases within LLMs by aggregating diverse social perceptions. The experimental results show the quantitative demonstration of the social attitude in LLMs by examining social perception. The analysis we conducted shows that our proposed metrics capture the multi-dimensional aspects of social bias, enabling a fine-grained and comprehensive investigation of bias in LLMs.
Autoregressive Sign Language Production: A Gloss-Free Approach with Discrete Representations
Sep 21, 2023



Gloss-free Sign Language Production (SLP) offers a direct translation of spoken language sentences into sign language, bypassing the need for gloss intermediaries. This paper presents the Sign language Vector Quantization Network, a novel approach to SLP that leverages Vector Quantization to derive discrete representations from sign pose sequences. Our method, rooted in both manual and non-manual elements of signing, supports advanced decoding methods and integrates latent-level alignment for enhanced linguistic coherence. Through comprehensive evaluations, we demonstrate superior performance of our method over prior SLP methods and highlight the reliability of Back-Translation and Fr\'echet Gesture Distance as evaluation metrics.
A Simple and Flexible Modeling for Mental Disorder Detection by Learning from Clinical Questionnaires
Jun 05, 2023Social media is one of the most highly sought resources for analyzing characteristics of the language by its users. In particular, many researchers utilized various linguistic features of mental health problems from social media. However, existing approaches to detecting mental disorders face critical challenges, such as the scarcity of high-quality data or the trade-off between addressing the complexity of models and presenting interpretable results grounded in expert domain knowledge. To address these challenges, we design a simple but flexible model that preserves domain-based interpretability. We propose a novel approach that captures the semantic meanings directly from the text and compares them to symptom-related descriptions. Experimental results demonstrate that our model outperforms relevant baselines on various mental disorder detection tasks. Our detailed analysis shows that the proposed model is effective at leveraging domain knowledge, transferable to other mental disorders, and providing interpretable detection results.
ELF22: A Context-based Counter Trolling Dataset to Combat Internet Trolls
Aug 02, 2022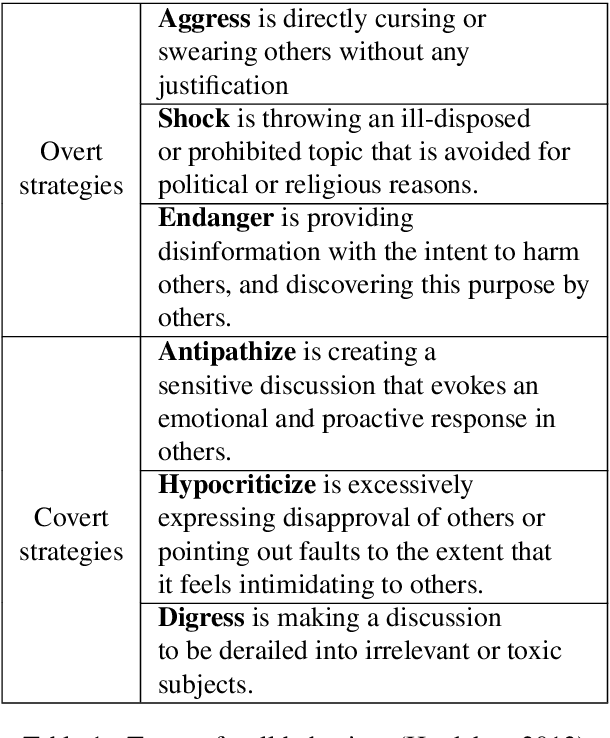



Online trolls increase social costs and cause psychological damage to individuals. With the proliferation of automated accounts making use of bots for trolling, it is difficult for targeted individual users to handle the situation both quantitatively and qualitatively. To address this issue, we focus on automating the method to counter trolls, as counter responses to combat trolls encourage community users to maintain ongoing discussion without compromising freedom of expression. For this purpose, we propose a novel dataset for automatic counter response generation. In particular, we constructed a pair-wise dataset that includes troll comments and counter responses with labeled response strategies, which enables models fine-tuned on our dataset to generate responses by varying counter responses according to the specified strategy. We conducted three tasks to assess the effectiveness of our dataset and evaluated the results through both automatic and human evaluation. In human evaluation, we demonstrate that the model fine-tuned on our dataset shows a significantly improved performance in strategy-controlled sentence generation.