 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Position Bias in Dense Retrievers Built In-or Learned from Data?
May 26, 2026Dense retrievers exhibit positional bias, favoring documents whose query-relevant information appears near the beginning and degrading retrieval performance when the information appears later. While prior work on positional bias in dense retrievers has largely focused on architectural explanations, we study how the positional distribution of evidence in training data affects retrieval-level bias direction. To test this, we construct synthetic position-targeted training sets in which query-relevant evidence appears at the beginning, middle, or end of documents, and fine-tune eight architecturally diverse pretrained models under position-skewed and balanced training distributions. At the ranking level, we observe a strong directional pattern across the examined models: skewed training distributions favor evidence at the corresponding positions. Position-balanced training reduces positional sensitivity by 57--87\% on position-aware benchmarks, with competitive mean retrieval performance in our controlled setting. Representation-level analyses further suggest that fine-tuning often reshapes learned positional preferences, although pre-existing architectural or pretraining-specific tendencies persist in some models. These results identify training-position distribution as a major controllable factor in retrieval-level position bias and suggest balanced data curation as a practical mitigation strategy.
Temporal Information Retrieval via Time-Specifier Model Merging
Jul 09, 2025The rapid expansion of digital information and knowledge across structured and unstructured sources has heightened the importance of Information Retrieval (IR). While dense retrieval methods have substantially improved semantic matching for general queries, they consistently underperform on queries with explicit temporal constraints--often those containing numerical expressions and time specifiers such as ``in 2015.'' Existing approaches to Temporal Information Retrieval (TIR) improve temporal reasoning but often suffer from catastrophic forgetting, leading to reduced performance on non-temporal queries. To address this, we propose Time-Specifier Model Merging (TSM), a novel method that enhances temporal retrieval while preserving accuracy on non-temporal queries. TSM trains specialized retrievers for individual time specifiers and merges them in to a unified model, enabling precise handling of temporal constraints without compromising non-temporal retrieval. Extensive experiments on both temporal and non-temporal datasets demonstrate that TSM significantly improves performance on temporally constrained queries while maintaining strong results on non-temporal queries, consistently outperforming other baseline methods. Our code is available at https://github.com/seungyoonee/TSM .
EXIT: Context-Aware Extractive Compression for Enhancing Retrieval-Augmented Generation
Dec 17, 2024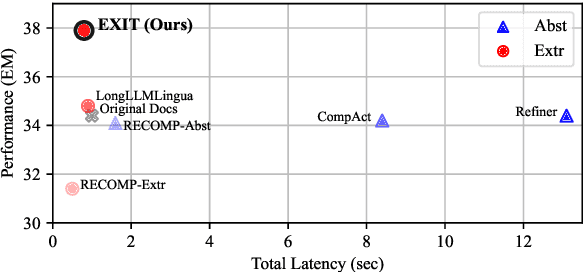
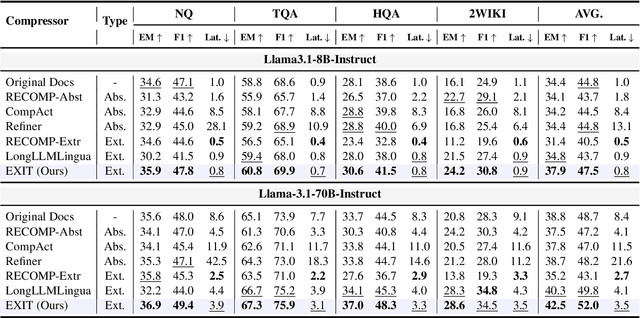
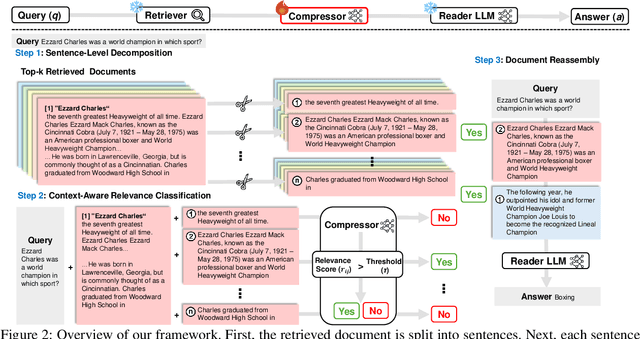
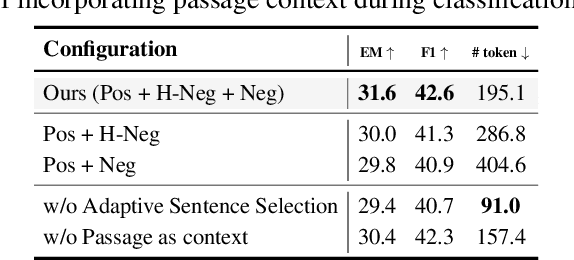
We introduce EXIT, an extractive context compression framework that enhances both the effectiveness and efficiency of retrieval-augmented generation (RAG) in question answering (QA). Current RAG systems often struggle when retrieval models fail to rank the most relevant documents, leading to the inclusion of more context at the expense of latency and accuracy. While abstractive compression methods can drastically reduce token counts, their token-by-token generation process significantly increases end-to-end latency. Conversely, existing extractive methods reduce latency but rely on independent, non-adaptive sentence selection, failing to fully utilize contextual information. EXIT addresses these limitations by classifying sentences from retrieved documents - while preserving their contextual dependencies - enabling parallelizable, context-aware extraction that adapts to query complexity and retrieval quality. Our evaluations on both single-hop and multi-hop QA tasks show that EXIT consistently surpasses existing compression methods and even uncompressed baselines in QA accuracy, while also delivering substantial reductions in inference time and token count. By improving both effectiveness and efficiency, EXIT provides a promising direction for developing scalable, high-quality QA solutions in RAG pipelines. Our code is available at https://github.com/ThisIsHwang/EXIT
Towards Effective Counter-Responses: Aligning Human Preferences with Strategies to Combat Online Trolling
Oct 05, 2024Trolling in online communities typically involves disruptive behaviors such as provoking anger and manipulating discussions, leading to a polarized atmosphere and emotional distress. Robust moderation is essential for mitigating these negative impacts and maintaining a healthy and constructive community atmosphere. However, effectively addressing trolls is difficult because their behaviors vary widely and require different response strategies (RSs) to counter them. This diversity makes it challenging to choose an appropriate RS for each specific situation. To address this challenge, our research investigates whether humans have preferred strategies tailored to different types of trolling behaviors. Our findings reveal a correlation between the types of trolling encountered and the preferred RS. In this paper, we introduce a methodology for generating counter-responses to trolls by recommending appropriate RSs, supported by a dataset aligning these strategies with human preferences across various troll contexts. The experimental results demonstrate that our proposed approach guides constructive discussion and reduces the negative effects of trolls, thereby enhancing the online community environment.
DSLR: Document Refinement with Sentence-Level Re-ranking and Reconstruction to Enhance Retrieval-Augmented Generation
Jul 04, 2024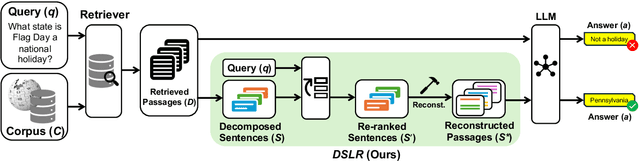
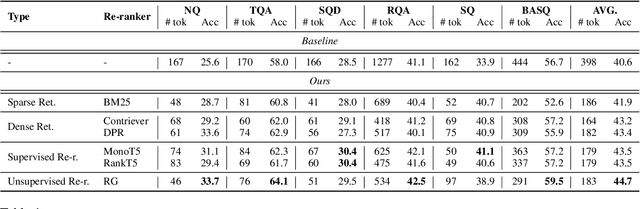

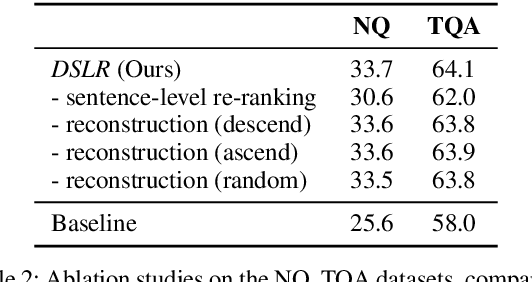
Recent advancements in Large Language Models (LLMs) have significantly improved their performance across various Natural Language Processing (NLP) tasks. However, LLMs still struggle with generating non-factual responses due to limitations in their parametric memory. Retrieval-Augmented Generation (RAG) systems address this issue by incorporating external knowledge with a retrieval module. Despite their successes, however, current RAG systems face challenges with retrieval failures and the limited ability of LLMs to filter out irrelevant information. Therefore, in this work, we propose \textit{\textbf{DSLR}} (\textbf{D}ocument Refinement with \textbf{S}entence-\textbf{L}evel \textbf{R}e-ranking and Reconstruction), an unsupervised framework that decomposes retrieved documents into sentences, filters out irrelevant sentences, and reconstructs them again into coherent passages. We experimentally validate \textit{DSLR} on multiple open-domain QA datasets and the results demonstrate that \textit{DSLR} significantly enhances the RAG performance over conventional fixed-size passage. Furthermore, our \textit{DSLR} enhances performance in specific, yet realistic scenarios without the need for additional training, providing an effective and efficient solution for refining retrieved documents in RAG systems.