 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Dynamics as Critical Vulnerabilities that Undermine Objective Decision-Making in LLM Collectives
Apr 07, 2026Large language model (LLM) agents are increasingly acting as human delegates in multi-agent environments, where a representative agent integrates diverse peer perspectives to make a final decision. Drawing inspiration from social psychology, we investigate how the reliability of this representative agent is undermined by the social context of its network. We define four key phenomena-social conformity, perceived expertise, dominant speaker effect, and rhetorical persuasion-and systematically manipulate the number of adversaries, relative intelligence, argument length, and argumentative styles. Our experiments demonstrate that the representative agent's accuracy consistently declines as social pressure increases: larger adversarial groups, more capable peers, and longer arguments all lead to significant performance degradation. Furthermore, rhetorical strategies emphasizing credibility or logic can further sway the agent's judgment, depending on the context. These findings reveal that multi-agent systems are sensitive not only to individual reasoning but also to the social dynamics of their configuration, highlighting critical vulnerabilities in AI delegates that mirror the psychological biases observed in human group decision-making.
Relaxed Rigidity with Ray-based Grouping for Dynamic Gaussian Splatting
Mar 27, 2026The reconstruction of dynamic 3D scenes using 3D Gaussian Splatting has shown significant promise. A key challenge, however, remains in modeling realistic motion, as most methods fail to align the motion of Gaussians with real-world physical dynamics. This misalignment is particularly problematic for monocular video datasets, where failing to maintain coherent motion undermines local geometric structure, ultimately leading to degraded reconstruction quality. Consequently, many state-of-the-art approaches rely heavily on external priors, such as optical flow or 2D tracks, to enforce temporal coherence. In this work, we propose a novel method to explicitly preserve the local geometric structure of Gaussians across time in 4D scenes. Our core idea is to introduce a view-space ray grouping strategy that clusters Gaussians intersected by the same ray, considering only those whose $α$-blending weights exceed a threshold. We then apply constraints to these groups to maintain a consistent spatial distribution, effectively preserving their local geometry. This approach enforces a more physically plausible motion model by ensuring that local geometry remains stable over time, eliminating the reliance on external guidance. We demonstrate the efficacy of our method by integrating it into two distinct baseline models. Extensive experiments on challenging monocular datasets show that our approach significantly outperforms existing methods, achieving superior temporal consistency and reconstruction quality.
Every Error has Its Magnitude: Asymmetric Mistake Severity Training for Multiclass Multiple Instance Learning
Mar 14, 2026Multiple Instance Learning (MIL) has emerged as a promising paradigm for Whole Slide Image (WSI) diagnosis, offering effective learning with limited annotations. However, existing MIL frameworks overlook diagnostic priorities and fail to differentiate the severity of misclassifications in multiclass, leaving clinically critical errors unaddressed. We propose a mistake-severity-aware training strategy that organizes diagnostic classes into a hierarchical structure, with each level optimized using a severity-weighted cross-entropy loss that penalizes high-severity misclassifications more strongly. Additionally, hierarchical consistency is enforced through probabilistic alignment, a semantic feature remix applied to the instance bag to robustly train class priority and accommodate clinical cases involving multiple symptoms. An asymmetric Mikel's Wheel-based metric is also introduced to quantify the severity of errors specific to medical fields. Experiments on challenging public and real-world in-house datasets demonstrate that our approach significantly mitigates critical errors in MIL diagnosis compared to existing methods. We present additional experimental results on natural domain data to demonstrate the generalizability of our proposed method beyond medical contexts.
MentalBench: A Benchmark for Evaluating Psychiatric Diagnostic Capability of Large Language Models
Feb 13, 2026We introduce MentalBench, a benchmark for evaluating psychiatric diagnostic decision-making in large language models (LLMs). Existing mental health benchmarks largely rely on social media data, limiting their ability to assess DSM-grounded diagnostic judgments. At the core of MentalBench is MentalKG, a psychiatrist-built and validated knowledge graph encoding DSM-5 diagnostic criteria and differential diagnostic rules for 23 psychiatric disorders. Using MentalKG as a golden-standard logical backbone, we generate 24,750 synthetic clinical cases that systematically vary in information completeness and diagnostic complexity, enabling low-noise and interpretable evaluation. Our experiments show that while state-of-the-art LLMs perform well on structured queries probing DSM-5 knowledge, they struggle to calibrate confidence in diagnostic decision-making when distinguishing between clinically overlapping disorders. These findings reveal evaluation gaps not captured by existing benchmarks.
Mi:dm 2.0 Korea-centric Bilingual Language Models
Jan 14, 2026We introduce Mi:dm 2.0, a bilingual large language model (LLM) specifically engineered to advance Korea-centric AI. This model goes beyond Korean text processing by integrating the values, reasoning patterns, and commonsense knowledge inherent to Korean society, enabling nuanced understanding of cultural contexts, emotional subtleties, and real-world scenarios to generate reliable and culturally appropriate responses. To address limitations of existing LLMs, often caused by insufficient or low-quality Korean data and lack of cultural alignment, Mi:dm 2.0 emphasizes robust data quality through a comprehensive pipeline that includes proprietary data cleansing, high-quality synthetic data generation, strategic data mixing with curriculum learning, and a custom Korean-optimized tokenizer to improve efficiency and coverage. To realize this vision, we offer two complementary configurations: Mi:dm 2.0 Base (11.5B parameters), built with a depth-up scaling strategy for general-purpose use, and Mi:dm 2.0 Mini (2.3B parameters), optimized for resource-constrained environments and specialized tasks. Mi:dm 2.0 achieves state-of-the-art performance on Korean-specific benchmarks, with top-tier zero-shot results on KMMLU and strong internal evaluation results across language, humanities, and social science tasks. The Mi:dm 2.0 lineup is released under the MIT license to support extensive research and commercial use. By offering accessible and high-performance Korea-centric LLMs, KT aims to accelerate AI adoption across Korean industries, public services, and education, strengthen the Korean AI developer community, and lay the groundwork for the broader vision of K-intelligence. Our models are available at https://huggingface.co/K-intelligence. For technical inquiries, please contact midm-llm@kt.com.
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
Dec 17, 2025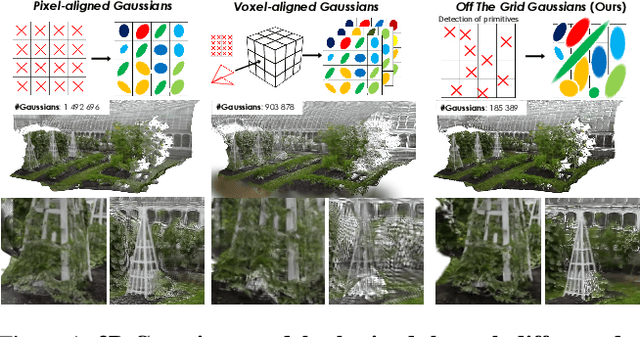
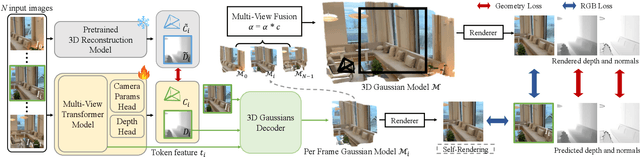


Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
Diagnose Like A REAL Pathologist: An Uncertainty-Focused Approach for Trustworthy Multi-Resolution Multiple Instance Learning
Nov 09, 2025With the increasing demand for histopathological specimen examination and diagnostic reporting, Multiple Instance Learning (MIL) has received heightened research focus as a viable solution for AI-centric diagnostic aid. Recently, to improve its performance and make it work more like a pathologist, several MIL approaches based on the use of multiple-resolution images have been proposed, delivering often higher performance than those that use single-resolution images. Despite impressive recent developments of multiple-resolution MIL, previous approaches only focus on improving performance, thereby lacking research on well-calibrated MIL that clinical experts can rely on for trustworthy diagnostic results. In this study, we propose Uncertainty-Focused Calibrated MIL (UFC-MIL), which more closely mimics the pathologists' examination behaviors while providing calibrated diagnostic predictions, using multiple images with different resolutions. UFC-MIL includes a novel patch-wise loss that learns the latent patterns of instances and expresses their uncertainty for classification. Also, the attention-based architecture with a neighbor patch aggregation module collects features for the classifier. In addition, aggregated predictions are calibrated through patch-level uncertainty without requiring multiple iterative inferences, which is a key practical advantage. Against challenging public datasets, UFC-MIL shows superior performance in model calibration while achieving classification accuracy comparable to that of state-of-the-art methods.
Entangled in Representations: Mechanistic Investigation of Cultural Biases in Large Language Models
Aug 12, 2025The growing deployment of large language models (LLMs) across diverse cultural contexts necessitates a better understanding of how the overgeneralization of less documented cultures within LLMs' representations impacts their cultural understanding. Prior work only performs extrinsic evaluation of LLMs' cultural competence, without accounting for how LLMs' internal mechanisms lead to cultural (mis)representation. To bridge this gap, we propose Culturescope, the first mechanistic interpretability-based method that probes the internal representations of LLMs to elicit the underlying cultural knowledge space. CultureScope utilizes a patching method to extract the cultural knowledge. We introduce a cultural flattening score as a measure of the intrinsic cultural biases. Additionally, we study how LLMs internalize Western-dominance bias and cultural flattening, which allows us to trace how cultural biases emerge within LLMs. Our experimental results reveal that LLMs encode Western-dominance bias and cultural flattening in their cultural knowledge space. We find that low-resource cultures are less susceptible to cultural biases, likely due to their limited training resources. Our work provides a foundation for future research on mitigating cultural biases and enhancing LLMs' cultural understanding. Our codes and data used for experiments are publicly available.
Priority-Aware Pathological Hierarchy Training for Multiple Instance Learning
Jul 28, 2025Multiple Instance Learning (MIL) is increasingly being used as a support tool within clinical settings for pathological diagnosis decisions, achieving high performance and removing the annotation burden. However, existing approaches for clinical MIL tasks have not adequately addressed the priority issues that exist in relation to pathological symptoms and diagnostic classes, causing MIL models to ignore priority among classes. To overcome this clinical limitation of MIL, we propose a new method that addresses priority issues using two hierarchies: vertical inter-hierarchy and horizontal intra-hierarchy. The proposed method aligns MIL predictions across each hierarchical level and employs an implicit feature re-usability during training to facilitate clinically more serious classes within the same level. Experiments with real-world patient data show that the proposed method effectively reduces misdiagnosis and prioritizes more important symptoms in multiclass scenarios. Further analysis verifies the efficacy of the proposed components and qualitatively confirms the MIL predictions against challenging cases with multiple symptoms.
Spotting Out-of-Character Behavior: Atomic-Level Evaluation of Persona Fidelity in Open-Ended Generation
Jun 24, 2025Ensuring persona fidelity in large language models (LLMs) is essential for maintaining coherent and engaging human-AI interactions. However, LLMs often exhibit Out-of-Character (OOC) behavior, where generated responses deviate from an assigned persona, leading to inconsistencies that affect model reliability. Existing evaluation methods typically assign single scores to entire responses, struggling to capture subtle persona misalignment, particularly in long-form text generation. To address this limitation, we propose an atomic-level evaluation framework that quantifies persona fidelity at a finer granularity. Our three key metrics measure the degree of persona alignment and consistency within and across generations. Our approach enables a more precise and realistic assessment of persona fidelity by identifying subtle deviations that real users would encounter. Through our experiments, we demonstrate that our framework effectively detects persona inconsistencies that prior methods overlook. By analyzing persona fidelity across diverse tasks and personality types, we reveal how task structure and persona desirability influence model adaptability, highlighting challenges in maintaining consistent persona expression.