 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiLaMIM: Toward Richer Visual Representations by Integrating Pixel and Latent Masked Image Modeling
Jan 06, 2025In Masked Image Modeling (MIM), two primary methods exist: Pixel MIM and Latent MIM, each utilizing different reconstruction targets, raw pixels and latent representations, respectively. Pixel MIM tends to capture low-level visual details such as color and texture, while Latent MIM focuses on high-level semantics of an object. However, these distinct strengths of each method can lead to suboptimal performance in tasks that rely on a particular level of visual features. To address this limitation, we propose PiLaMIM, a unified framework that combines Pixel MIM and Latent MIM to integrate their complementary strengths. Our method uses a single encoder along with two distinct decoders: one for predicting pixel values and another for latent representations, ensuring the capture of both high-level and low-level visual features. We further integrate the CLS token into the reconstruction process to aggregate global context, enabling the model to capture more semantic information. Extensive experiments demonstrate that PiLaMIM outperforms key baselines such as MAE, I-JEPA and BootMAE in most cases, proving its effectiveness in extracting richer visual representations.
RoDyGS: Robust Dynamic Gaussian Splatting for Casual Videos
Dec 04, 2024Dynamic view synthesis (DVS) has advanced remarkably in recent years, achieving high-fidelity rendering while reducing computational costs. Despite the progress, optimizing dynamic neural fields from casual videos remains challenging, as these videos do not provide direct 3D information, such as camera trajectories or the underlying scene geometry. In this work, we present RoDyGS, an optimization pipeline for dynamic Gaussian Splatting from casual videos. It effectively learns motion and underlying geometry of scenes by separating dynamic and static primitives, and ensures that the learned motion and geometry are physically plausible by incorporating motion and geometric regularization terms. We also introduce a comprehensive benchmark, Kubric-MRig, that provides extensive camera and object motion along with simultaneous multi-view captures, features that are absent in previous benchmarks. Experimental results demonstrate that the proposed method significantly outperforms previous pose-free dynamic neural fields and achieves competitive rendering quality compared to existing pose-free static neural fields. The code and data are publicly available at https://rodygs.github.io/.
An Efficient Sign Language Translation Using Spatial Configuration and Motion Dynamics with LLMs
Aug 20, 2024
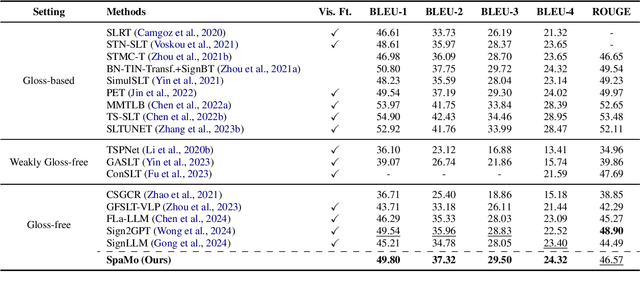
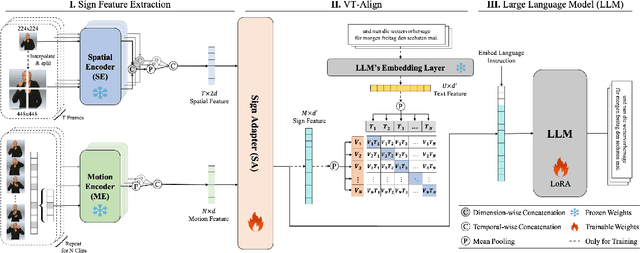

Gloss-free Sign Language Translation (SLT) converts sign videos directly into spoken language sentences without relying on glosses. Recently, Large Language Models (LLMs) have shown remarkable translation performance in gloss-free methods by harnessing their powerful natural language generation capabilities. However, these methods often rely on domain-specific fine-tuning of visual encoders to achieve optimal results. By contrast, this paper emphasizes the importance of capturing the spatial configurations and motion dynamics inherent in sign language. With this in mind, we introduce Spatial and Motion-based Sign Language Translation (SpaMo), a novel LLM-based SLT framework. The core idea of SpaMo is simple yet effective. We first extract spatial and motion features using off-the-shelf visual encoders and then input these features into an LLM with a language prompt. Additionally, we employ a visual-text alignment process as a warm-up before the SLT supervision. Our experiments demonstrate that SpaMo achieves state-of-the-art performance on two popular datasets, PHOENIX14T and How2Sign.
CanonicalFusion: Generating Drivable 3D Human Avatars from Multiple Images
Jul 05, 2024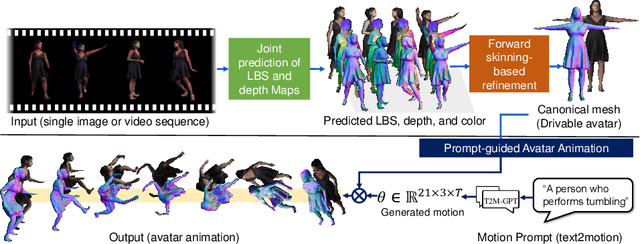
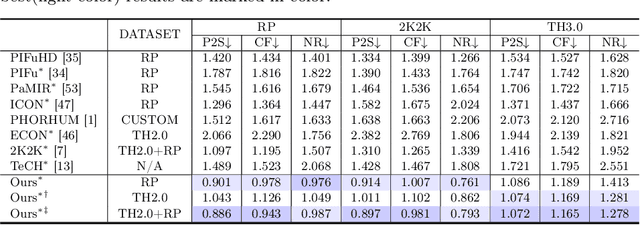
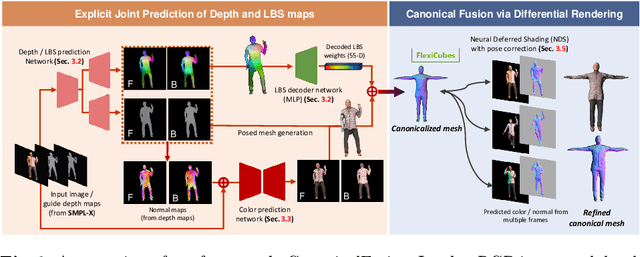
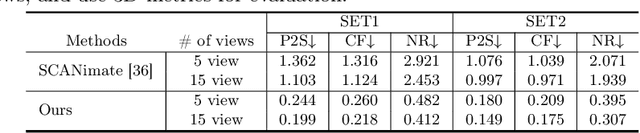
We present a novel framework for reconstructing animatable human avatars from multiple images, termed CanonicalFusion. Our central concept involves integrating individual reconstruction results into the canonical space. To be specific, we first predict Linear Blend Skinning (LBS) weight maps and depth maps using a shared-encoder-dual-decoder network, enabling direct canonicalization of the 3D mesh from the predicted depth maps. Here, instead of predicting high-dimensional skinning weights, we infer compressed skinning weights, i.e., 3-dimensional vector, with the aid of pre-trained MLP networks. We also introduce a forward skinning-based differentiable rendering scheme to merge the reconstructed results from multiple images. This scheme refines the initial mesh by reposing the canonical mesh via the forward skinning and by minimizing photometric and geometric errors between the rendered and the predicted results. Our optimization scheme considers the position and color of vertices as well as the joint angles for each image, thereby mitigating the negative effects of pose errors. We conduct extensive experiments to demonstrate the effectiveness of our method and compare our CanonicalFusion with state-of-the-art methods. Our source codes are available at https://github.com/jsshin98/CanonicalFusion.