 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCog3DMap: Multi-View Vision-Language Reasoning with 3D Cognitive Maps
Mar 24, 2026Precise spatial understanding from multi-view images remains a fundamental challenge for Multimodal Large Language Models (MLLMs), as their visual representations are predominantly semantic and lack explicit geometric grounding. While existing approaches augment visual tokens with geometric cues from visual geometry models, their MLLM is still required to implicitly infer the underlying 3D structure of the scene from these augmented tokens, limiting its spatial reasoning capability. To address this issue, we introduce Cog3DMap, a framework that recurrently constructs an explicit 3D memory from multi-view images, where each token is grounded in 3D space and possesses both semantic and geometric information. By feeding these tokens into the MLLM, our framework enables direct reasoning over a spatially structured 3D map, achieving state-of-the-art performance on various spatial reasoning benchmarks. Code will be made publicly available.
Vision-aligned Latent Reasoning for Multi-modal Large Language Model
Feb 04, 2026Despite recent advancements in Multi-modal Large Language Models (MLLMs) on diverse understanding tasks, these models struggle to solve problems which require extensive multi-step reasoning. This is primarily due to the progressive dilution of visual information during long-context generation, which hinders their ability to fully exploit test-time scaling. To address this issue, we introduce Vision-aligned Latent Reasoning (VaLR), a simple, yet effective reasoning framework that dynamically generates vision-aligned latent tokens before each Chain of Thought reasoning step, guiding the model to reason based on perceptual cues in the latent space. Specifically, VaLR is trained to preserve visual knowledge during reasoning by aligning intermediate embeddings of MLLM with those from vision encoders. Empirical results demonstrate that VaLR consistently outperforms existing approaches across a wide range of benchmarks requiring long-context understanding or precise visual perception, while exhibiting test-time scaling behavior not observed in prior MLLMs. In particular, VaLR improves the performance significantly from 33.0% to 52.9% on VSI-Bench, achieving a 19.9%p gain over Qwen2.5-VL.
MV-SAM: Multi-view Promptable Segmentation using Pointmap Guidance
Jan 25, 2026Promptable segmentation has emerged as a powerful paradigm in computer vision, enabling users to guide models in parsing complex scenes with prompts such as clicks, boxes, or textual cues. Recent advances, exemplified by the Segment Anything Model (SAM), have extended this paradigm to videos and multi-view images. However, the lack of 3D awareness often leads to inconsistent results, necessitating costly per-scene optimization to enforce 3D consistency. In this work, we introduce MV-SAM, a framework for multi-view segmentation that achieves 3D consistency using pointmaps -- 3D points reconstructed from unposed images by recent visual geometry models. Leveraging the pixel-point one-to-one correspondence of pointmaps, MV-SAM lifts images and prompts into 3D space, eliminating the need for explicit 3D networks or annotated 3D data. Specifically, MV-SAM extends SAM by lifting image embeddings from its pretrained encoder into 3D point embeddings, which are decoded by a transformer using cross-attention with 3D prompt embeddings. This design aligns 2D interactions with 3D geometry, enabling the model to implicitly learn consistent masks across views through 3D positional embeddings. Trained on the SA-1B dataset, our method generalizes well across domains, outperforming SAM2-Video and achieving comparable performance with per-scene optimization baselines on NVOS, SPIn-NeRF, ScanNet++, uCo3D, and DL3DV benchmarks. Code will be released.
Quantile Rendering: Efficiently Embedding High-dimensional Feature on 3D Gaussian Splatting
Dec 24, 2025

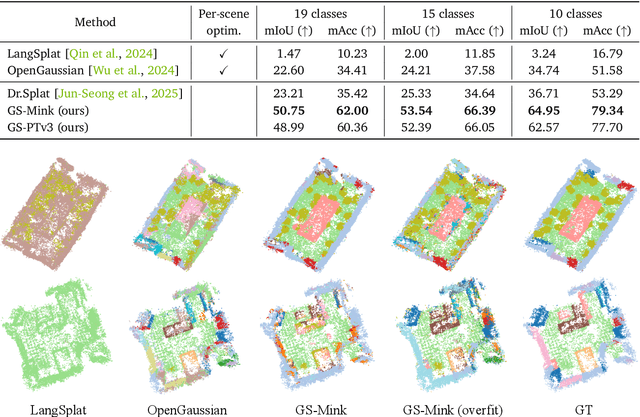

Recent advancements in computer vision have successfully extended Open-vocabulary segmentation (OVS) to the 3D domain by leveraging 3D Gaussian Splatting (3D-GS). Despite this progress, efficiently rendering the high-dimensional features required for open-vocabulary queries poses a significant challenge. Existing methods employ codebooks or feature compression, causing information loss, thereby degrading segmentation quality. To address this limitation, we introduce Quantile Rendering (Q-Render), a novel rendering strategy for 3D Gaussians that efficiently handles high-dimensional features while maintaining high fidelity. Unlike conventional volume rendering, which densely samples all 3D Gaussians intersecting each ray, Q-Render sparsely samples only those with dominant influence along the ray. By integrating Q-Render into a generalizable 3D neural network, we also propose Gaussian Splatting Network (GS-Net), which predicts Gaussian features in a generalizable manner. Extensive experiments on ScanNet and LeRF demonstrate that our framework outperforms state-of-the-art methods, while enabling real-time rendering with an approximate ~43.7x speedup on 512-D feature maps. Code will be made publicly available.
RoDyGS: Robust Dynamic Gaussian Splatting for Casual Videos
Dec 04, 2024Dynamic view synthesis (DVS) has advanced remarkably in recent years, achieving high-fidelity rendering while reducing computational costs. Despite the progress, optimizing dynamic neural fields from casual videos remains challenging, as these videos do not provide direct 3D information, such as camera trajectories or the underlying scene geometry. In this work, we present RoDyGS, an optimization pipeline for dynamic Gaussian Splatting from casual videos. It effectively learns motion and underlying geometry of scenes by separating dynamic and static primitives, and ensures that the learned motion and geometry are physically plausible by incorporating motion and geometric regularization terms. We also introduce a comprehensive benchmark, Kubric-MRig, that provides extensive camera and object motion along with simultaneous multi-view captures, features that are absent in previous benchmarks. Experimental results demonstrate that the proposed method significantly outperforms previous pose-free dynamic neural fields and achieves competitive rendering quality compared to existing pose-free static neural fields. The code and data are publicly available at https://rodygs.github.io/.
NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image
Dec 12, 2023
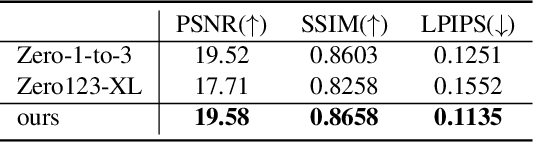
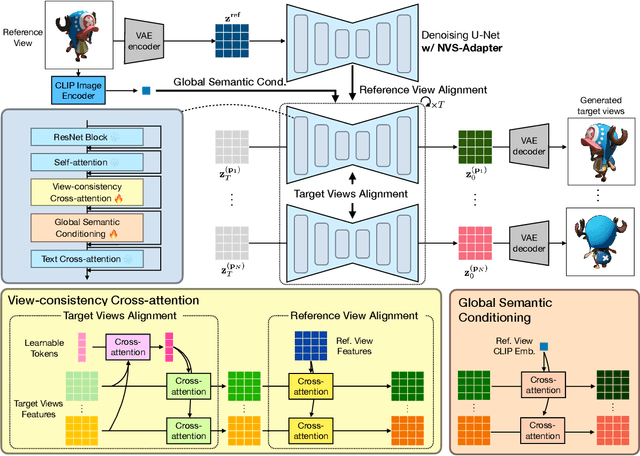
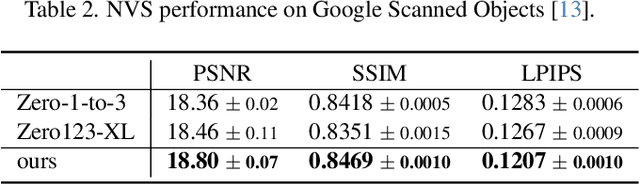
Transfer learning of large-scale Text-to-Image (T2I) models has recently shown impressive potential for Novel View Synthesis (NVS) of diverse objects from a single image. While previous methods typically train large models on multi-view datasets for NVS, fine-tuning the whole parameters of T2I models not only demands a high cost but also reduces the generalization capacity of T2I models in generating diverse images in a new domain. In this study, we propose an effective method, dubbed NVS-Adapter, which is a plug-and-play module for a T2I model, to synthesize novel multi-views of visual objects while fully exploiting the generalization capacity of T2I models. NVS-Adapter consists of two main components; view-consistency cross-attention learns the visual correspondences to align the local details of view features, and global semantic conditioning aligns the semantic structure of generated views with the reference view. Experimental results demonstrate that the NVS-Adapter can effectively synthesize geometrically consistent multi-views and also achieve high performance on benchmarks without full fine-tuning of T2I models. The code and data are publicly available in ~\href{https://postech-cvlab.github.io/nvsadapter/}{https://postech-cvlab.github.io/nvsadapter/}.
Stable and Consistent Prediction of 3D Characteristic Orientation via Invariant Residual Learning
Jun 20, 2023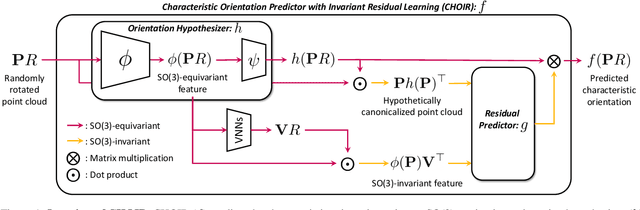

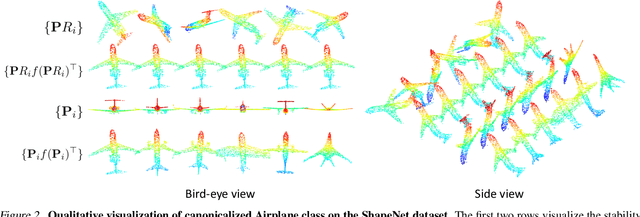

Learning to predict reliable characteristic orientations of 3D point clouds is an important yet challenging problem, as different point clouds of the same class may have largely varying appearances. In this work, we introduce a novel method to decouple the shape geometry and semantics of the input point cloud to achieve both stability and consistency. The proposed method integrates shape-geometry-based SO(3)-equivariant learning and shape-semantics-based SO(3)-invariant residual learning, where a final characteristic orientation is obtained by calibrating an SO(3)-equivariant orientation hypothesis using an SO(3)-invariant residual rotation. In experiments, the proposed method not only demonstrates superior stability and consistency but also exhibits state-of-the-art performances when applied to point cloud part segmentation, given randomly rotated inputs.
PeRFception: Perception using Radiance Fields
Aug 24, 2022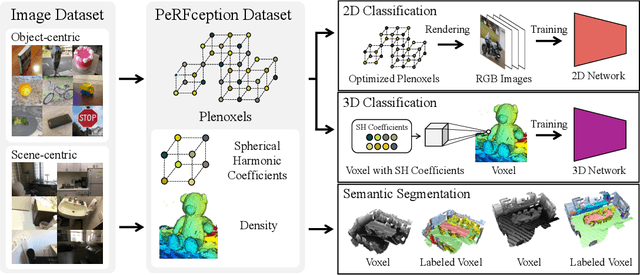
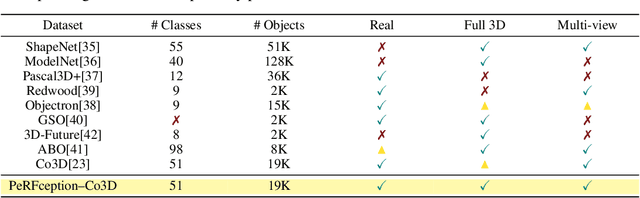
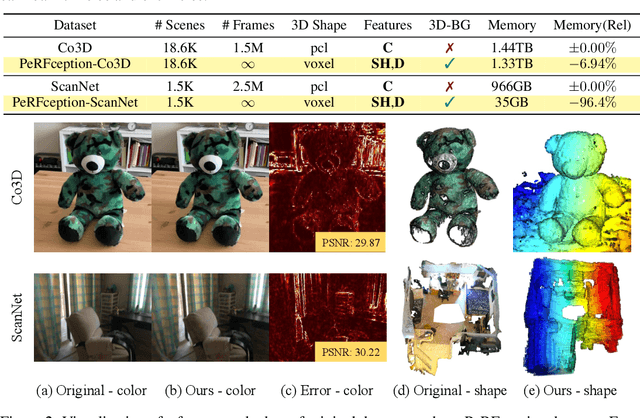

The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale implicit representation datasets for perception tasks, called the PeRFception, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4\%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take as input this implicit format and also propose a novel augmentation technique to avoid overfitting on backgrounds of images. The code and data are publicly available in https://postech-cvlab.github.io/PeRFception .
Self-Supervised Learning of Image Scale and Orientation
Jun 15, 2022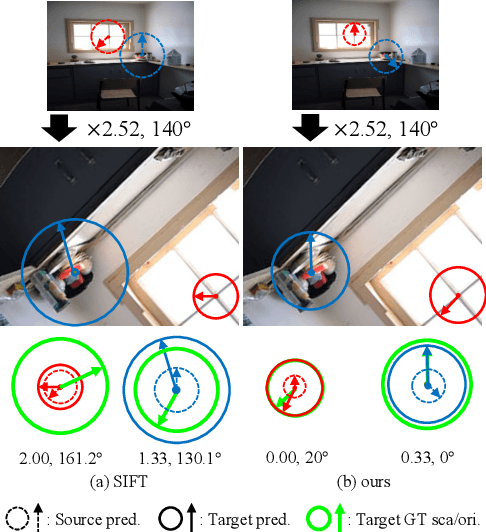
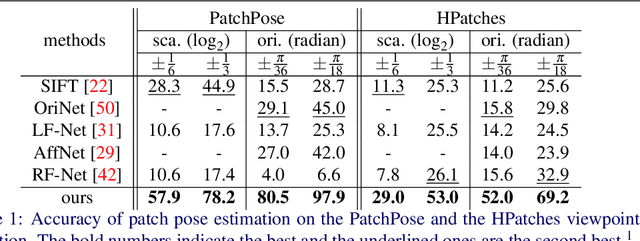
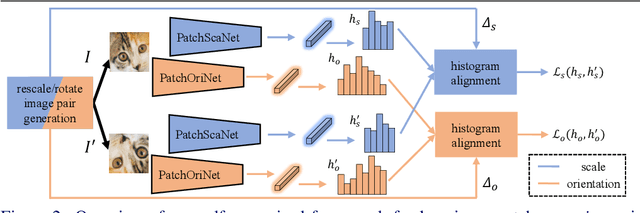
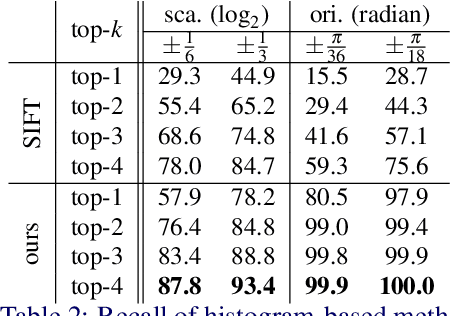
We study the problem of learning to assign a characteristic pose, i.e., scale and orientation, for an image region of interest. Despite its apparent simplicity, the problem is non-trivial; it is hard to obtain a large-scale set of image regions with explicit pose annotations that a model directly learns from. To tackle the issue, we propose a self-supervised learning framework with a histogram alignment technique. It generates pairs of image patches by random rescaling/rotating and then train an estimator to predict their scale/orientation values so that their relative difference is consistent with the rescaling/rotating used. The estimator learns to predict a non-parametric histogram distribution of scale/orientation without any supervision. Experiments show that it significantly outperforms previous methods in scale/orientation estimation and also improves image matching and 6 DoF camera pose estimation by incorporating our patch poses into a matching process.
Fast Point Transformer
Dec 09, 2021
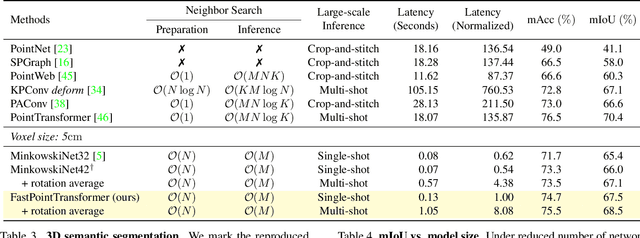
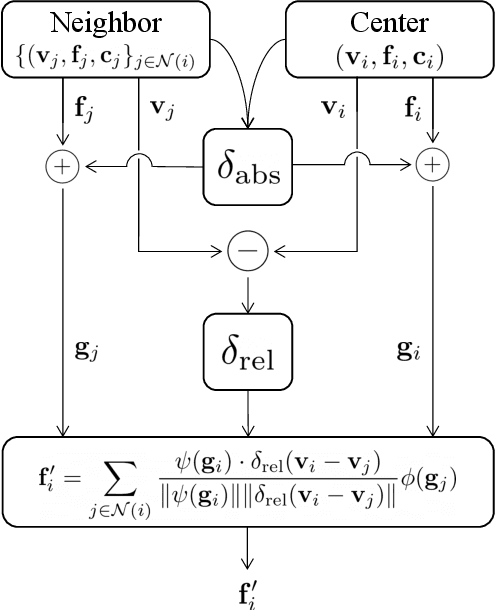
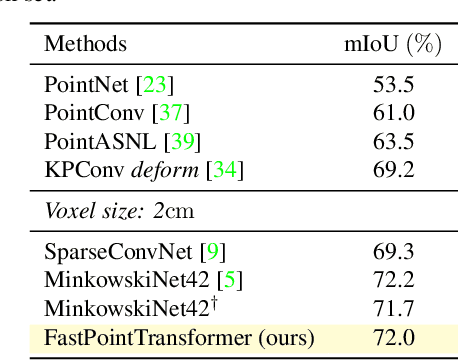
The recent success of neural networks enables a better interpretation of 3D point clouds, but processing a large-scale 3D scene remains a challenging problem. Most current approaches divide a large-scale scene into small regions and combine the local predictions together. However, this scheme inevitably involves additional stages for pre- and post-processing and may also degrade the final output due to predictions in a local perspective. This paper introduces Fast Point Transformer that consists of a new lightweight self-attention layer. Our approach encodes continuous 3D coordinates, and the voxel hashing-based architecture boosts computational efficiency. The proposed method is demonstrated with 3D semantic segmentation and 3D detection. The accuracy of our approach is competitive to the best voxel-based method, and our network achieves 136 times faster inference time than the state-of-the-art, Point Transformer, with a reasonable accuracy trade-off.