 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDextER: Language-driven Dexterous Grasp Generation with Embodied Reasoning
Jan 22, 2026Language-driven dexterous grasp generation requires the models to understand task semantics, 3D geometry, and complex hand-object interactions. While vision-language models have been applied to this problem, existing approaches directly map observations to grasp parameters without intermediate reasoning about physical interactions. We present DextER, Dexterous Grasp Generation with Embodied Reasoning, which introduces contact-based embodied reasoning for multi-finger manipulation. Our key insight is that predicting which hand links contact where on the object surface provides an embodiment-aware intermediate representation bridging task semantics with physical constraints. DextER autoregressively generates embodied contact tokens specifying which finger links contact where on the object surface, followed by grasp tokens encoding the hand configuration. On DexGYS, DextER achieves 67.14% success rate, outperforming state-of-the-art by 3.83%p with 96.4% improvement in intention alignment. We also demonstrate steerable generation through partial contact specification, providing fine-grained control over grasp synthesis.
Progressive Weight Loading: Accelerating Initial Inference and Gradually Boosting Performance on Resource-Constrained Environments
Sep 26, 2025Deep learning models have become increasingly large and complex, resulting in higher memory consumption and computational demands. Consequently, model loading times and initial inference latency have increased, posing significant challenges in mobile and latency-sensitive environments where frequent model loading and unloading are required, which directly impacts user experience. While Knowledge Distillation (KD) offers a solution by compressing large teacher models into smaller student ones, it often comes at the cost of reduced performance. To address this trade-off, we propose Progressive Weight Loading (PWL), a novel technique that enables fast initial inference by first deploying a lightweight student model, then incrementally replacing its layers with those of a pre-trained teacher model. To support seamless layer substitution, we introduce a training method that not only aligns intermediate feature representations between student and teacher layers, but also improves the overall output performance of the student model. Our experiments on VGG, ResNet, and ViT architectures demonstrate that models trained with PWL maintain competitive distillation performance and gradually improve accuracy as teacher layers are loaded-matching the final accuracy of the full teacher model without compromising initial inference speed. This makes PWL particularly suited for dynamic, resource-constrained deployments where both responsiveness and performance are critical.
Affogato: Learning Open-Vocabulary Affordance Grounding with Automated Data Generation at Scale
Jun 13, 2025Affordance grounding-localizing object regions based on natural language descriptions of interactions-is a critical challenge for enabling intelligent agents to understand and interact with their environments. However, this task remains challenging due to the need for fine-grained part-level localization, the ambiguity arising from multiple valid interaction regions, and the scarcity of large-scale datasets. In this work, we introduce Affogato, a large-scale benchmark comprising 150K instances, annotated with open-vocabulary text descriptions and corresponding 3D affordance heatmaps across a diverse set of objects and interactions. Building on this benchmark, we develop simple yet effective vision-language models that leverage pretrained part-aware vision backbones and a text-conditional heatmap decoder. Our models trained with the Affogato dataset achieve promising performance on the existing 2D and 3D benchmarks, and notably, exhibit effectiveness in open-vocabulary cross-domain generalization. The Affogato dataset is shared in public: https://huggingface.co/datasets/project-affogato/affogato
Mosaic3D: Foundation Dataset and Model for Open-Vocabulary 3D Segmentation
Feb 04, 2025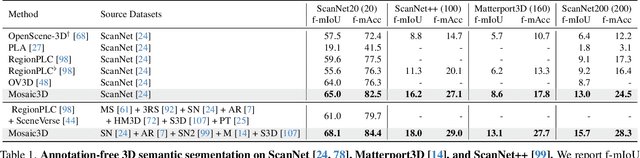

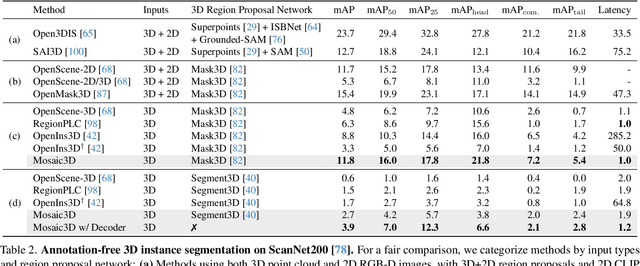
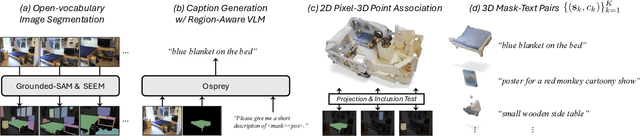
We tackle open-vocabulary 3D scene understanding by introducing a novel data generation pipeline and training framework. Our method addresses three critical requirements for effective training: precise 3D region segmentation, comprehensive textual descriptions, and sufficient dataset scale. By leveraging state-of-the-art open-vocabulary image segmentation models and region-aware Vision-Language Models, we develop an automatic pipeline that generates high-quality 3D mask-text pairs. Applying this pipeline to multiple 3D scene datasets, we create Mosaic3D-5.6M, a dataset of over 30K annotated scenes with 5.6M mask-text pairs, significantly larger than existing datasets. Building upon this data, we propose Mosaic3D, a foundation model combining a 3D encoder trained with contrastive learning and a lightweight mask decoder for open-vocabulary 3D semantic and instance segmentation. Our approach achieves state-of-the-art results on open-vocabulary 3D semantic and instance segmentation tasks including ScanNet200, Matterport3D, and ScanNet++, with ablation studies validating the effectiveness of our large-scale training data.
Self-Supervised Learning with Probabilistic Density Labeling for Rainfall Probability Estimation
Dec 08, 2024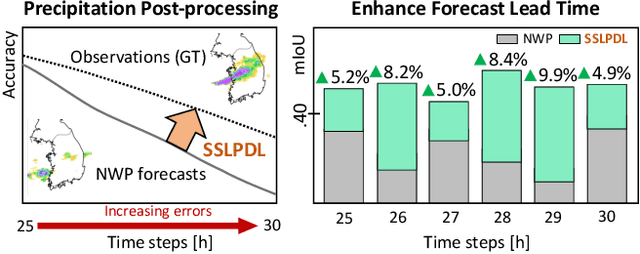

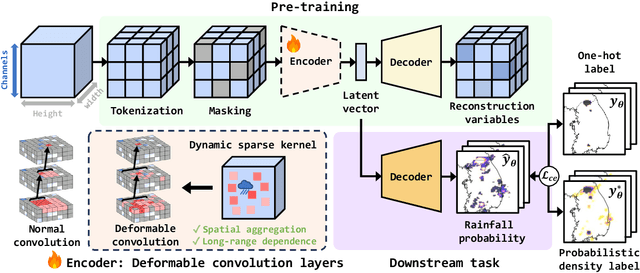
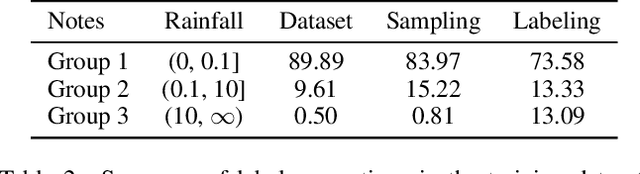
Numerical weather prediction (NWP) models are fundamental in meteorology for simulating and forecasting the behavior of various atmospheric variables. The accuracy of precipitation forecasts and the acquisition of sufficient lead time are crucial for preventing hazardous weather events. However, the performance of NWP models is limited by the nonlinear and unpredictable patterns of extreme weather phenomena driven by temporal dynamics. In this regard, we propose a \textbf{S}elf-\textbf{S}upervised \textbf{L}earning with \textbf{P}robabilistic \textbf{D}ensity \textbf{L}abeling (SSLPDL) for estimating rainfall probability by post-processing NWP forecasts. Our post-processing method uses self-supervised learning (SSL) with masked modeling for reconstructing atmospheric physics variables, enabling the model to learn the dependency between variables. The pre-trained encoder is then utilized in transfer learning to a precipitation segmentation task. Furthermore, we introduce a straightforward labeling approach based on probability density to address the class imbalance in extreme weather phenomena like heavy rain events. Experimental results show that SSLPDL surpasses other precipitation forecasting models in regional precipitation post-processing and demonstrates competitive performance in extending forecast lead times. Our code is available at https://github.com/joonha425/SSLPDL
Illustrious: an Open Advanced Illustration Model
Sep 30, 2024



In this work, we share the insights for achieving state-of-the-art quality in our text-to-image anime image generative model, called Illustrious. To achieve high resolution, dynamic color range images, and high restoration ability, we focus on three critical approaches for model improvement. First, we delve into the significance of the batch size and dropout control, which enables faster learning of controllable token based concept activations. Second, we increase the training resolution of images, affecting the accurate depiction of character anatomy in much higher resolution, extending its generation capability over 20MP with proper methods. Finally, we propose the refined multi-level captions, covering all tags and various natural language captions as a critical factor for model development. Through extensive analysis and experiments, Illustrious demonstrates state-of-the-art performance in terms of animation style, outperforming widely-used models in illustration domains, propelling easier customization and personalization with nature of open source. We plan to publicly release updated Illustrious model series sequentially as well as sustainable plans for improvements.
3D Geometric Shape Assembly via Efficient Point Cloud Matching
Jul 15, 2024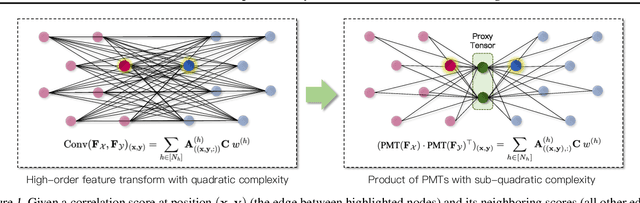
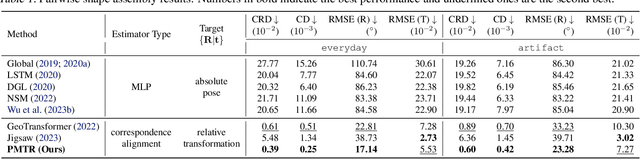
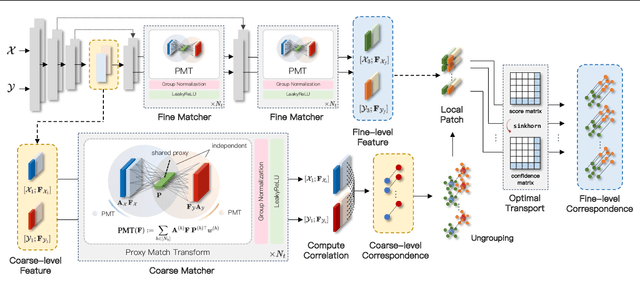
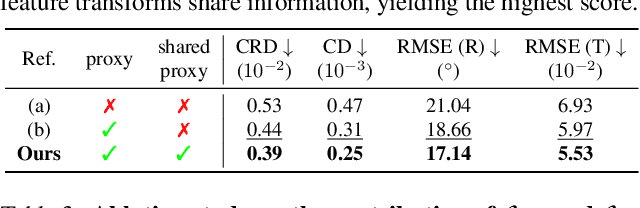
Learning to assemble geometric shapes into a larger target structure is a pivotal task in various practical applications. In this work, we tackle this problem by establishing local correspondences between point clouds of part shapes in both coarse- and fine-levels. To this end, we introduce Proxy Match Transform (PMT), an approximate high-order feature transform layer that enables reliable matching between mating surfaces of parts while incurring low costs in memory and computation. Building upon PMT, we introduce a new framework, dubbed Proxy Match TransformeR (PMTR), for the geometric assembly task. We evaluate the proposed PMTR on the large-scale 3D geometric shape assembly benchmark dataset of Breaking Bad and demonstrate its superior performance and efficiency compared to state-of-the-art methods. Project page: https://nahyuklee.github.io/pmtr.
CAT: Contrastive Adapter Training for Personalized Image Generation
Apr 11, 2024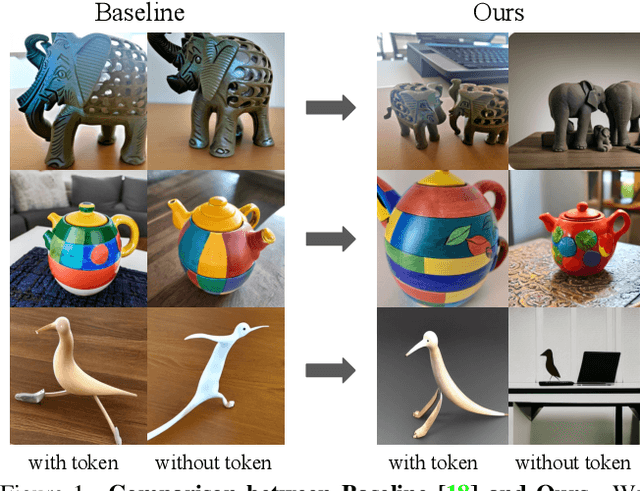
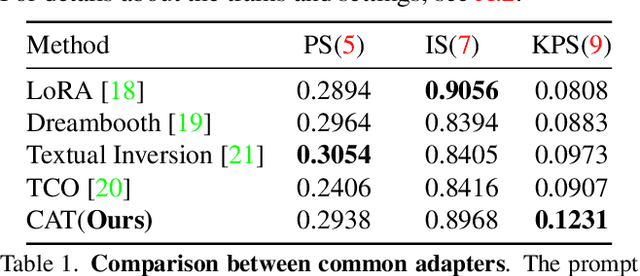
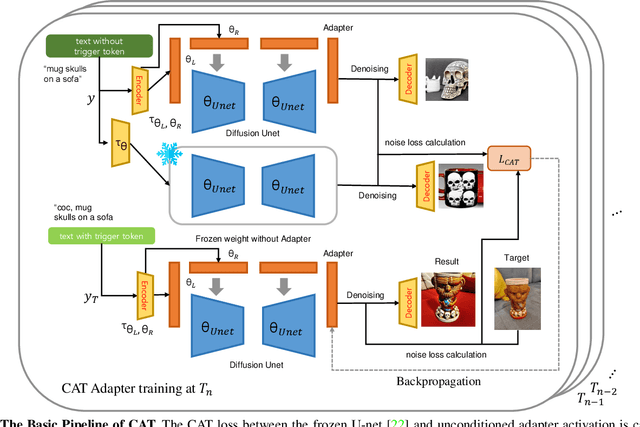

The emergence of various adapters, including Low-Rank Adaptation (LoRA) applied from the field of natural language processing, has allowed diffusion models to personalize image generation at a low cost. However, due to the various challenges including limited datasets and shortage of regularization and computation resources, adapter training often results in unsatisfactory outcomes, leading to the corruption of the backbone model's prior knowledge. One of the well known phenomena is the loss of diversity in object generation, especially within the same class which leads to generating almost identical objects with minor variations. This poses challenges in generation capabilities. To solve this issue, we present Contrastive Adapter Training (CAT), a simple yet effective strategy to enhance adapter training through the application of CAT loss. Our approach facilitates the preservation of the base model's original knowledge when the model initiates adapters. Furthermore, we introduce the Knowledge Preservation Score (KPS) to evaluate CAT's ability to keep the former information. We qualitatively and quantitatively compare CAT's improvement. Finally, we mention the possibility of CAT in the aspects of multi-concept adapter and optimization.
Self-supervised Pre-training for Precipitation Post-processor
Oct 31, 2023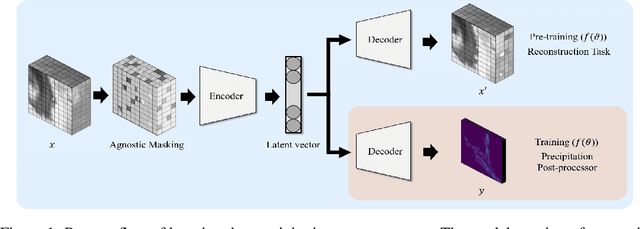
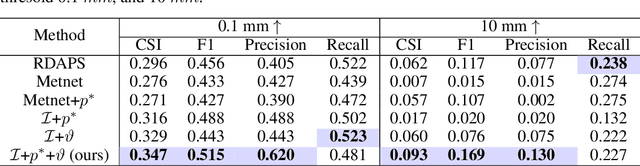
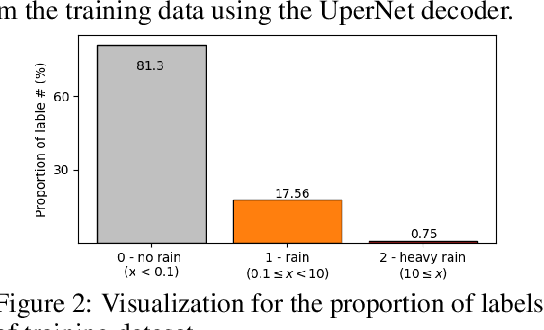
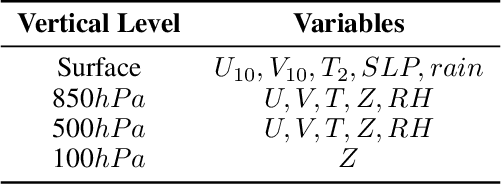
Securing sufficient forecast lead time for local precipitation is essential for preventing hazardous weather events. Nonetheless, global warming-induced climate change is adding to the challenge of accurately predicting severe precipitation events, such as heavy rainfall. In this work, we propose a deep learning-based precipitation post-processor approach to numerical weather prediction (NWP) models. The precipitation post-processor consists of (i) self-supervised pre-training, where parameters of encoder are pre-trained on the reconstruction of masked variables of the atmospheric physics domain, and (ii) transfer learning on precipitation segmentation tasks (target domain) from the pre-trained encoder. We also introduce a heuristic labeling approach for effectively training class-imbalanced datasets. Our experiment results in precipitation correction for regional NWP show that the proposed method outperforms other approaches.
PeRFception: Perception using Radiance Fields
Aug 24, 2022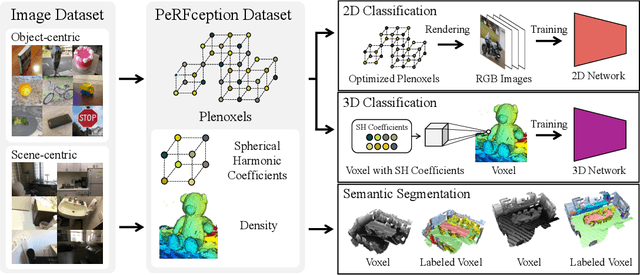
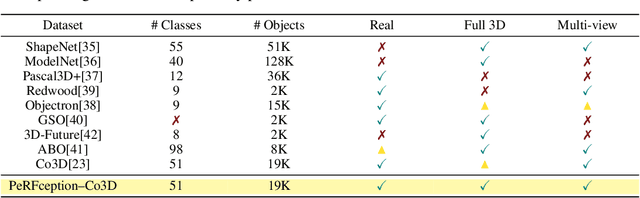
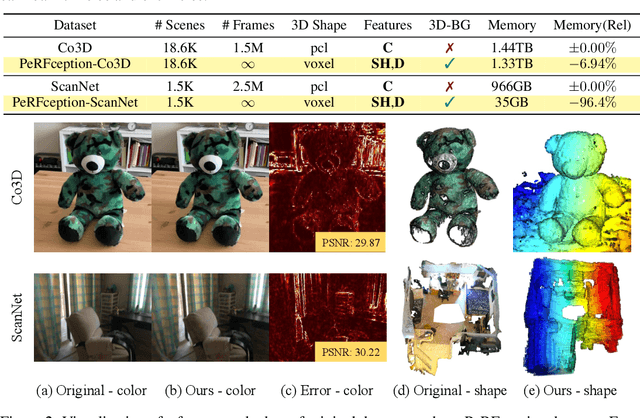

The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale implicit representation datasets for perception tasks, called the PeRFception, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4\%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take as input this implicit format and also propose a novel augmentation technique to avoid overfitting on backgrounds of images. The code and data are publicly available in https://postech-cvlab.github.io/PeRFception .