 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllustrious: an Open Advanced Illustration Model
Sep 30, 2024



In this work, we share the insights for achieving state-of-the-art quality in our text-to-image anime image generative model, called Illustrious. To achieve high resolution, dynamic color range images, and high restoration ability, we focus on three critical approaches for model improvement. First, we delve into the significance of the batch size and dropout control, which enables faster learning of controllable token based concept activations. Second, we increase the training resolution of images, affecting the accurate depiction of character anatomy in much higher resolution, extending its generation capability over 20MP with proper methods. Finally, we propose the refined multi-level captions, covering all tags and various natural language captions as a critical factor for model development. Through extensive analysis and experiments, Illustrious demonstrates state-of-the-art performance in terms of animation style, outperforming widely-used models in illustration domains, propelling easier customization and personalization with nature of open source. We plan to publicly release updated Illustrious model series sequentially as well as sustainable plans for improvements.
Improving Text Generation on Images with Synthetic Captions
Jun 01, 2024
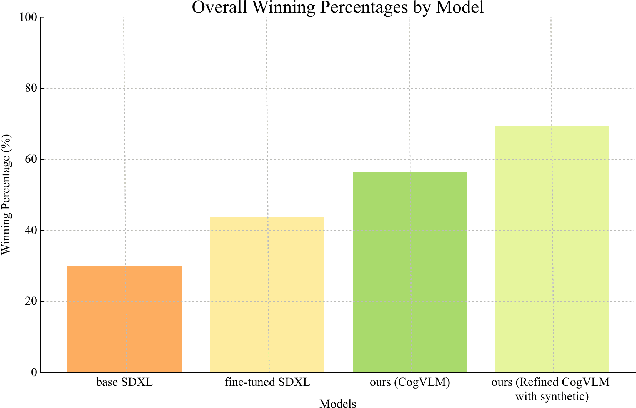


The recent emergence of latent diffusion models such as SDXL and SD 1.5 has shown significant capability in generating highly detailed and realistic images. Despite their remarkable ability to produce images, generating accurate text within images still remains a challenging task. In this paper, we examine the validity of fine-tuning approaches in generating legible text within the image. We propose a low-cost approach by leveraging SDXL without any time-consuming training on large-scale datasets. The proposed strategy employs a fine-tuning technique that examines the effects of data refinement levels and synthetic captions. Moreover, our results demonstrate how our small scale fine-tuning approach can improve the accuracy of text generation in different scenarios without the need of additional multimodal encoders. Our experiments show that with the addition of random letters to our raw dataset, our model's performance improves in producing well-formed visual text.
CAT: Contrastive Adapter Training for Personalized Image Generation
Apr 11, 2024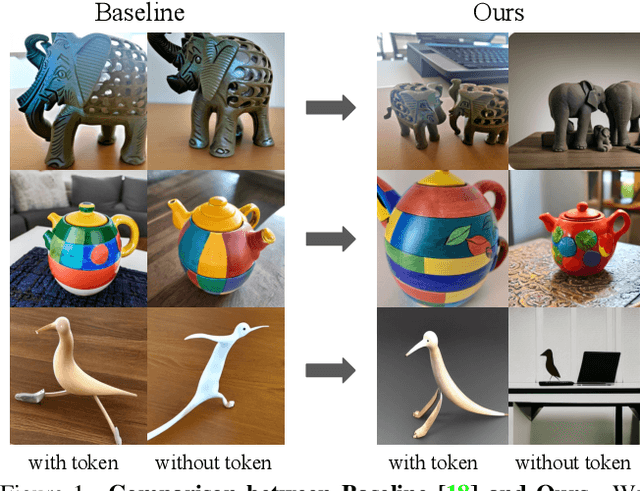
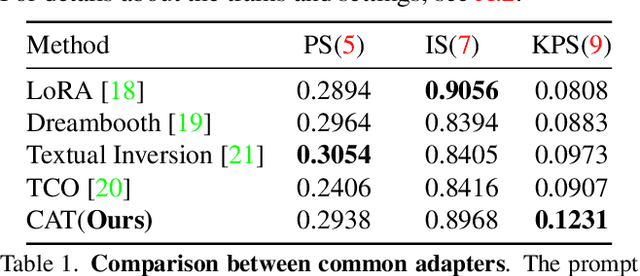
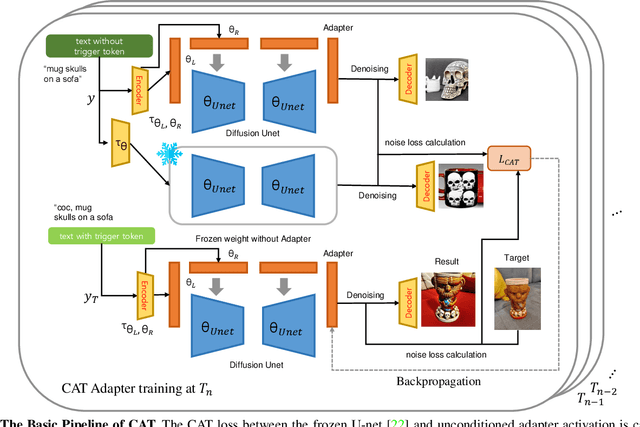

The emergence of various adapters, including Low-Rank Adaptation (LoRA) applied from the field of natural language processing, has allowed diffusion models to personalize image generation at a low cost. However, due to the various challenges including limited datasets and shortage of regularization and computation resources, adapter training often results in unsatisfactory outcomes, leading to the corruption of the backbone model's prior knowledge. One of the well known phenomena is the loss of diversity in object generation, especially within the same class which leads to generating almost identical objects with minor variations. This poses challenges in generation capabilities. To solve this issue, we present Contrastive Adapter Training (CAT), a simple yet effective strategy to enhance adapter training through the application of CAT loss. Our approach facilitates the preservation of the base model's original knowledge when the model initiates adapters. Furthermore, we introduce the Knowledge Preservation Score (KPS) to evaluate CAT's ability to keep the former information. We qualitatively and quantitatively compare CAT's improvement. Finally, we mention the possibility of CAT in the aspects of multi-concept adapter and optimization.