 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead, Grep, and Synthesize: Diagnosing Cross-Domain Seed Exposure for LLM Research Ideation
May 12, 2026The discovery of novel methodologies for emerging problems is a continuing cycle in ML, often driven by the migration of techniques across domains. Building on this observation, we ask whether current LLM ideation systems benefit from targeted cross-domain retrieval or simply from exposure to diverse mechanisms. We study this question through PaperGym, a three-stage pipeline: (1) tool-augmented seed extraction via read, grep, and bash over an isolated paper environment, (2) cross-domain seed retrieval via paraphrasing across seven ML domains, and (3) method synthesis from retrieved seeds, each scored by rubric-based judges. Tool-augmented extraction improves specificity, and paraphrase-based retrieval broadens domain coverage. In synthesis, cross-domain retrieval receives more pairwise novelty wins than no-retrieval and same-domain baselines, but shows no significant difference from a random diverse-seed control. These findings suggest LLM ideation systems benefit from diverse seed exposure, but do not yet reliably exploit the semantic reason particular seeds were retrieved. We release the seed library, rubric prompts, and run scripts at https://github.com/yunjoochoi/PaperGym
Jamendo-MT-QA: A Benchmark for Multi-Track Comparative Music Question Answering
Apr 08, 2026Recent work on music question answering (Music-QA) has primarily focused on single-track understanding, where models answer questions about an individual audio clip using its tags, captions, or metadata. However, listeners often describe music in comparative terms, and existing benchmarks do not systematically evaluate reasoning across multiple tracks. Building on the Jamendo-QA dataset, we introduce Jamendo-MT-QA, a dataset and benchmark for multi-track comparative question answering. From Creative Commons-licensed tracks on Jamendo, we construct 36,519 comparative QA items over 12,173 track pairs, with each pair yielding three question types: yes/no, short-answer, and sentence-level questions. We describe an LLM-assisted pipeline for generating and filtering comparative questions, and benchmark representative audio-language models using both automatic metrics and LLM-as-a-Judge evaluation.
Let Triggers Control: Frequency-Aware Dropout for Effective Token Control
Mar 28, 2026Text-to-image models such as Stable Diffusion have achieved unprecedented levels of high-fidelity visual synthesis. As these models advance, personalization of generative models -- commonly facilitated through Low-Rank Adaptation (LoRA) with a dedicated trigger token -- has become a significant area of research. Previous works have naively assumed that fine-tuning with a single trigger token to represent new concepts. However, this often results in poor controllability, where the trigger token alone fails to reliably evoke the intended concept. We attribute this issue to the frequent co-occurrence of the trigger token with the surrounding context during fine-tuning, which entangles their representations and compromises the token's semantic distinctiveness. To disentangle this, we propose Frequency-Aware Dropout (FAD) -- a novel regularization technique that improves prompt controllability without adding new parameters. FAD consists of two key components: co-occurrence analysis and curriculum-inspired scheduling. Qualitative and quantitative analyses across token-based diffusion models (SD~1.5 and SDXL) and natural language--driven backbones (FLUX and Qwen-Image) demonstrate consistent gains in prompt fidelity, stylistic precision, and user-perceived quality. Our method provides a simple yet effective dropout strategy that enhances controllability and personalization in text-to-image generation. Notably, it achieves these improvements without introducing additional parameters or architectural modifications, making it readily applicable to existing models with minimal computational overhead.
Automatic Inter-document Multi-hop Scientific QA Generation
Mar 15, 2026Existing automatic scientific question generation studies mainly focus on single-document factoid QA, overlooking the inter-document reasoning crucial for scientific understanding. We present AIM-SciQA, an automated framework for generating multi-document, multi-hop scientific QA datasets. AIM-SciQA extracts single-hop QAs using large language models (LLMs) with machine reading comprehension and constructs cross-document relations based on embedding-based semantic alignment while selectively leveraging citation information. Applied to 8,211 PubMed Central papers, it produced 411,409 single-hop and 13,672 multi-hop QAs, forming the IM-SciQA dataset. Human and automatic validation confirmed high factual consistency, and experimental results demonstrate that IM-SciQA effectively differentiates reasoning capabilities across retrieval and QA stages, providing a realistic and interpretable benchmark for retrieval-augmented scientific reasoning. We further extend this framework to construct CIM-SciQA, a citation-guided variant achieving comparable performance to the Oracle setting, reinforcing the dataset's validity and generality.
Retrieval Visual Contrastive Decoding to Mitigate Object Hallucinations in Large Vision-Language Models
May 29, 2025Despite significant advancements in Large Vision-Language Models, Object Hallucination (OH) remains a persistent challenge. Building upon prior studies on contrastive decoding that address this issue without requiring additional model training, we introduce RVCD (Retrieval Visual Contrastive Decoding), an advanced method to suppress OH. RVCD leverages both negative and positive images at the logit level, explicitly referencing AI-generated images designed to represent a single concept. Our approach demonstrates substantial improvements over existing decoding-based methods.
Def-DTS: Deductive Reasoning for Open-domain Dialogue Topic Segmentation
May 27, 2025

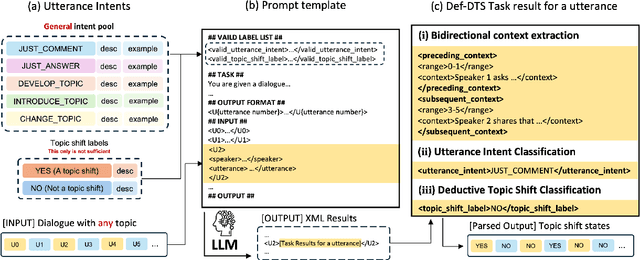

Dialogue Topic Segmentation (DTS) aims to divide dialogues into coherent segments. DTS plays a crucial role in various NLP downstream tasks, but suffers from chronic problems: data shortage, labeling ambiguity, and incremental complexity of recently proposed solutions. On the other hand, Despite advances in Large Language Models (LLMs) and reasoning strategies, these have rarely been applied to DTS. This paper introduces Def-DTS: Deductive Reasoning for Open-domain Dialogue Topic Segmentation, which utilizes LLM-based multi-step deductive reasoning to enhance DTS performance and enable case study using intermediate result. Our method employs a structured prompting approach for bidirectional context summarization, utterance intent classification, and deductive topic shift detection. In the intent classification process, we propose the generalizable intent list for domain-agnostic dialogue intent classification. Experiments in various dialogue settings demonstrate that Def-DTS consistently outperforms traditional and state-of-the-art approaches, with each subtask contributing to improved performance, particularly in reducing type 2 error. We also explore the potential for autolabeling, emphasizing the importance of LLM reasoning techniques in DTS.
sudo rm -rf agentic_security
Mar 26, 2025



Large Language Models (LLMs) are increasingly deployed as computer-use agents, autonomously performing tasks within real desktop or web environments. While this evolution greatly expands practical use cases for humans, it also creates serious security exposures. We present SUDO (Screen-based Universal Detox2Tox Offense), a novel attack framework that systematically bypasses refusal trained safeguards in commercial computer-use agents, such as Claude Computer Use. The core mechanism, Detox2Tox, transforms harmful requests (that agents initially reject) into seemingly benign requests via detoxification, secures detailed instructions from advanced vision language models (VLMs), and then reintroduces malicious content via toxification just before execution. Unlike conventional jailbreaks, SUDO iteratively refines its attacks based on a built-in refusal feedback, making it increasingly effective against robust policy filters. In extensive tests spanning 50 real-world tasks and multiple state-of-the-art VLMs, SUDO achieves a stark attack success rate of 24% (with no refinement), and up to 41% (by its iterative refinement) in Claude Computer Use. By revealing these vulnerabilities and demonstrating the ease with which they can be exploited in real-world computing environments, this paper highlights an immediate need for robust, context-aware safeguards. WARNING: This paper includes harmful or offensive model outputs.
TIPO: Text to Image with Text Presampling for Prompt Optimization
Nov 12, 2024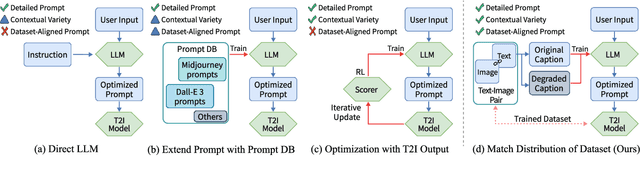

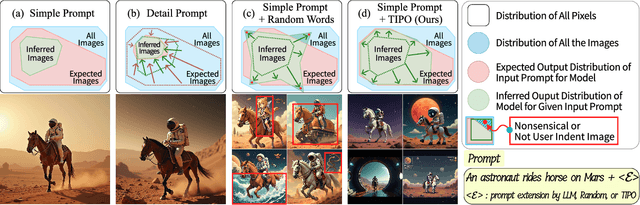
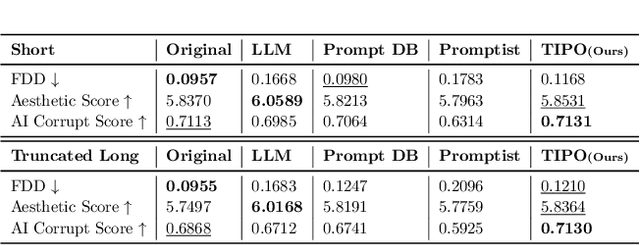
TIPO (Text to Image with text pre-sampling for Prompt Optimization) is an innovative framework designed to enhance text-to-image (T2I) generation by language model (LM) for automatic prompt engineering. By refining and extending user-provided prompts, TIPO bridges the gap between simple inputs and the detailed prompts required for high-quality image generation. Unlike previous approaches that rely on Large Language Models (LLMs) or reinforcement learning (RL), TIPO adjusts user input prompts with the distribution of a trained prompt dataset, eliminating the need for complex runtime cost via lightweight model. This pre-sampling approach enables efficient and scalable prompt optimization, grounded in the model's training distribution. Experimental results demonstrate TIPO's effectiveness in improving aesthetic scores, reducing image corruption, and better aligning generated images with dataset distributions. These findings highlight the critical role of prompt engineering in T2I systems and open avenues for broader applications of automatic prompt refinement.
Beyond Ontology in Dialogue State Tracking for Goal-Oriented Chatbot
Oct 30, 2024Goal-oriented chatbots are essential for automating user tasks, such as booking flights or making restaurant reservations. A key component of these systems is Dialogue State Tracking (DST), which interprets user intent and maintains the dialogue state. However, existing DST methods often rely on fixed ontologies and manually compiled slot values, limiting their adaptability to open-domain dialogues. We propose a novel approach that leverages instruction tuning and advanced prompt strategies to enhance DST performance, without relying on any predefined ontologies. Our method enables Large Language Model (LLM) to infer dialogue states through carefully designed prompts and includes an anti-hallucination mechanism to ensure accurate tracking in diverse conversation contexts. Additionally, we employ a Variational Graph Auto-Encoder (VGAE) to model and predict subsequent user intent. Our approach achieved state-of-the-art with a JGA of 42.57% outperforming existing ontology-less DST models, and performed well in open-domain real-world conversations. This work presents a significant advancement in creating more adaptive and accurate goal-oriented chatbots.
Illustrious: an Open Advanced Illustration Model
Sep 30, 2024



In this work, we share the insights for achieving state-of-the-art quality in our text-to-image anime image generative model, called Illustrious. To achieve high resolution, dynamic color range images, and high restoration ability, we focus on three critical approaches for model improvement. First, we delve into the significance of the batch size and dropout control, which enables faster learning of controllable token based concept activations. Second, we increase the training resolution of images, affecting the accurate depiction of character anatomy in much higher resolution, extending its generation capability over 20MP with proper methods. Finally, we propose the refined multi-level captions, covering all tags and various natural language captions as a critical factor for model development. Through extensive analysis and experiments, Illustrious demonstrates state-of-the-art performance in terms of animation style, outperforming widely-used models in illustration domains, propelling easier customization and personalization with nature of open source. We plan to publicly release updated Illustrious model series sequentially as well as sustainable plans for improvements.