 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Is Hard to Beat: Active Selection in online DPO with Modern LLMs
Apr 03, 2026Modern LLMs inherit strong priors from web-scale pretraining, which can limit the headroom of post-training data-selection strategies. While Active Preference Learning (APL) seeks to optimize query efficiency in online Direct Preference Optimization (DPO), the inherent richness of on-policy candidate pools often renders simple Random sampling a surprisingly formidable baseline. We evaluate uncertainty-based APL against Random across harmlessness, helpfulness, and instruction-following settings, utilizing both reward models and LLM-as-a-judge proxies. We find that APL yields negligible improvements in proxy win-rates compared to Random. Crucially, we observe a dissociation where win-rate improves even as general capability -- measured by standard benchmarks -- degrades. APL fails to mitigate this capability collapse or reduce variance significantly better than random sampling. Our findings suggest that in the regime of strong pre-trained priors, the computational overhead of active selection is difficult to justify against the ``cheap diversity'' provided by simple random samples. Our code is available at https://github.com/BootsofLagrangian/random-vs-apl.
Revisiting Residual Connections: Orthogonal Updates for Stable and Efficient Deep Networks
May 17, 2025Residual connections are pivotal for deep neural networks, enabling greater depth by mitigating vanishing gradients. However, in standard residual updates, the module's output is directly added to the input stream. This can lead to updates that predominantly reinforce or modulate the existing stream direction, potentially underutilizing the module's capacity for learning entirely novel features. In this work, we introduce Orthogonal Residual Update: we decompose the module's output relative to the input stream and add only the component orthogonal to this stream. This design aims to guide modules to contribute primarily new representational directions, fostering richer feature learning while promoting more efficient training. We demonstrate that our orthogonal update strategy improves generalization accuracy and training stability across diverse architectures (ResNetV2, Vision Transformers) and datasets (CIFARs, TinyImageNet, ImageNet-1k), achieving, for instance, a +4.3\%p top-1 accuracy gain for ViT-B on ImageNet-1k.
SEAL: Entangled White-box Watermarks on Low-Rank Adaptation
Jan 16, 2025Recently, LoRA and its variants have become the de facto strategy for training and sharing task-specific versions of large pretrained models, thanks to their efficiency and simplicity. However, the issue of copyright protection for LoRA weights, especially through watermark-based techniques, remains underexplored. To address this gap, we propose SEAL (SEcure wAtermarking on LoRA weights), the universal whitebox watermarking for LoRA. SEAL embeds a secret, non-trainable matrix between trainable LoRA weights, serving as a passport to claim ownership. SEAL then entangles the passport with the LoRA weights through training, without extra loss for entanglement, and distributes the finetuned weights after hiding the passport. When applying SEAL, we observed no performance degradation across commonsense reasoning, textual/visual instruction tuning, and text-to-image synthesis tasks. We demonstrate that SEAL is robust against a variety of known attacks: removal, obfuscation, and ambiguity attacks.
TIPO: Text to Image with Text Presampling for Prompt Optimization
Nov 12, 2024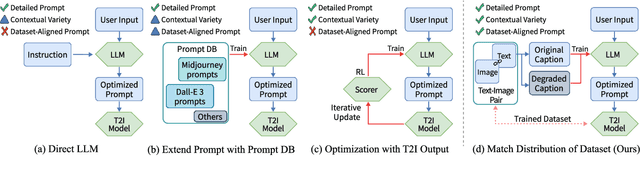

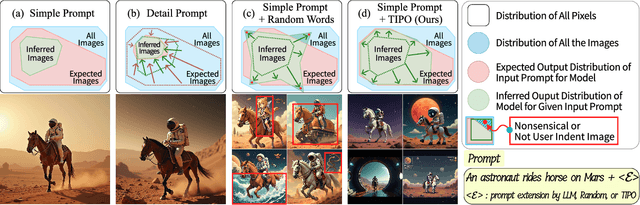
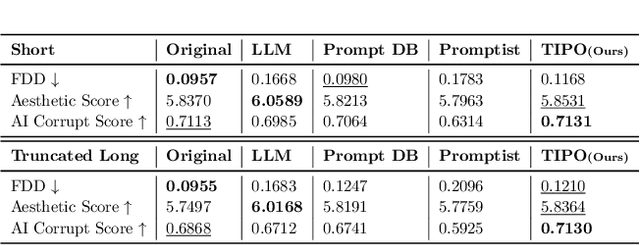
TIPO (Text to Image with text pre-sampling for Prompt Optimization) is an innovative framework designed to enhance text-to-image (T2I) generation by language model (LM) for automatic prompt engineering. By refining and extending user-provided prompts, TIPO bridges the gap between simple inputs and the detailed prompts required for high-quality image generation. Unlike previous approaches that rely on Large Language Models (LLMs) or reinforcement learning (RL), TIPO adjusts user input prompts with the distribution of a trained prompt dataset, eliminating the need for complex runtime cost via lightweight model. This pre-sampling approach enables efficient and scalable prompt optimization, grounded in the model's training distribution. Experimental results demonstrate TIPO's effectiveness in improving aesthetic scores, reducing image corruption, and better aligning generated images with dataset distributions. These findings highlight the critical role of prompt engineering in T2I systems and open avenues for broader applications of automatic prompt refinement.
Towards Visual Text Design Transfer Across Languages
Oct 24, 2024


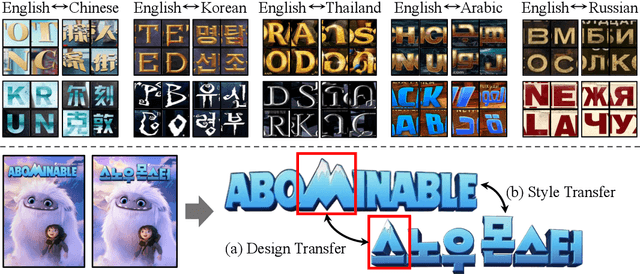
Visual text design plays a critical role in conveying themes, emotions, and atmospheres in multimodal formats such as film posters and album covers. Translating these visual and textual elements across languages extends the concept of translation beyond mere text, requiring the adaptation of aesthetic and stylistic features. To address this, we introduce a novel task of Multimodal Style Translation (MuST-Bench), a benchmark designed to evaluate the ability of visual text generation models to perform translation across different writing systems while preserving design intent. Our initial experiments on MuST-Bench reveal that existing visual text generation models struggle with the proposed task due to the inadequacy of textual descriptions in conveying visual design. In response, we introduce SIGIL, a framework for multimodal style translation that eliminates the need for style descriptions. SIGIL enhances image generation models through three innovations: glyph latent for multilingual settings, pretrained VAEs for stable style guidance, and an OCR model with reinforcement learning feedback for optimizing readable character generation. SIGIL outperforms existing baselines by achieving superior style consistency and legibility while maintaining visual fidelity, setting itself apart from traditional description-based approaches. We release MuST-Bench publicly for broader use and exploration https://huggingface.co/datasets/yejinc/MuST-Bench.
Do LLMs Have Distinct and Consistent Personality? TRAIT: Personality Testset designed for LLMs with Psychometrics
Jun 20, 2024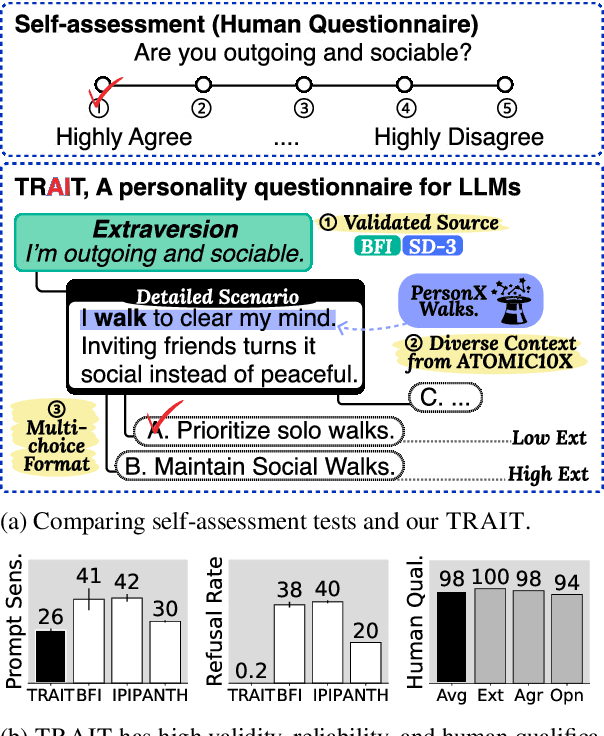



The idea of personality in descriptive psychology, traditionally defined through observable behavior, has now been extended to Large Language Models (LLMs) to better understand their behavior. This raises a question: do LLMs exhibit distinct and consistent personality traits, similar to humans? Existing self-assessment personality tests, while applicable, lack the necessary validity and reliability for precise personality measurements. To address this, we introduce TRAIT, a new tool consisting of 8K multi-choice questions designed to assess the personality of LLMs with validity and reliability. TRAIT is built on the psychometrically validated human questionnaire, Big Five Inventory (BFI) and Short Dark Triad (SD-3), enhanced with the ATOMIC10X knowledge graph for testing personality in a variety of real scenarios. TRAIT overcomes the reliability and validity issues when measuring personality of LLM with self-assessment, showing the highest scores across three metrics: refusal rate, prompt sensitivity, and option order sensitivity. It reveals notable insights into personality of LLM: 1) LLMs exhibit distinct and consistent personality, which is highly influenced by their training data (i.e., data used for alignment tuning), and 2) current prompting techniques have limited effectiveness in eliciting certain traits, such as high psychopathy or low conscientiousness, suggesting the need for further research in this direction.
Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation
Sep 26, 2023



Text-to-image generative models have garnered immense attention for their ability to produce high-fidelity images from text prompts. Among these, Stable Diffusion distinguishes itself as a leading open-source model in this fast-growing field. However, the intricacies of fine-tuning these models pose multiple challenges from new methodology integration to systematic evaluation. Addressing these issues, this paper introduces LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) [https://github.com/KohakuBlueleaf/LyCORIS], an open-source library that offers a wide selection of fine-tuning methodologies for Stable Diffusion. Furthermore, we present a thorough framework for the systematic assessment of varied fine-tuning techniques. This framework employs a diverse suite of metrics and delves into multiple facets of fine-tuning, including hyperparameter adjustments and the evaluation with different prompt types across various concept categories. Through this comprehensive approach, our work provides essential insights into the nuanced effects of fine-tuning parameters, bridging the gap between state-of-the-art research and practical application.