 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIPO: Text to Image with Text Presampling for Prompt Optimization
Nov 12, 2024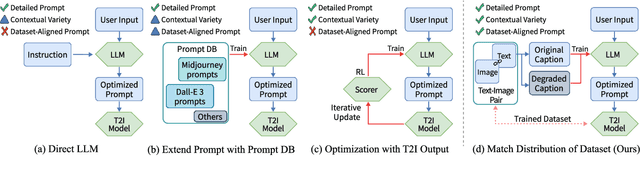

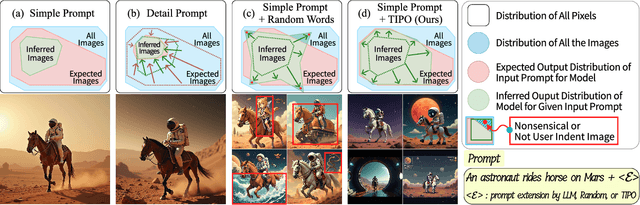
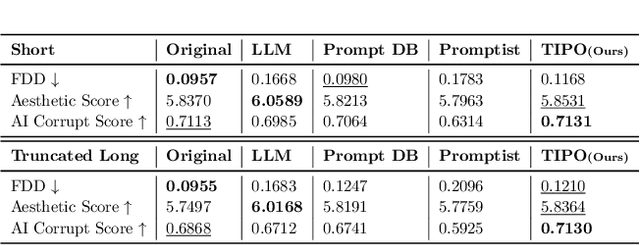
TIPO (Text to Image with text pre-sampling for Prompt Optimization) is an innovative framework designed to enhance text-to-image (T2I) generation by language model (LM) for automatic prompt engineering. By refining and extending user-provided prompts, TIPO bridges the gap between simple inputs and the detailed prompts required for high-quality image generation. Unlike previous approaches that rely on Large Language Models (LLMs) or reinforcement learning (RL), TIPO adjusts user input prompts with the distribution of a trained prompt dataset, eliminating the need for complex runtime cost via lightweight model. This pre-sampling approach enables efficient and scalable prompt optimization, grounded in the model's training distribution. Experimental results demonstrate TIPO's effectiveness in improving aesthetic scores, reducing image corruption, and better aligning generated images with dataset distributions. These findings highlight the critical role of prompt engineering in T2I systems and open avenues for broader applications of automatic prompt refinement.
Graph-Based Captioning: Enhancing Visual Descriptions by Interconnecting Region Captions
Jul 09, 2024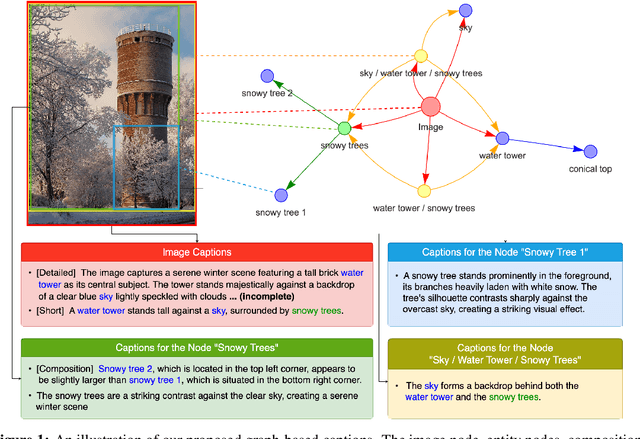

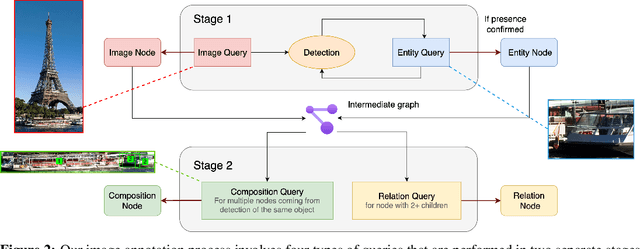

Humans describe complex scenes with compositionality, using simple text descriptions enriched with links and relationships. While vision-language research has aimed to develop models with compositional understanding capabilities, this is not reflected yet in existing datasets which, for the most part, still use plain text to describe images. In this work, we propose a new annotation strategy, graph-based captioning (GBC) that describes an image using a labelled graph structure, with nodes of various types. The nodes in GBC are created using, in a first stage, object detection and dense captioning tools nested recursively to uncover and describe entity nodes, further linked together in a second stage by highlighting, using new types of nodes, compositions and relations among entities. Since all GBC nodes hold plain text descriptions, GBC retains the flexibility found in natural language, but can also encode hierarchical information in its edges. We demonstrate that GBC can be produced automatically, using off-the-shelf multimodal LLMs and open-vocabulary detection models, by building a new dataset, GBC10M, gathering GBC annotations for about 10M images of the CC12M dataset. We use GBC10M to showcase the wealth of node captions uncovered by GBC, as measured with CLIP training. We show that using GBC nodes' annotations -- notably those stored in composition and relation nodes -- results in significant performance boost on downstream models when compared to other dataset formats. To further explore the opportunities provided by GBC, we also propose a new attention mechanism that can leverage the entire GBC graph, with encouraging experimental results that show the extra benefits of incorporating the graph structure. Our datasets are released at \url{https://huggingface.co/graph-based-captions}.