 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple ReFlow: Improved Techniques for Fast Flow Models
Oct 10, 2024



Diffusion and flow-matching models achieve remarkable generative performance but at the cost of many sampling steps, this slows inference and limits applicability to time-critical tasks. The ReFlow procedure can accelerate sampling by straightening generation trajectories. However, ReFlow is an iterative procedure, typically requiring training on simulated data, and results in reduced sample quality. To mitigate sample deterioration, we examine the design space of ReFlow and highlight potential pitfalls in prior heuristic practices. We then propose seven improvements for training dynamics, learning and inference, which are verified with thorough ablation studies on CIFAR10 $32 \times 32$, AFHQv2 $64 \times 64$, and FFHQ $64 \times 64$. Combining all our techniques, we achieve state-of-the-art FID scores (without / with guidance, resp.) for fast generation via neural ODEs: $2.23$ / $1.98$ on CIFAR10, $2.30$ / $1.91$ on AFHQv2, $2.84$ / $2.67$ on FFHQ, and $3.49$ / $1.74$ on ImageNet-64, all with merely $9$ neural function evaluations.
Graph-Based Captioning: Enhancing Visual Descriptions by Interconnecting Region Captions
Jul 09, 2024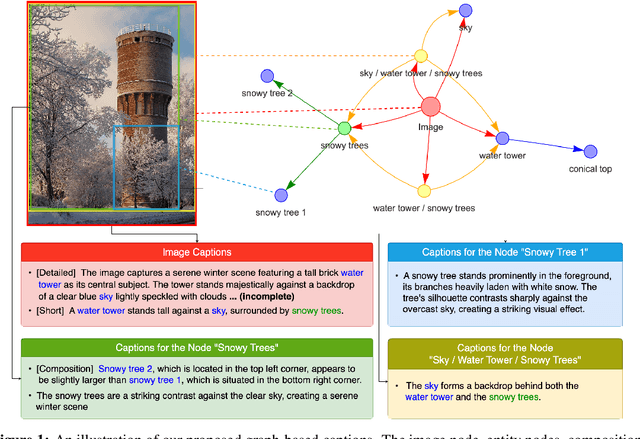

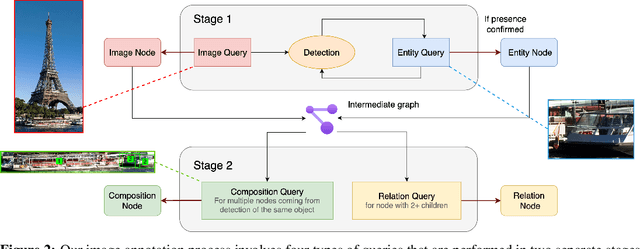

Humans describe complex scenes with compositionality, using simple text descriptions enriched with links and relationships. While vision-language research has aimed to develop models with compositional understanding capabilities, this is not reflected yet in existing datasets which, for the most part, still use plain text to describe images. In this work, we propose a new annotation strategy, graph-based captioning (GBC) that describes an image using a labelled graph structure, with nodes of various types. The nodes in GBC are created using, in a first stage, object detection and dense captioning tools nested recursively to uncover and describe entity nodes, further linked together in a second stage by highlighting, using new types of nodes, compositions and relations among entities. Since all GBC nodes hold plain text descriptions, GBC retains the flexibility found in natural language, but can also encode hierarchical information in its edges. We demonstrate that GBC can be produced automatically, using off-the-shelf multimodal LLMs and open-vocabulary detection models, by building a new dataset, GBC10M, gathering GBC annotations for about 10M images of the CC12M dataset. We use GBC10M to showcase the wealth of node captions uncovered by GBC, as measured with CLIP training. We show that using GBC nodes' annotations -- notably those stored in composition and relation nodes -- results in significant performance boost on downstream models when compared to other dataset formats. To further explore the opportunities provided by GBC, we also propose a new attention mechanism that can leverage the entire GBC graph, with encouraging experimental results that show the extra benefits of incorporating the graph structure. Our datasets are released at \url{https://huggingface.co/graph-based-captions}.
Careful with that Scalpel: Improving Gradient Surgery with an EMA
Feb 05, 2024



Beyond minimizing a single training loss, many deep learning estimation pipelines rely on an auxiliary objective to quantify and encourage desirable properties of the model (e.g. performance on another dataset, robustness, agreement with a prior). Although the simplest approach to incorporating an auxiliary loss is to sum it with the training loss as a regularizer, recent works have shown that one can improve performance by blending the gradients beyond a simple sum; this is known as gradient surgery. We cast the problem as a constrained minimization problem where the auxiliary objective is minimized among the set of minimizers of the training loss. To solve this bilevel problem, we follow a parameter update direction that combines the training loss gradient and the orthogonal projection of the auxiliary gradient to the training gradient. In a setting where gradients come from mini-batches, we explain how, using a moving average of the training loss gradients, we can carefully maintain this critical orthogonality property. We demonstrate that our method, Bloop, can lead to much better performances on NLP and vision experiments than other gradient surgery methods without EMA.
Navigating Text-To-Image Customization:From LyCORIS Fine-Tuning to Model Evaluation
Sep 26, 2023



Text-to-image generative models have garnered immense attention for their ability to produce high-fidelity images from text prompts. Among these, Stable Diffusion distinguishes itself as a leading open-source model in this fast-growing field. However, the intricacies of fine-tuning these models pose multiple challenges from new methodology integration to systematic evaluation. Addressing these issues, this paper introduces LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) [https://github.com/KohakuBlueleaf/LyCORIS], an open-source library that offers a wide selection of fine-tuning methodologies for Stable Diffusion. Furthermore, we present a thorough framework for the systematic assessment of varied fine-tuning techniques. This framework employs a diverse suite of metrics and delves into multiple facets of fine-tuning, including hyperparameter adjustments and the evaluation with different prompt types across various concept categories. Through this comprehensive approach, our work provides essential insights into the nuanced effects of fine-tuning parameters, bridging the gap between state-of-the-art research and practical application.
Thompson Sampling with Diffusion Generative Prior
Jan 12, 2023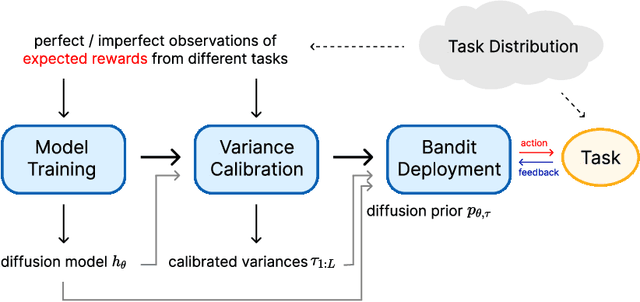
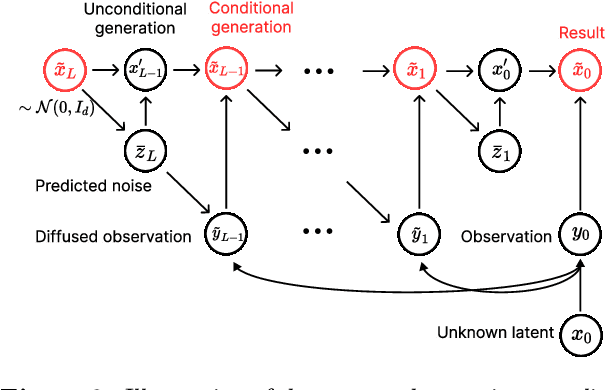
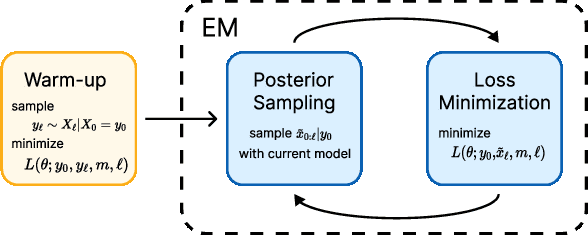
In this work, we initiate the idea of using denoising diffusion models to learn priors for online decision making problems. Our special focus is on the meta-learning for bandit framework, with the goal of learning a strategy that performs well across bandit tasks of a same class. To this end, we train a diffusion model that learns the underlying task distribution and combine Thompson sampling with the learned prior to deal with new tasks at test time. Our posterior sampling algorithm is designed to carefully balance between the learned prior and the noisy observations that come from the learner's interaction with the environment. To capture realistic bandit scenarios, we also propose a novel diffusion model training procedure that trains even from incomplete and/or noisy data, which could be of independent interest. Finally, our extensive experimental evaluations clearly demonstrate the potential of the proposed approach.
No-Regret Learning in Games with Noisy Feedback: Faster Rates and Adaptivity via Learning Rate Separation
Jun 13, 2022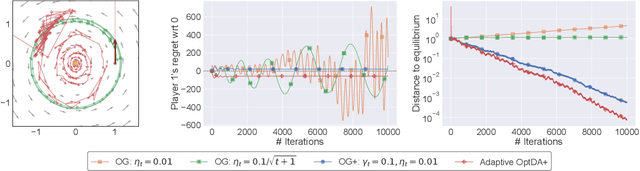


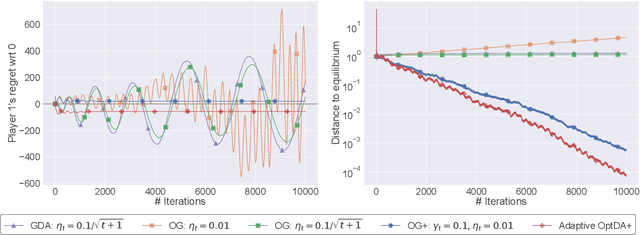
We examine the problem of regret minimization when the learner is involved in a continuous game with other optimizing agents: in this case, if all players follow a no-regret algorithm, it is possible to achieve significantly lower regret relative to fully adversarial environments. We study this problem in the context of variationally stable games (a class of continuous games which includes all convex-concave and monotone games), and when the players only have access to noisy estimates of their individual payoff gradients. If the noise is additive, the game-theoretic and purely adversarial settings enjoy similar regret guarantees; however, if the noise is multiplicative, we show that the learners can, in fact, achieve constant regret. We achieve this faster rate via an optimistic gradient scheme with learning rate separation -- that is, the method's extrapolation and update steps are tuned to different schedules, depending on the noise profile. Subsequently, to eliminate the need for delicate hyperparameter tuning, we propose a fully adaptive method that smoothly interpolates between worst- and best-case regret guarantees.
Push--Pull with Device Sampling
Jun 08, 2022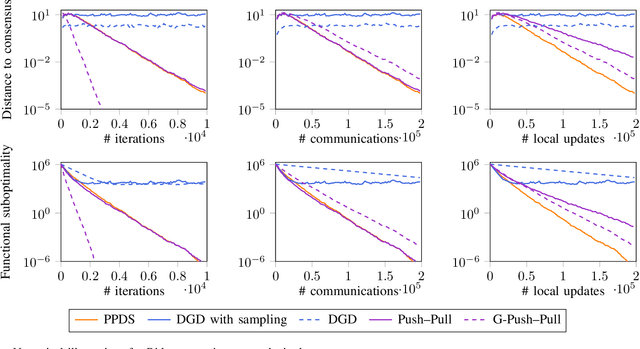
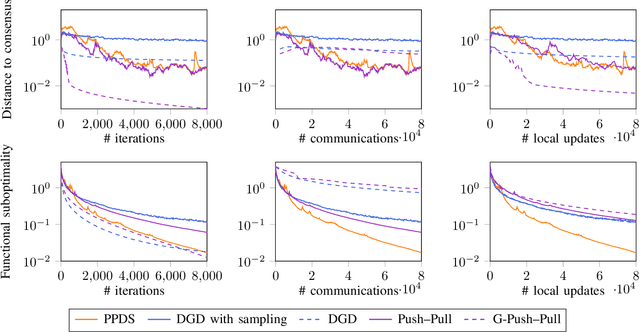
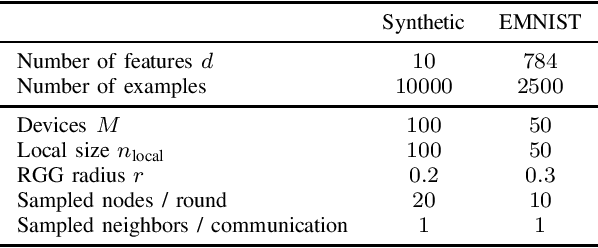
We consider decentralized optimization problems in which a number of agents collaborate to minimize the average of their local functions by exchanging over an underlying communication graph. Specifically, we place ourselves in an asynchronous model where only a random portion of nodes perform computation at each iteration, while the information exchange can be conducted between all the nodes and in an asymmetric fashion. For this setting, we propose an algorithm that combines gradient tracking and variance reduction over the entire network. This enables each node to track the average of the gradients of the objective functions. Our theoretical analysis shows that the algorithm converges linearly, when the local objective functions are strongly convex, under mild connectivity conditions on the expected mixing matrices. In particular, our result does not require the mixing matrices to be doubly stochastic. In the experiments, we investigate a broadcast mechanism that transmits information from computing nodes to their neighbors, and confirm the linear convergence of our method on both synthetic and real-world datasets.
Uplifting Bandits
Jun 08, 2022
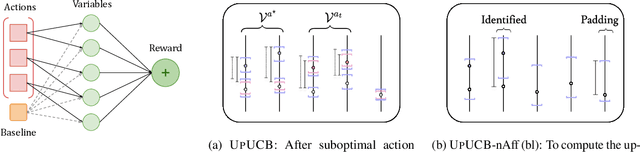

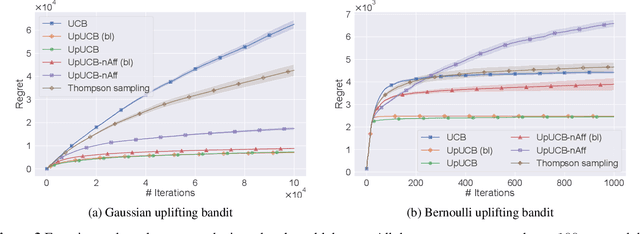
We introduce a multi-armed bandit model where the reward is a sum of multiple random variables, and each action only alters the distributions of some of them. After each action, the agent observes the realizations of all the variables. This model is motivated by marketing campaigns and recommender systems, where the variables represent outcomes on individual customers, such as clicks. We propose UCB-style algorithms that estimate the uplifts of the actions over a baseline. We study multiple variants of the problem, including when the baseline and affected variables are unknown, and prove sublinear regret bounds for all of these. We also provide lower bounds that justify the necessity of our modeling assumptions. Experiments on synthetic and real-world datasets show the benefit of methods that estimate the uplifts over policies that do not use this structure.
Optimization in Open Networks via Dual Averaging
May 27, 2021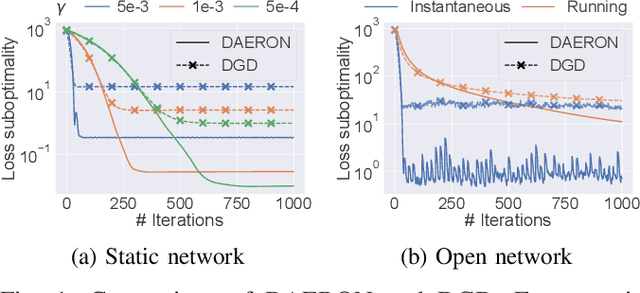
In networks of autonomous agents (e.g., fleets of vehicles, scattered sensors), the problem of minimizing the sum of the agents' local functions has received a lot of interest. We tackle here this distributed optimization problem in the case of open networks when agents can join and leave the network at any time. Leveraging recent online optimization techniques, we propose and analyze the convergence of a decentralized asynchronous optimization method for open networks.
Adaptive Learning in Continuous Games: Optimal Regret Bounds and Convergence to Nash Equilibrium
Apr 26, 2021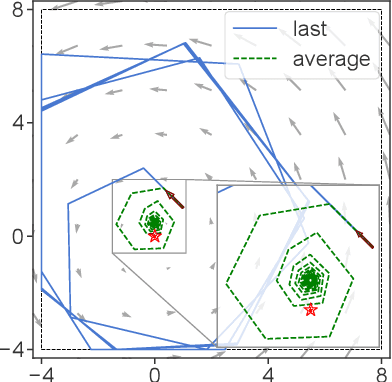

In game-theoretic learning, several agents are simultaneously following their individual interests, so the environment is non-stationary from each player's perspective. In this context, the performance of a learning algorithm is often measured by its regret. However, no-regret algorithms are not created equal in terms of game-theoretic guarantees: depending on how they are tuned, some of them may drive the system to an equilibrium, while others could produce cyclic, chaotic, or otherwise divergent trajectories. To account for this, we propose a range of no-regret policies based on optimistic mirror descent, with the following desirable properties: i) they do not require any prior tuning or knowledge of the game; ii) they all achieve O(\sqrt{T}) regret against arbitrary, adversarial opponents; and iii) they converge to the best response against convergent opponents. Also, if employed by all players, then iv) they guarantee O(1) social regret; while v) the induced sequence of play converges to Nash equilibrium with O(1) individual regret in all variationally stable games (a class of games that includes all monotone and convex-concave zero-sum games).