 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaCy: What Small Language Models Can and Should Learn is Not Just a Question of Loss
Feb 13, 2026Language models have consistently grown to compress more world knowledge into their parameters, but the knowledge that can be pretrained into them is upper-bounded by their parameter size. Especially the capacity of Small Language Models (SLMs) is limited, leading to factually incorrect generations. This problem is often mitigated by giving the SLM access to an outside source: the ability to query a larger model, documents, or a database. Under this setting, we study the fundamental question of \emph{which tokens an SLM can and should learn} during pretraining, versus \emph{which ones it should delegate} via a \texttt{<CALL>} token. We find that this is not simply a question of loss: although the loss is predictive of whether a predicted token mismatches the ground-truth, some tokens are \emph{acceptable} in that they are truthful alternative continuations of a pretraining document, and should not trigger a \texttt{<CALL>} even if their loss is high. We find that a spaCy grammar parser can help augment the loss signal to decide which tokens the SLM should learn to delegate to prevent factual errors and which are safe to learn and predict even under high losses. We propose LaCy, a novel pretraining method based on this token selection philosophy. Our experiments demonstrate that LaCy models successfully learn which tokens to predict and where to delegate for help. This results in higher FactScores when generating in a cascade with a bigger model and outperforms Rho or LLM-judge trained SLMs, while being simpler and cheaper.
Completed Hyperparameter Transfer across Modules, Width, Depth, Batch and Duration
Dec 26, 2025Hyperparameter tuning can dramatically impact training stability and final performance of large-scale models. Recent works on neural network parameterisations, such as $μ$P, have enabled transfer of optimal global hyperparameters across model sizes. These works propose an empirical practice of search for optimal global base hyperparameters at a small model size, and transfer to a large size. We extend these works in two key ways. To handle scaling along most important scaling axes, we propose the Complete$^{(d)}$ Parameterisation that unifies scaling in width and depth -- using an adaptation of CompleteP -- as well as in batch-size and training duration. Secondly, with our parameterisation, we investigate per-module hyperparameter optimisation and transfer. We characterise the empirical challenges of navigating the high-dimensional hyperparameter landscape, and propose practical guidelines for tackling this optimisation problem. We demonstrate that, with the right parameterisation, hyperparameter transfer holds even in the per-module hyperparameter regime. Our study covers an extensive range of optimisation hyperparameters of modern models: learning rates, AdamW parameters, weight decay, initialisation scales, and residual block multipliers. Our experiments demonstrate significant training speed improvements in Large Language Models with the transferred per-module hyperparameters.
Learning Unmasking Policies for Diffusion Language Models
Dec 12, 2025Diffusion (Large) Language Models (dLLMs) now match the downstream performance of their autoregressive counterparts on many tasks, while holding the promise of being more efficient during inference. One particularly successful variant is masked discrete diffusion, in which a buffer filled with special mask tokens is progressively replaced with tokens sampled from the model's vocabulary. Efficiency can be gained by unmasking several tokens in parallel, but doing too many at once risks degrading the generation quality. Thus, one critical design aspect of dLLMs is the sampling procedure that selects, at each step of the diffusion process, which tokens to replace. Indeed, recent work has found that heuristic strategies such as confidence thresholding lead to both higher quality and token throughput compared to random unmasking. However, such heuristics have downsides: they require manual tuning, and we observe that their performance degrades with larger buffer sizes. In this work, we instead propose to train sampling procedures using reinforcement learning. Specifically, we formalize masked diffusion sampling as a Markov decision process in which the dLLM serves as the environment, and propose a lightweight policy architecture based on a single-layer transformer that maps dLLM token confidences to unmasking decisions. Our experiments show that these trained policies match the performance of state-of-the-art heuristics when combined with semi-autoregressive generation, while outperforming them in the full diffusion setting. We also examine the transferability of these policies, finding that they can generalize to new underlying dLLMs and longer sequence lengths. However, we also observe that their performance degrades when applied to out-of-domain data, and that fine-grained tuning of the accuracy-efficiency trade-off can be challenging with our approach.
Follow the Energy, Find the Path: Riemannian Metrics from Energy-Based Models
May 23, 2025What is the shortest path between two data points lying in a high-dimensional space? While the answer is trivial in Euclidean geometry, it becomes significantly more complex when the data lies on a curved manifold -- requiring a Riemannian metric to describe the space's local curvature. Estimating such a metric, however, remains a major challenge in high dimensions. In this work, we propose a method for deriving Riemannian metrics directly from pretrained Energy-Based Models (EBMs) -- a class of generative models that assign low energy to high-density regions. These metrics define spatially varying distances, enabling the computation of geodesics -- shortest paths that follow the data manifold's intrinsic geometry. We introduce two novel metrics derived from EBMs and show that they produce geodesics that remain closer to the data manifold and exhibit lower curvature distortion, as measured by alignment with ground-truth trajectories. We evaluate our approach on increasingly complex datasets: synthetic datasets with known data density, rotated character images with interpretable geometry, and high-resolution natural images embedded in a pretrained VAE latent space. Our results show that EBM-derived metrics consistently outperform established baselines, especially in high-dimensional settings. Our work is the first to derive Riemannian metrics from EBMs, enabling data-aware geodesics and unlocking scalable, geometry-driven learning for generative modeling and simulation.
Deep Sturm--Liouville: From Sample-Based to 1D Regularization with Learnable Orthogonal Basis Functions
Apr 09, 2025Although Artificial Neural Networks (ANNs) have achieved remarkable success across various tasks, they still suffer from limited generalization. We hypothesize that this limitation arises from the traditional sample-based (0--dimensionnal) regularization used in ANNs. To overcome this, we introduce \textit{Deep Sturm--Liouville} (DSL), a novel function approximator that enables continuous 1D regularization along field lines in the input space by integrating the Sturm--Liouville Theorem (SLT) into the deep learning framework. DSL defines field lines traversing the input space, along which a Sturm--Liouville problem is solved to generate orthogonal basis functions, enforcing implicit regularization thanks to the desirable properties of SLT. These basis functions are linearly combined to construct the DSL approximator. Both the vector field and basis functions are parameterized by neural networks and learned jointly. We demonstrate that the DSL formulation naturally arises when solving a Rank-1 Parabolic Eigenvalue Problem. DSL is trained efficiently using stochastic gradient descent via implicit differentiation. DSL achieves competitive performance and demonstrate improved sample efficiency on diverse multivariate datasets including high-dimensional image datasets such as MNIST and CIFAR-10.
Sample and Map from a Single Convex Potential: Generation using Conjugate Moment Measures
Mar 13, 2025A common approach to generative modeling is to split model-fitting into two blocks: define first how to sample noise (e.g. Gaussian) and choose next what to do with it (e.g. using a single map or flows). We explore in this work an alternative route that ties sampling and mapping. We find inspiration in moment measures, a result that states that for any measure $\rho$ supported on a compact convex set of $\mathbb{R}^d$, there exists a unique convex potential $u$ such that $\rho=\nabla u\,\sharp\,e^{-u}$. While this does seem to tie effectively sampling (from log-concave distribution $e^{-u}$) and action (pushing particles through $\nabla u$), we observe on simple examples (e.g., Gaussians or 1D distributions) that this choice is ill-suited for practical tasks. We study an alternative factorization, where $\rho$ is factorized as $\nabla w^*\,\sharp\,e^{-w}$, where $w^*$ is the convex conjugate of $w$. We call this approach conjugate moment measures, and show far more intuitive results on these examples. Because $\nabla w^*$ is the Monge map between the log-concave distribution $e^{-w}$ and $\rho$, we rely on optimal transport solvers to propose an algorithm to recover $w$ from samples of $\rho$, and parameterize $w$ as an input-convex neural network.
Multimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Sparse Repellency for Shielded Generation in Text-to-image Diffusion Models
Oct 10, 2024
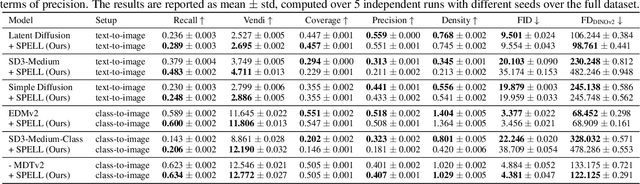
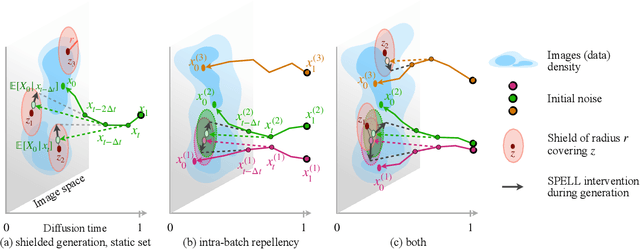
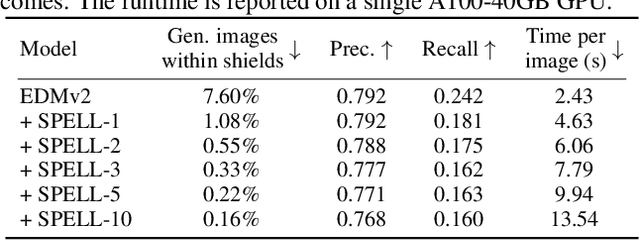
The increased adoption of diffusion models in text-to-image generation has triggered concerns on their reliability. Such models are now closely scrutinized under the lens of various metrics, notably calibration, fairness, or compute efficiency. We focus in this work on two issues that arise when deploying these models: a lack of diversity when prompting images, and a tendency to recreate images from the training set. To solve both problems, we propose a method that coaxes the sampled trajectories of pretrained diffusion models to land on images that fall outside of a reference set. We achieve this by adding repellency terms to the diffusion SDE throughout the generation trajectory, which are triggered whenever the path is expected to land too closely to an image in the shielded reference set. Our method is sparse in the sense that these repellency terms are zero and inactive most of the time, and even more so towards the end of the generation trajectory. Our method, named SPELL for sparse repellency, can be used either with a static reference set that contains protected images, or dynamically, by updating the set at each timestep with the expected images concurrently generated within a batch. We show that adding SPELL to popular diffusion models improves their diversity while impacting their FID only marginally, and performs comparatively better than other recent training-free diversity methods. We also demonstrate how SPELL can ensure a shielded generation away from a very large set of protected images by considering all 1.2M images from ImageNet as the protected set.
Graph-Based Captioning: Enhancing Visual Descriptions by Interconnecting Region Captions
Jul 09, 2024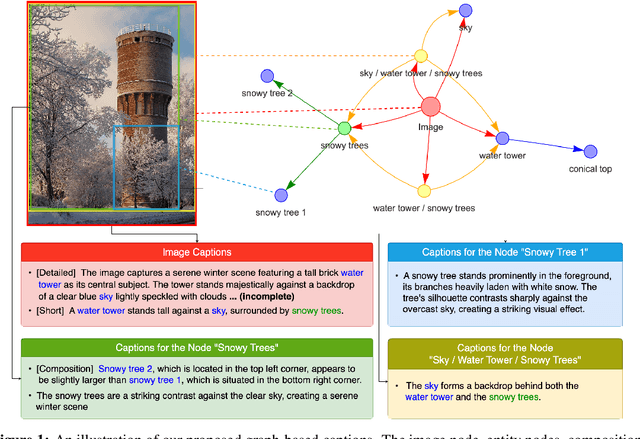

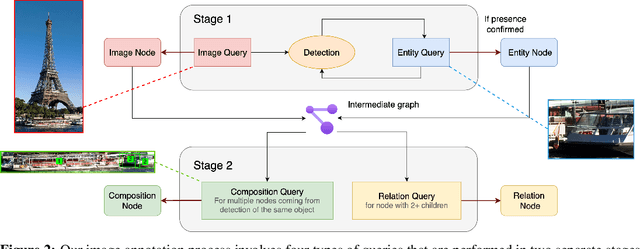

Humans describe complex scenes with compositionality, using simple text descriptions enriched with links and relationships. While vision-language research has aimed to develop models with compositional understanding capabilities, this is not reflected yet in existing datasets which, for the most part, still use plain text to describe images. In this work, we propose a new annotation strategy, graph-based captioning (GBC) that describes an image using a labelled graph structure, with nodes of various types. The nodes in GBC are created using, in a first stage, object detection and dense captioning tools nested recursively to uncover and describe entity nodes, further linked together in a second stage by highlighting, using new types of nodes, compositions and relations among entities. Since all GBC nodes hold plain text descriptions, GBC retains the flexibility found in natural language, but can also encode hierarchical information in its edges. We demonstrate that GBC can be produced automatically, using off-the-shelf multimodal LLMs and open-vocabulary detection models, by building a new dataset, GBC10M, gathering GBC annotations for about 10M images of the CC12M dataset. We use GBC10M to showcase the wealth of node captions uncovered by GBC, as measured with CLIP training. We show that using GBC nodes' annotations -- notably those stored in composition and relation nodes -- results in significant performance boost on downstream models when compared to other dataset formats. To further explore the opportunities provided by GBC, we also propose a new attention mechanism that can leverage the entire GBC graph, with encouraging experimental results that show the extra benefits of incorporating the graph structure. Our datasets are released at \url{https://huggingface.co/graph-based-captions}.
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Dec 11, 2023
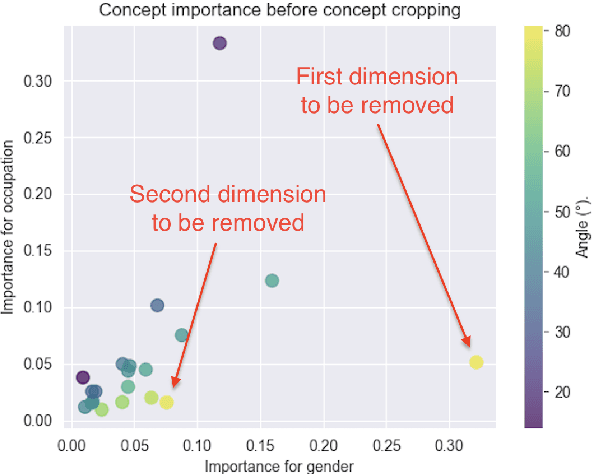
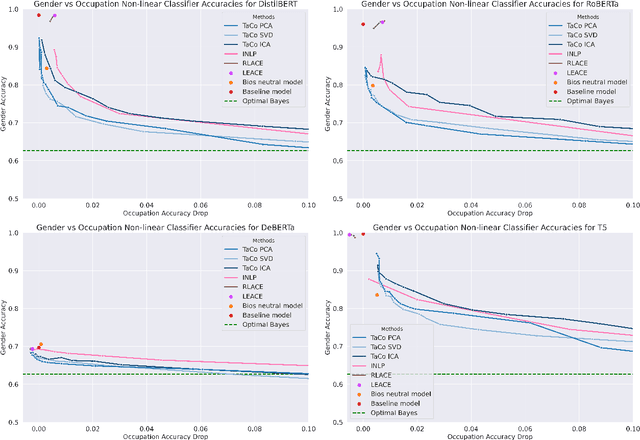
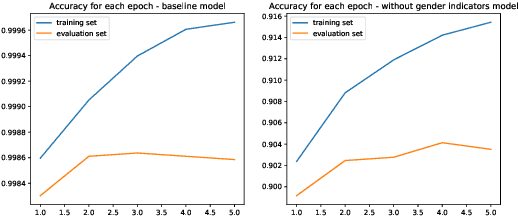
The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo