 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Redundancy and the Geometry of Vision-Language Embeddings
Feb 05, 2026Vision-language models (VLMs) align images and text with remarkable success, yet the geometry of their shared embedding space remains poorly understood. To probe this geometry, we begin from the Iso-Energy Assumption, which exploits cross-modal redundancy: a concept that is truly shared should exhibit the same average energy across modalities. We operationalize this assumption with an Aligned Sparse Autoencoder (SAE) that encourages energy consistency during training while preserving reconstruction. We find that this inductive bias changes the SAE solution without harming reconstruction, giving us a representation that serves as a tool for geometric analysis. Sanity checks on controlled data with known ground truth confirm that alignment improves when Iso-Energy holds and remains neutral when it does not. Applied to foundational VLMs, our framework reveals a clear structure with practical consequences: (i) sparse bimodal atoms carry the entire cross-modal alignment signal; (ii) unimodal atoms act as modality-specific biases and fully explain the modality gap; (iii) removing unimodal atoms collapses the gap without harming performance; (iv) restricting vector arithmetic to the bimodal subspace yields in-distribution edits and improved retrieval. These findings suggest that the right inductive bias can both preserve model fidelity and render the latent geometry interpretable and actionable.
TaCo: Targeted Concept Removal in Output Embeddings for NLP via Information Theory and Explainability
Dec 11, 2023
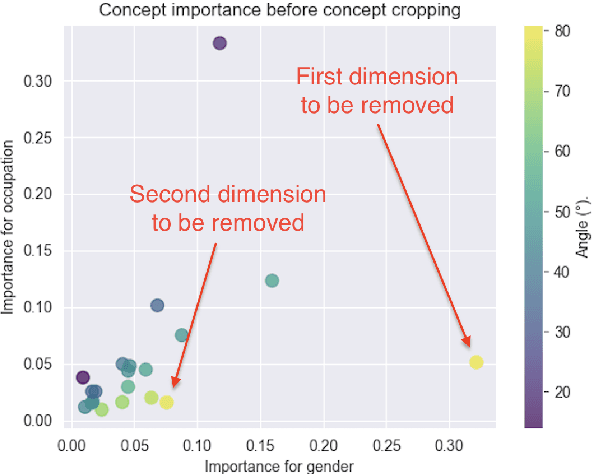
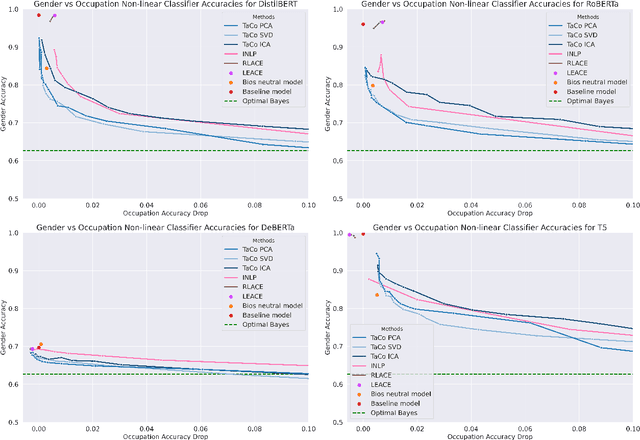
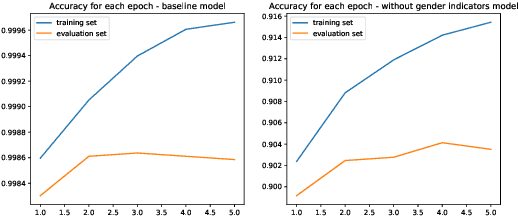
The fairness of Natural Language Processing (NLP) models has emerged as a crucial concern. Information theory indicates that to achieve fairness, a model should not be able to predict sensitive variables, such as gender, ethnicity, and age. However, information related to these variables often appears implicitly in language, posing a challenge in identifying and mitigating biases effectively. To tackle this issue, we present a novel approach that operates at the embedding level of an NLP model, independent of the specific architecture. Our method leverages insights from recent advances in XAI techniques and employs an embedding transformation to eliminate implicit information from a selected variable. By directly manipulating the embeddings in the final layer, our approach enables a seamless integration into existing models without requiring significant modifications or retraining. In evaluation, we show that the proposed post-hoc approach significantly reduces gender-related associations in NLP models while preserving the overall performance and functionality of the models. An implementation of our method is available: https://github.com/fanny-jourdan/TaCo
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
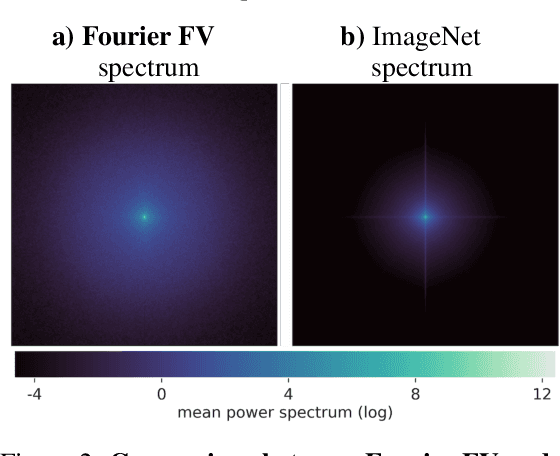
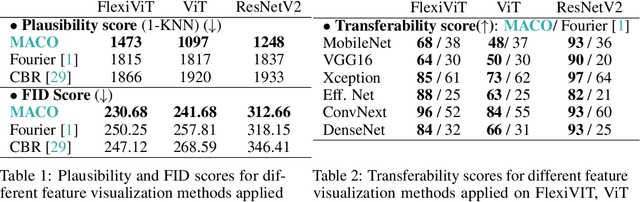
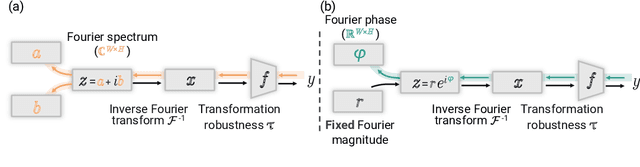
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
COCKATIEL: COntinuous Concept ranKed ATtribution with Interpretable ELements for explaining neural net classifiers on NLP tasks
May 14, 2023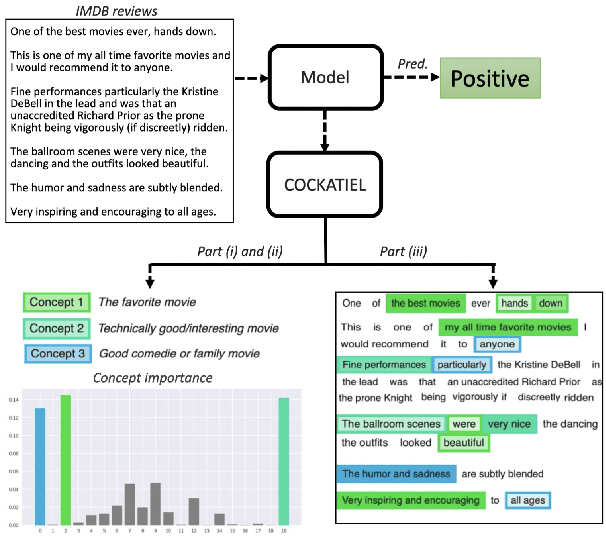
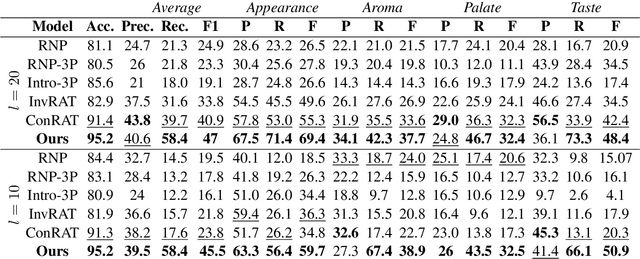
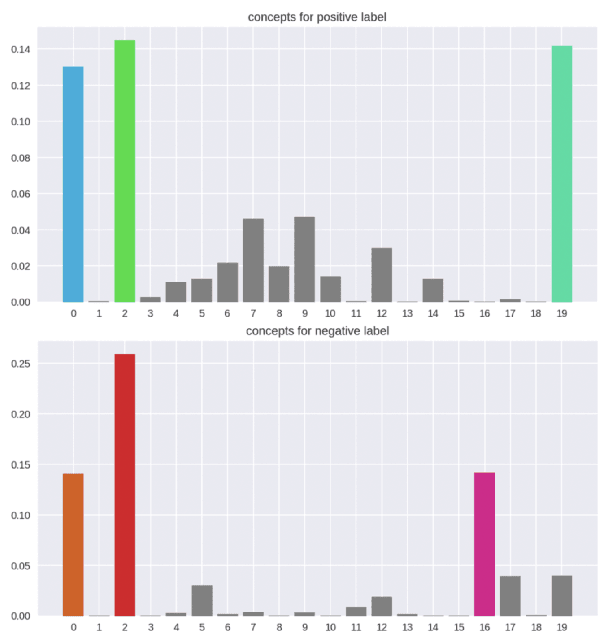
Transformer architectures are complex and their use in NLP, while it has engendered many successes, makes their interpretability or explainability challenging. Recent debates have shown that attention maps and attribution methods are unreliable (Pruthi et al., 2019; Brunner et al., 2019). In this paper, we present some of their limitations and introduce COCKATIEL, which successfully addresses some of them. COCKATIEL is a novel, post-hoc, concept-based, model-agnostic XAI technique that generates meaningful explanations from the last layer of a neural net model trained on an NLP classification task by using Non-Negative Matrix Factorization (NMF) to discover the concepts the model leverages to make predictions and by exploiting a Sensitivity Analysis to estimate accurately the importance of each of these concepts for the model. It does so without compromising the accuracy of the underlying model or requiring a new one to be trained. We conduct experiments in single and multi-aspect sentiment analysis tasks and we show COCKATIEL's superior ability to discover concepts that align with humans' on Transformer models without any supervision, we objectively verify the faithfulness of its explanations through fidelity metrics, and we showcase its ability to provide meaningful explanations in two different datasets.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022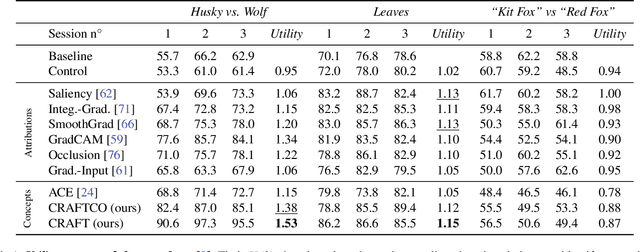

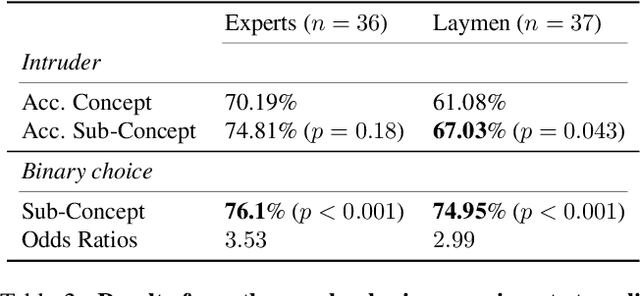
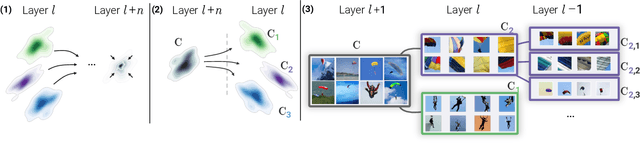
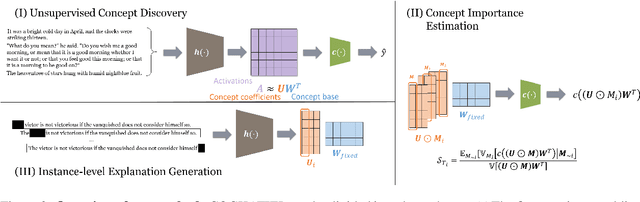
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
A survey of Identification and mitigation of Machine Learning algorithmic biases in Image Analysis
Oct 10, 2022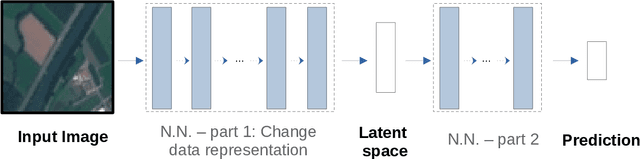


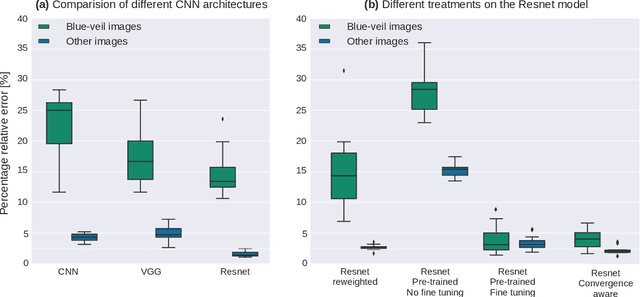
The problem of algorithmic bias in machine learning has gained a lot of attention in recent years due to its concrete and potentially hazardous implications in society. In much the same manner, biases can also alter modern industrial and safety-critical applications where machine learning are based on high dimensional inputs such as images. This issue has however been mostly left out of the spotlight in the machine learning literature. Contrarily to societal applications where a set of proxy variables can be provided by the common sense or by regulations to draw the attention on potential risks, industrial and safety-critical applications are most of the times sailing blind. The variables related to undesired biases can indeed be indirectly represented in the input data, or can be unknown, thus making them harder to tackle. This raises serious and well-founded concerns towards the commercial deployment of AI-based solutions, especially in a context where new regulations clearly address the issues opened by undesired biases in AI. Consequently, we propose here to make an overview of recent advances in this area, firstly by presenting how such biases can demonstrate themselves, then by exploring different ways to bring them to light, and by probing different possibilities to mitigate them. We finally present a practical remote sensing use-case of industrial Fairness.
Xplique: A Deep Learning Explainability Toolbox
Jun 09, 2022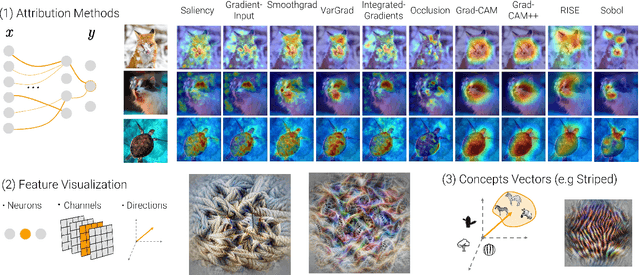
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.