 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaMiCS: Fine-tuning LLMs with Performance Constraints using Dynamic Mixtures
May 11, 2026Multi-domain fine-tuning of large language models requires improving performance on target domains while preserving performance on constrained domains, such as general knowledge, instruction following, or safety evaluations. Existing data mixing strategies rely on fixed heuristics or adaptive rules that cannot explicitly enforce preservation of such capabilities. We propose DynaMiCS, a dynamic mixture optimizer that casts multi-domain fine-tuning as a constrained optimization problem. At each update, DynaMiCS performs short domain-specific probing runs to estimate a slope matrix of local cross-domain effects, capturing how training on each fine-tuning dataset affects each evaluation domain. These estimates are then used to compute mixture weights through optimization over the probability simplex, with the objective of improving target-domain performance while keeping constrained-domain losses below reference levels. Across multi-domain fine-tuning scenarios with varying numbers of target and constrained domains, DynaMiCS achieves stronger target-domain improvements and higher constraint satisfaction than fixed-mixture baselines, at lower computational cost and without reference models, per-example scoring, or manually tuned mixture weights.
Optimal Splitting of Language Models from Mixtures to Specialized Domains
Mar 19, 2026Language models achieve impressive performance on a variety of knowledge, language, and reasoning tasks due to the scale and diversity of pretraining data available. The standard training recipe is a two-stage paradigm: pretraining first on the full corpus of data followed by specialization on a subset of high quality, specialized data from the full corpus. In the multi-domain setting, this involves continued pretraining of multiple models on each specialized domain, referred to as split model training. We propose a method for pretraining multiple models independently over a general pretraining corpus, and determining the optimal compute allocation between pretraining and continued pretraining using scaling laws. Our approach accurately predicts the loss of a model of size N with D pretraining and D' specialization tokens, and extrapolates to larger model sizes and number of tokens. Applied to language model training, our approach improves performance consistently across common sense knowledge and reasoning benchmarks across different model sizes and compute budgets.
The Design Space of Tri-Modal Masked Diffusion Models
Feb 25, 2026Discrete diffusion models have emerged as strong alternatives to autoregressive language models, with recent work initializing and fine-tuning a base unimodal model for bimodal generation. Diverging from previous approaches, we introduce the first tri-modal masked diffusion model pretrained from scratch on text, image-text, and audio-text data. We systematically analyze multimodal scaling laws, modality mixing ratios, noise schedules, and batch-size effects, and we provide optimized inference sampling defaults. Our batch-size analysis yields a novel stochastic differential equation (SDE)-based reparameterization that eliminates the need for tuning the optimal batch size as reported in recent work. This reparameterization decouples the physical batch size, often chosen based on compute constraints (GPU saturation, FLOP efficiency, wall-clock time), from the logical batch size, chosen to balance gradient variance during stochastic optimization. Finally, we pretrain a preliminary 3B-parameter tri-modal model on 6.4T tokens, demonstrating the capabilities of a unified design and achieving strong results in text generation, text-to-image tasks, and text-to-speech tasks. Our work represents the largest-scale systematic open study of multimodal discrete diffusion models conducted to date, providing insights into scaling behaviors across multiple modalities.
The Data-Quality Illusion: Rethinking Classifier-Based Quality Filtering for LLM Pretraining
Oct 02, 2025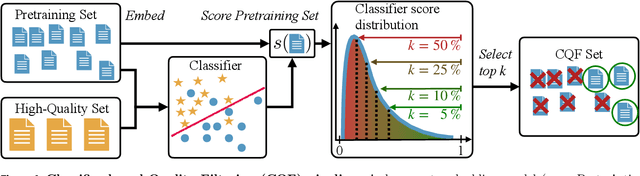
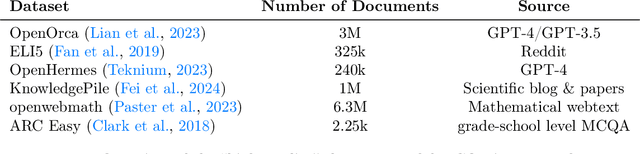
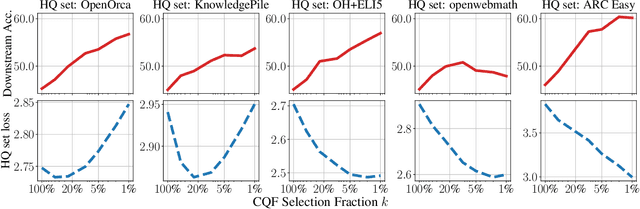
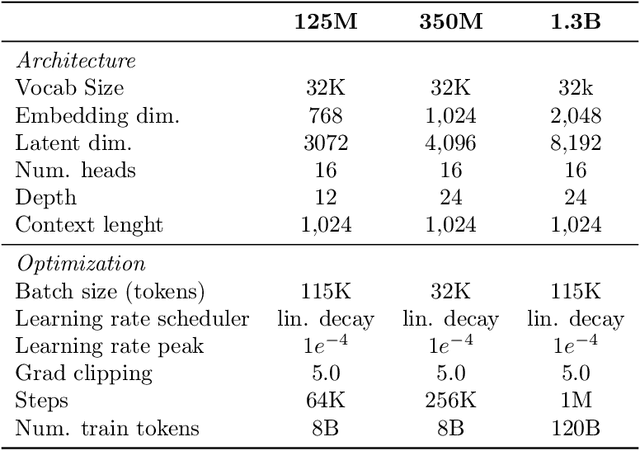
Large-scale models are pretrained on massive web-crawled datasets containing documents of mixed quality, making data filtering essential. A popular method is Classifier-based Quality Filtering (CQF), which trains a binary classifier to distinguish between pretraining data and a small, high-quality set. It assigns each pretraining document a quality score defined as the classifier's score and retains only the top-scoring ones. We provide an in-depth analysis of CQF. We show that while CQF improves downstream task performance, it does not necessarily enhance language modeling on the high-quality dataset. We explain this paradox by the fact that CQF implicitly filters the high-quality dataset as well. We further compare the behavior of models trained with CQF to those trained on synthetic data of increasing quality, obtained via random token permutations, and find starkly different trends. Our results challenge the view that CQF captures a meaningful notion of data quality.
The Geometries of Truth Are Orthogonal Across Tasks
Jun 10, 2025Large Language Models (LLMs) have demonstrated impressive generalization capabilities across various tasks, but their claim to practical relevance is still mired by concerns on their reliability. Recent works have proposed examining the activations produced by an LLM at inference time to assess whether its answer to a question is correct. Some works claim that a "geometry of truth" can be learned from examples, in the sense that the activations that generate correct answers can be distinguished from those leading to mistakes with a linear classifier. In this work, we underline a limitation of these approaches: we observe that these "geometries of truth" are intrinsically task-dependent and fail to transfer across tasks. More precisely, we show that linear classifiers trained across distinct tasks share little similarity and, when trained with sparsity-enforcing regularizers, have almost disjoint supports. We show that more sophisticated approaches (e.g., using mixtures of probes and tasks) fail to overcome this limitation, likely because activation vectors commonly used to classify answers form clearly separated clusters when examined across tasks.
Composition and Control with Distilled Energy Diffusion Models and Sequential Monte Carlo
Feb 18, 2025Diffusion models may be formulated as a time-indexed sequence of energy-based models, where the score corresponds to the negative gradient of an energy function. As opposed to learning the score directly, an energy parameterization is attractive as the energy itself can be used to control generation via Monte Carlo samplers. Architectural constraints and training instability in energy parameterized models have so far yielded inferior performance compared to directly approximating the score or denoiser. We address these deficiencies by introducing a novel training regime for the energy function through distillation of pre-trained diffusion models, resembling a Helmholtz decomposition of the score vector field. We further showcase the synergies between energy and score by casting the diffusion sampling procedure as a Feynman Kac model where sampling is controlled using potentials from the learnt energy functions. The Feynman Kac model formalism enables composition and low temperature sampling through sequential Monte Carlo.
Scaling Laws for Forgetting during Finetuning with Pretraining Data Injection
Feb 09, 2025A widespread strategy to obtain a language model that performs well on a target domain is to finetune a pretrained model to perform unsupervised next-token prediction on data from that target domain. Finetuning presents two challenges: (i) if the amount of target data is limited, as in most practical applications, the model will quickly overfit, and (ii) the model will drift away from the original model, forgetting the pretraining data and the generic knowledge that comes with it. We aim to derive scaling laws that quantify these two phenomena for various target domains, amounts of available target data, and model scales. We measure the efficiency of injecting pretraining data into the finetuning data mixture to avoid forgetting and mitigate overfitting. A key practical takeaway from our study is that injecting as little as 1% of pretraining data in the finetuning data mixture prevents the model from forgetting the pretraining set.
Multivariate Conformal Prediction using Optimal Transport
Feb 05, 2025



Conformal prediction (CP) quantifies the uncertainty of machine learning models by constructing sets of plausible outputs. These sets are constructed by leveraging a so-called conformity score, a quantity computed using the input point of interest, a prediction model, and past observations. CP sets are then obtained by evaluating the conformity score of all possible outputs, and selecting them according to the rank of their scores. Due to this ranking step, most CP approaches rely on a score functions that are univariate. The challenge in extending these scores to multivariate spaces lies in the fact that no canonical order for vectors exists. To address this, we leverage a natural extension of multivariate score ranking based on optimal transport (OT). Our method, OTCP, offers a principled framework for constructing conformal prediction sets in multidimensional settings, preserving distribution-free coverage guarantees with finite data samples. We demonstrate tangible gains in a benchmark dataset of multivariate regression problems and address computational \& statistical trade-offs that arise when estimating conformity scores through OT maps.
Understanding Visual Feature Reliance through the Lens of Complexity
Jul 08, 2024



Recent studies suggest that deep learning models inductive bias towards favoring simpler features may be one of the sources of shortcut learning. Yet, there has been limited focus on understanding the complexity of the myriad features that models learn. In this work, we introduce a new metric for quantifying feature complexity, based on $\mathscr{V}$-information and capturing whether a feature requires complex computational transformations to be extracted. Using this $\mathscr{V}$-information metric, we analyze the complexities of 10,000 features, represented as directions in the penultimate layer, that were extracted from a standard ImageNet-trained vision model. Our study addresses four key questions: First, we ask what features look like as a function of complexity and find a spectrum of simple to complex features present within the model. Second, we ask when features are learned during training. We find that simpler features dominate early in training, and more complex features emerge gradually. Third, we investigate where within the network simple and complex features flow, and find that simpler features tend to bypass the visual hierarchy via residual connections. Fourth, we explore the connection between features complexity and their importance in driving the networks decision. We find that complex features tend to be less important. Surprisingly, important features become accessible at earlier layers during training, like a sedimentation process, allowing the model to build upon these foundational elements.
A Holistic Approach to Unifying Automatic Concept Extraction and Concept Importance Estimation
Jun 11, 2023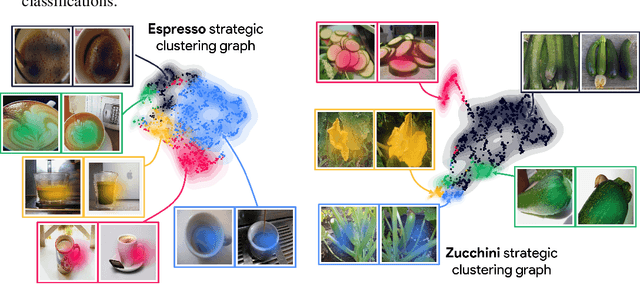


In recent years, concept-based approaches have emerged as some of the most promising explainability methods to help us interpret the decisions of Artificial Neural Networks (ANNs). These methods seek to discover intelligible visual 'concepts' buried within the complex patterns of ANN activations in two key steps: (1) concept extraction followed by (2) importance estimation. While these two steps are shared across methods, they all differ in their specific implementations. Here, we introduce a unifying theoretical framework that comprehensively defines and clarifies these two steps. This framework offers several advantages as it allows us: (i) to propose new evaluation metrics for comparing different concept extraction approaches; (ii) to leverage modern attribution methods and evaluation metrics to extend and systematically evaluate state-of-the-art concept-based approaches and importance estimation techniques; (iii) to derive theoretical guarantees regarding the optimality of such methods. We further leverage our framework to try to tackle a crucial question in explainability: how to efficiently identify clusters of data points that are classified based on a similar shared strategy. To illustrate these findings and to highlight the main strategies of a model, we introduce a visual representation called the strategic cluster graph. Finally, we present https://serre-lab.github.io/Lens, a dedicated website that offers a complete compilation of these visualizations for all classes of the ImageNet dataset.