 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal vs distributed representations: What is the right basis for interpretability?
Nov 06, 2024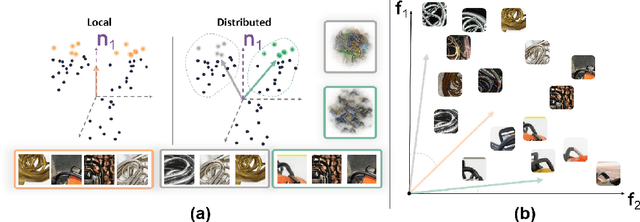


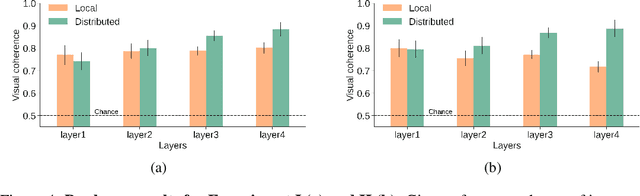
Much of the research on the interpretability of deep neural networks has focused on studying the visual features that maximally activate individual neurons. However, recent work has cast doubts on the usefulness of such local representations for understanding the behavior of deep neural networks because individual neurons tend to respond to multiple unrelated visual patterns, a phenomenon referred to as "superposition". A promising alternative to disentangle these complex patterns is learning sparsely distributed vector representations from entire network layers, as the resulting basis vectors seemingly encode single identifiable visual patterns consistently. Thus, one would expect the resulting code to align better with human perceivable visual patterns, but supporting evidence remains, at best, anecdotal. To fill this gap, we conducted three large-scale psychophysics experiments collected from a pool of 560 participants. Our findings provide (i) strong evidence that features obtained from sparse distributed representations are easier to interpret by human observers and (ii) that this effect is more pronounced in the deepest layers of a neural network. Complementary analyses also reveal that (iii) features derived from sparse distributed representations contribute more to the model's decision. Overall, our results highlight that distributed representations constitute a superior basis for interpretability, underscoring a need for the field to move beyond the interpretation of local neural codes in favor of sparsely distributed ones.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
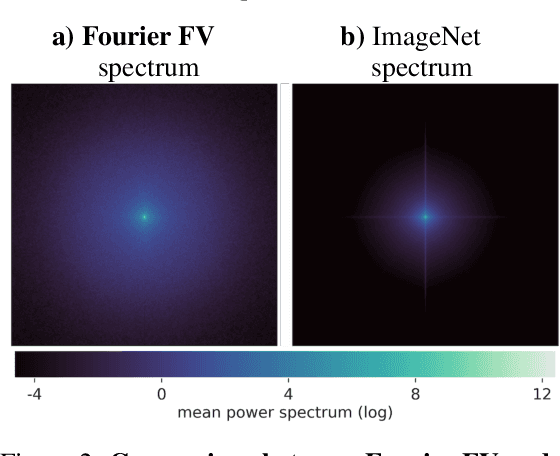
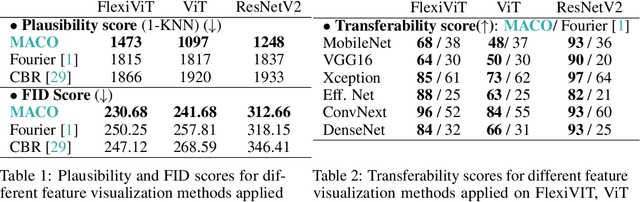
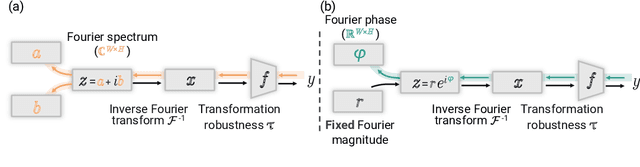
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
Diffusion Models as Artists: Are we Closing the Gap between Humans and Machines?
Jan 27, 2023



An important milestone for AI is the development of algorithms that can produce drawings that are indistinguishable from those of humans. Here, we adapt the 'diversity vs. recognizability' scoring framework from Boutin et al, 2022 and find that one-shot diffusion models have indeed started to close the gap between humans and machines. However, using a finer-grained measure of the originality of individual samples, we show that strengthening the guidance of diffusion models helps improve the humanness of their drawings, but they still fall short of approximating the originality and recognizability of human drawings. Comparing human category diagnostic features, collected through an online psychophysics experiment, against those derived from diffusion models reveals that humans rely on fewer and more localized features. Overall, our study suggests that diffusion models have significantly helped improve the quality of machine-generated drawings; however, a gap between humans and machines remains -- in part explainable by discrepancies in visual strategies.
CRAFT: Concept Recursive Activation FacTorization for Explainability
Nov 17, 2022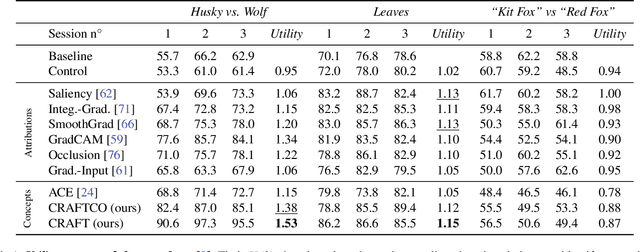

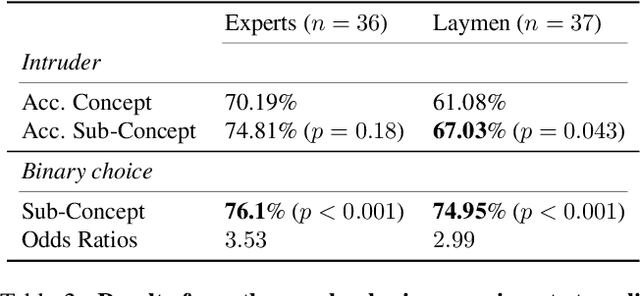
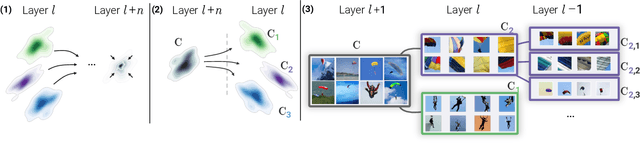
Attribution methods are a popular class of explainability methods that use heatmaps to depict the most important areas of an image that drive a model decision. Nevertheless, recent work has shown that these methods have limited utility in practice, presumably because they only highlight the most salient parts of an image (i.e., 'where' the model looked) and do not communicate any information about 'what' the model saw at those locations. In this work, we try to fill in this gap with CRAFT -- a novel approach to identify both 'what' and 'where' by generating concept-based explanations. We introduce 3 new ingredients to the automatic concept extraction literature: (i) a recursive strategy to detect and decompose concepts across layers, (ii) a novel method for a more faithful estimation of concept importance using Sobol indices, and (iii) the use of implicit differentiation to unlock Concept Attribution Maps. We conduct both human and computer vision experiments to demonstrate the benefits of the proposed approach. We show that our recursive decomposition generates meaningful and accurate concepts and that the proposed concept importance estimation technique is more faithful to the model than previous methods. When evaluating the usefulness of the method for human experimenters on a human-defined utility benchmark, we find that our approach significantly improves on two of the three test scenarios (while none of the current methods including ours help on the third). Overall, our study suggests that, while much work remains toward the development of general explainability methods that are useful in practical scenarios, the identification of meaningful concepts at the proper level of granularity yields useful and complementary information beyond that afforded by attribution methods.
A Benchmark for Compositional Visual Reasoning
Jun 11, 2022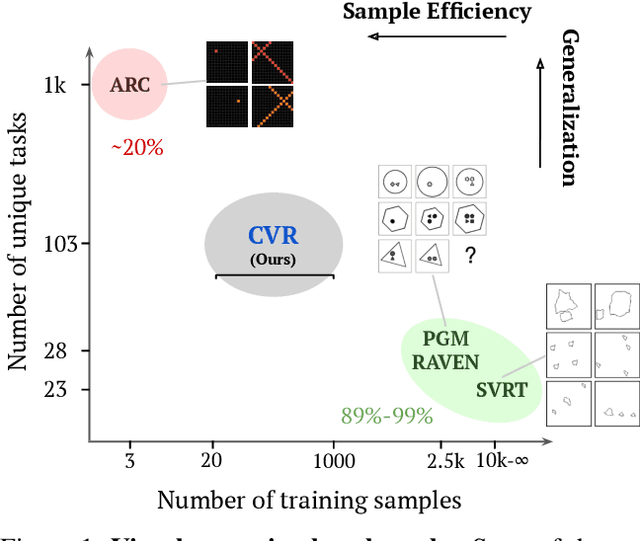
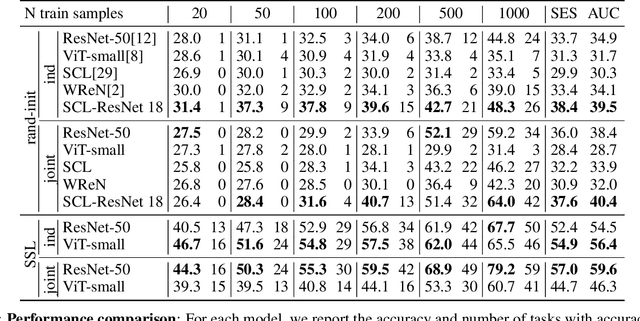
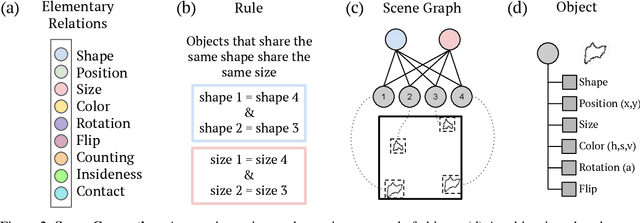
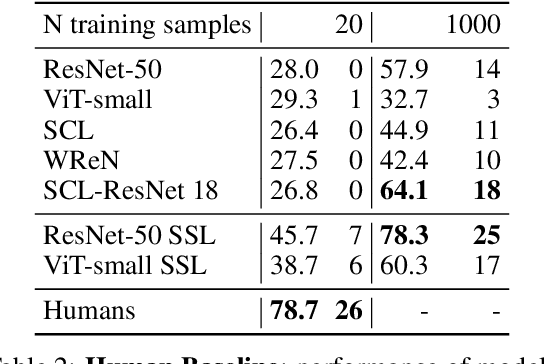
A fundamental component of human vision is our ability to parse complex visual scenes and judge the relations between their constituent objects. AI benchmarks for visual reasoning have driven rapid progress in recent years with state-of-the-art systems now reaching human accuracy on some of these benchmarks. Yet, a major gap remains in terms of the sample efficiency with which humans and AI systems learn new visual reasoning tasks. Humans' remarkable efficiency at learning has been at least partially attributed to their ability to harness compositionality -- such that they can efficiently take advantage of previously gained knowledge when learning new tasks. Here, we introduce a novel visual reasoning benchmark, Compositional Visual Relations (CVR), to drive progress towards the development of more data-efficient learning algorithms. We take inspiration from fluidic intelligence and non-verbal reasoning tests and describe a novel method for creating compositions of abstract rules and associated image datasets at scale. Our proposed benchmark includes measures of sample efficiency, generalization and transfer across task rules, as well as the ability to leverage compositionality. We systematically evaluate modern neural architectures and find that, surprisingly, convolutional architectures surpass transformer-based architectures across all performance measures in most data regimes. However, all computational models are a lot less data efficient compared to humans even after learning informative visual representations using self-supervision. Overall, we hope that our challenge will spur interest in the development of neural architectures that can learn to harness compositionality toward more efficient learning.
Xplique: A Deep Learning Explainability Toolbox
Jun 09, 2022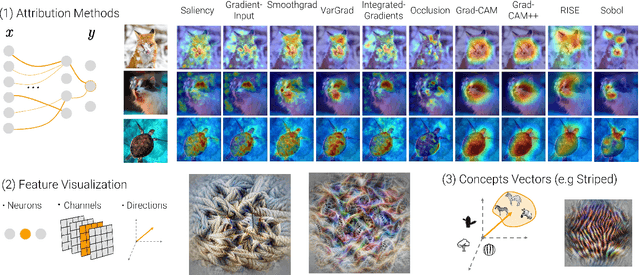
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.
What I Cannot Predict, I Do Not Understand: A Human-Centered Evaluation Framework for Explainability Methods
Dec 06, 2021
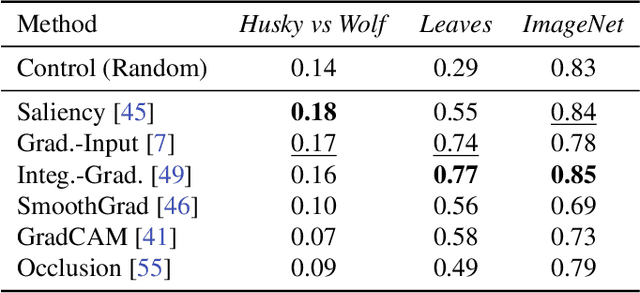
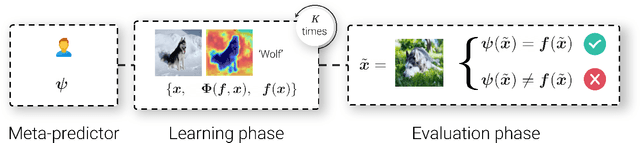
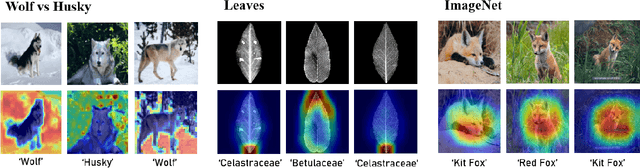
A multitude of explainability methods and theoretical evaluation scores have been proposed. However, it is not yet known: (1) how useful these methods are in real-world scenarios and (2) how well theoretical measures predict the usefulness of these methods for practical use by a human. To fill this gap, we conducted human psychophysics experiments at scale to evaluate the ability of human participants (n=1,150) to leverage representative attribution methods to learn to predict the decision of different image classifiers. Our results demonstrate that theoretical measures used to score explainability methods poorly reflect the practical usefulness of individual attribution methods in real-world scenarios. Furthermore, the degree to which individual attribution methods helped human participants predict classifiers' decisions varied widely across categorization tasks and datasets. Overall, our results highlight fundamental challenges for the field -- suggesting a critical need to develop better explainability methods and to deploy human-centered evaluation approaches. We will make the code of our framework available to ease the systematic evaluation of novel explainability methods.