 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to design a dataset compliant with an ML-based system ODD?
Jun 20, 2024This paper focuses on a Vision-based Landing task and presents the design and the validation of a dataset that would comply with the Operational Design Domain (ODD) of a Machine-Learning (ML) system. Relying on emerging certification standards, we describe the process for establishing ODDs at both the system and image levels. In the process, we present the translation of high-level system constraints into actionable image-level properties, allowing for the definition of verifiable Data Quality Requirements (DQRs). To illustrate this approach, we use the Landing Approach Runway Detection (LARD) dataset which combines synthetic imagery and real footage, and we focus on the steps required to verify the DQRs. The replicable framework presented in this paper addresses the challenges of designing a dataset compliant with the stringent needs of ML-based systems certification in safety-critical applications.
Unlocking Feature Visualization for Deeper Networks with MAgnitude Constrained Optimization
Jun 11, 2023
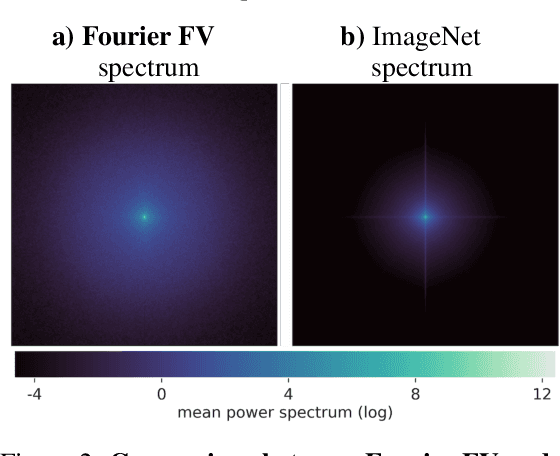
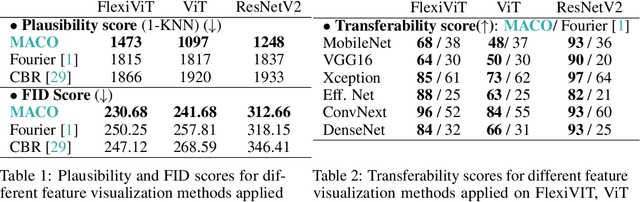
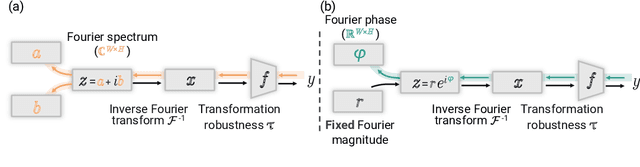
Feature visualization has gained substantial popularity, particularly after the influential work by Olah et al. in 2017, which established it as a crucial tool for explainability. However, its widespread adoption has been limited due to a reliance on tricks to generate interpretable images, and corresponding challenges in scaling it to deeper neural networks. Here, we describe MACO, a simple approach to address these shortcomings. The main idea is to generate images by optimizing the phase spectrum while keeping the magnitude constant to ensure that generated explanations lie in the space of natural images. Our approach yields significantly better results (both qualitatively and quantitatively) and unlocks efficient and interpretable feature visualizations for large state-of-the-art neural networks. We also show that our approach exhibits an attribution mechanism allowing us to augment feature visualizations with spatial importance. We validate our method on a novel benchmark for comparing feature visualization methods, and release its visualizations for all classes of the ImageNet dataset on https://serre-lab.github.io/Lens/. Overall, our approach unlocks, for the first time, feature visualizations for large, state-of-the-art deep neural networks without resorting to any parametric prior image model.
Xplique: A Deep Learning Explainability Toolbox
Jun 09, 2022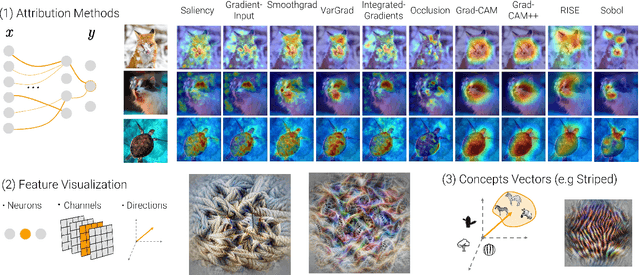
Today's most advanced machine-learning models are hardly scrutable. The key challenge for explainability methods is to help assisting researchers in opening up these black boxes, by revealing the strategy that led to a given decision, by characterizing their internal states or by studying the underlying data representation. To address this challenge, we have developed Xplique: a software library for explainability which includes representative explainability methods as well as associated evaluation metrics. It interfaces with one of the most popular learning libraries: Tensorflow as well as other libraries including PyTorch, scikit-learn and Theano. The code is licensed under the MIT license and is freely available at github.com/deel-ai/xplique.
Dataset Definition Standard (DDS)
Jan 07, 2021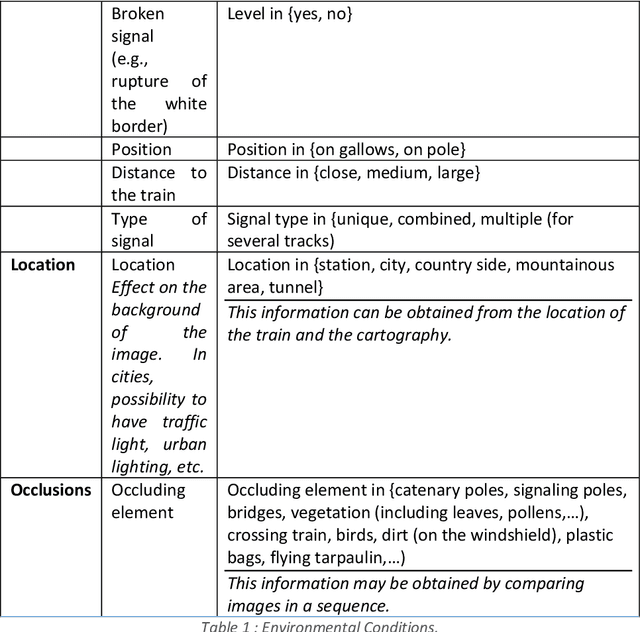

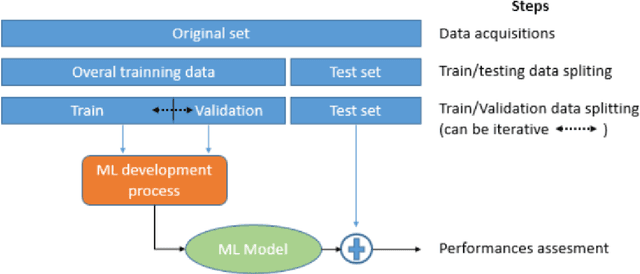
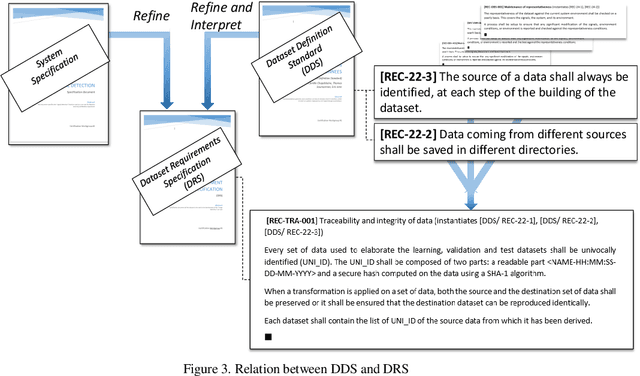
This document gives a set of recommendations to build and manipulate the datasets used to develop and/or validate machine learning models such as deep neural networks. This document is one of the 3 documents defined in [1] to ensure the quality of datasets. This is a work in progress as good practices evolve along with our understanding of machine learning. The document is divided into three main parts. Section 2 addresses the data collection activity. Section 3 gives recommendations about the annotation process. Finally, Section 4 gives recommendations concerning the breakdown between train, validation, and test datasets. In each part, we first define the desired properties at stake, then we explain the objectives targeted to meet the properties, finally we state the recommendations to reach these objectives.
Ensuring Dataset Quality for Machine Learning Certification
Nov 03, 2020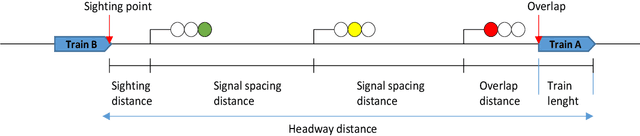

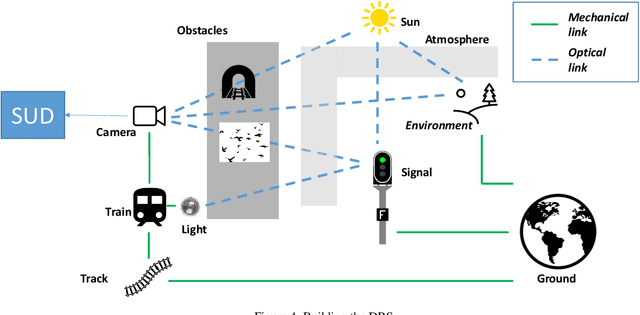
In this paper, we address the problem of dataset quality in the context of Machine Learning (ML)-based critical systems. We briefly analyse the applicability of some existing standards dealing with data and show that the specificities of the ML context are neither properly captured nor taken into ac-count. As a first answer to this concerning situation, we propose a dataset specification and verification process, and apply it on a signal recognition system from the railway domain. In addi-tion, we also give a list of recommendations for the collection and management of datasets. This work is one step towards the dataset engineering process that will be required for ML to be used on safety critical systems.