 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite Paper Machine Learning in Certified Systems
Mar 18, 2021

Machine Learning (ML) seems to be one of the most promising solution to automate partially or completely some of the complex tasks currently realized by humans, such as driving vehicles, recognizing voice, etc. It is also an opportunity to implement and embed new capabilities out of the reach of classical implementation techniques. However, ML techniques introduce new potential risks. Therefore, they have only been applied in systems where their benefits are considered worth the increase of risk. In practice, ML techniques raise multiple challenges that could prevent their use in systems submitted to certification constraints. But what are the actual challenges? Can they be overcome by selecting appropriate ML techniques, or by adopting new engineering or certification practices? These are some of the questions addressed by the ML Certification 3 Workgroup (WG) set-up by the Institut de Recherche Technologique Saint Exup\'ery de Toulouse (IRT), as part of the DEEL Project.
Dataset Definition Standard (DDS)
Jan 07, 2021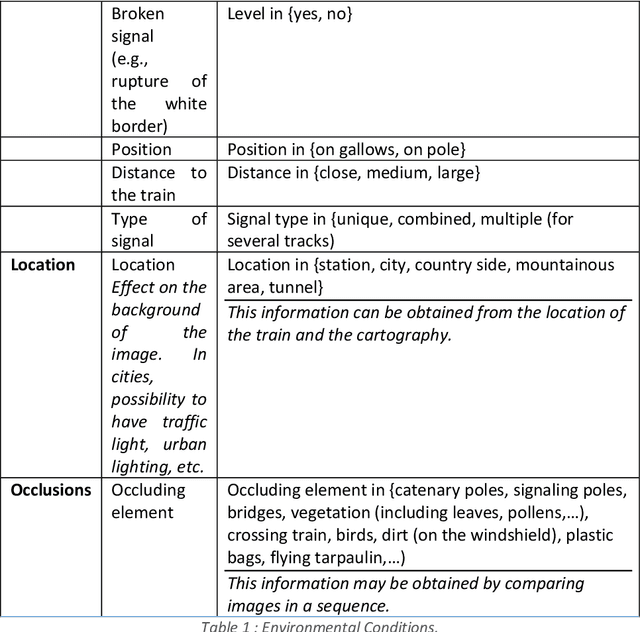

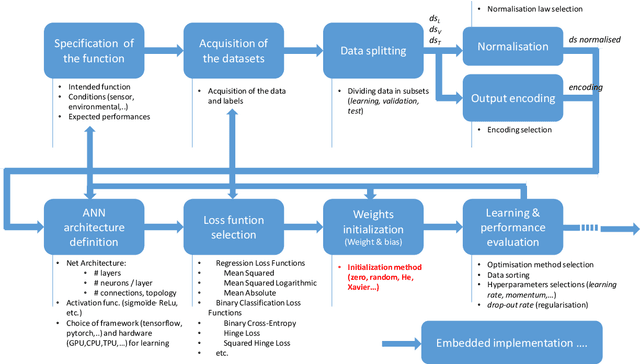
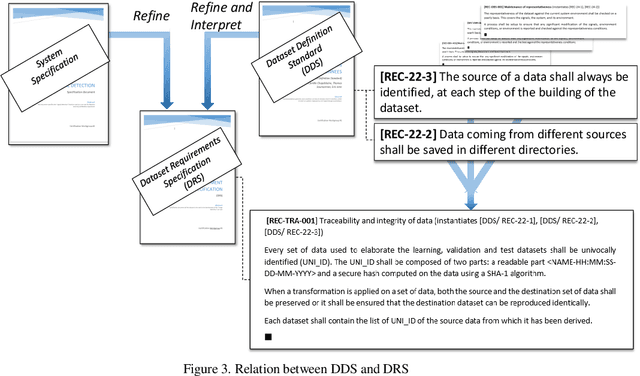
This document gives a set of recommendations to build and manipulate the datasets used to develop and/or validate machine learning models such as deep neural networks. This document is one of the 3 documents defined in [1] to ensure the quality of datasets. This is a work in progress as good practices evolve along with our understanding of machine learning. The document is divided into three main parts. Section 2 addresses the data collection activity. Section 3 gives recommendations about the annotation process. Finally, Section 4 gives recommendations concerning the breakdown between train, validation, and test datasets. In each part, we first define the desired properties at stake, then we explain the objectives targeted to meet the properties, finally we state the recommendations to reach these objectives.
Local Propagation for Few-Shot Learning
Jan 05, 2021



The challenge in few-shot learning is that available data is not enough to capture the underlying distribution. To mitigate this, two emerging directions are (a) using local image representations, essentially multiplying the amount of data by a constant factor, and (b) using more unlabeled data, for instance by transductive inference, jointly on a number of queries. In this work, we bring these two ideas together, introducing \emph{local propagation}. We treat local image features as independent examples, we build a graph on them and we use it to propagate both the features themselves and the labels, known and unknown. Interestingly, since there is a number of features per image, even a single query gives rise to transductive inference. As a result, we provide a universally safe choice for few-shot inference under both non-transductive and transductive settings, improving accuracy over corresponding methods. This is in contrast to existing solutions, where one needs to choose the method depending on the quantity of available data.
Ensuring Dataset Quality for Machine Learning Certification
Nov 03, 2020

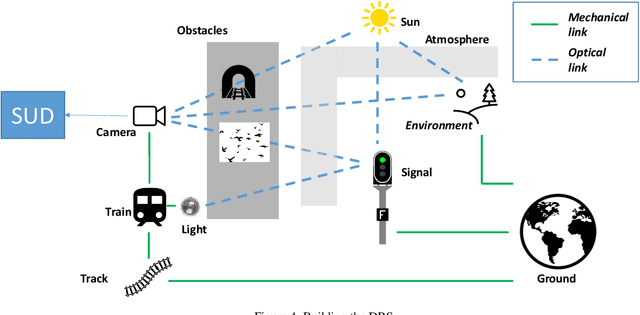
In this paper, we address the problem of dataset quality in the context of Machine Learning (ML)-based critical systems. We briefly analyse the applicability of some existing standards dealing with data and show that the specificities of the ML context are neither properly captured nor taken into ac-count. As a first answer to this concerning situation, we propose a dataset specification and verification process, and apply it on a signal recognition system from the railway domain. In addi-tion, we also give a list of recommendations for the collection and management of datasets. This work is one step towards the dataset engineering process that will be required for ML to be used on safety critical systems.
Few-Shot Few-Shot Learning and the role of Spatial Attention
Feb 18, 2020



Few-shot learning is often motivated by the ability of humans to learn new tasks from few examples. However, standard few-shot classification benchmarks assume that the representation is learned on a limited amount of base class data, ignoring the amount of prior knowledge that a human may have accumulated before learning new tasks. At the same time, even if a powerful representation is available, it may happen in some domain that base class data are limited or non-existent. This motivates us to study a problem where the representation is obtained from a classifier pre-trained on a large-scale dataset of a different domain, assuming no access to its training process, while the base class data are limited to few examples per class and their role is to adapt the representation to the domain at hand rather than learn from scratch. We adapt the representation in two stages, namely on the few base class data if available and on the even fewer data of new tasks. In doing so, we obtain from the pre-trained classifier a spatial attention map that allows focusing on objects and suppressing background clutter. This is important in the new problem, because when base class data are few, the network cannot learn where to focus implicitly. We also show that a pre-trained network may be easily adapted to novel classes, without meta-learning.
n-MeRCI: A new Metric to Evaluate the Correlation Between Predictive Uncertainty and True Error
Aug 20, 2019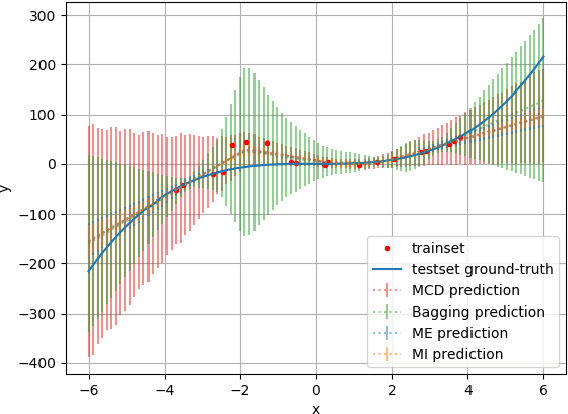


As deep learning applications are becoming more and more pervasive in robotics, the question of evaluating the reliability of inferences becomes a central question in the robotics community. This domain, known as predictive uncertainty, has come under the scrutiny of research groups developing Bayesian approaches adapted to deep learning such as Monte Carlo Dropout. Unfortunately, for the time being, the real goal of predictive uncertainty has been swept under the rug. Indeed, these approaches are solely evaluated in terms of raw performance of the network prediction, while the quality of their estimated uncertainty is not assessed. Evaluating such uncertainty prediction quality is especially important in robotics, as actions shall depend on the confidence in perceived information. In this context, the main contribution of this article is to propose a novel metric that is adapted to the evaluation of relative uncertainty assessment and directly applicable to regression with deep neural networks. To experimentally validate this metric, we evaluate it on a toy dataset and then apply it to the task of monocular depth estimation.
Dense Classification and Implanting for Few-Shot Learning
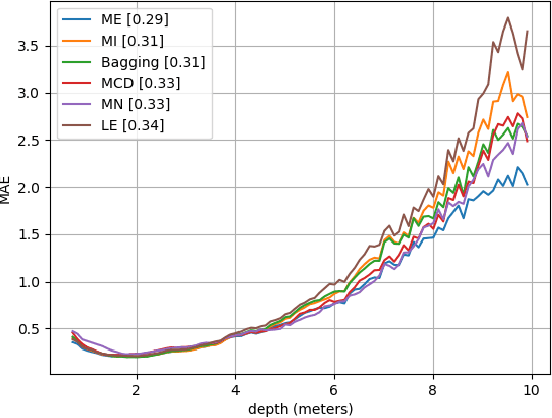
Mar 12, 2019



Training deep neural networks from few examples is a highly challenging and key problem for many computer vision tasks. In this context, we are targeting knowledge transfer from a set with abundant data to other sets with few available examples. We propose two simple and effective solutions: (i) dense classification over feature maps, which for the first time studies local activations in the domain of few-shot learning, and (ii) implanting, that is, attaching new neurons to a previously trained network to learn new, task-specific features. On miniImageNet, we improve the prior state-of-the-art on few-shot classification, i.e., we achieve 62.5%, 79.8% and 83.8% on 5-way 1-shot, 5-shot and 10-shot settings respectively.
Deep multi-scale architectures for monocular depth estimation
Jun 08, 2018
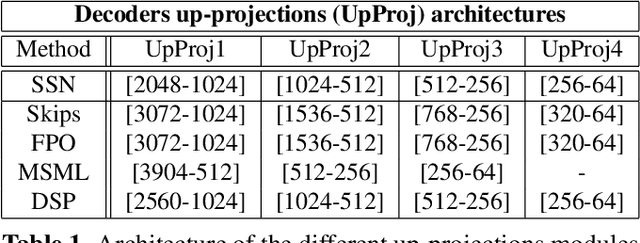
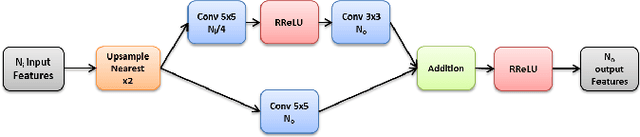

This paper aims at understanding the role of multi-scale information in the estimation of depth from monocular images. More precisely, the paper investigates four different deep CNN architectures, designed to explicitly make use of multi-scale features along the network, and compare them to a state-of-the-art single-scale approach. The paper also shows that involving multi-scale features in depth estimation not only improves the performance in terms of accuracy, but also gives qualitatively better depth maps. Experiments are done on the widely used NYU Depth dataset, on which the proposed method achieves state-of-the-art performance.