 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifying and extending Precision Recall metrics for assessing generative models
May 02, 2024With the recent success of generative models in image and text, the evaluation of generative models has gained a lot of attention. Whereas most generative models are compared in terms of scalar values such as Frechet Inception Distance (FID) or Inception Score (IS), in the last years (Sajjadi et al., 2018) proposed a definition of precision-recall curve to characterize the closeness of two distributions. Since then, various approaches to precision and recall have seen the light (Kynkaanniemi et al., 2019; Naeem et al., 2020; Park & Kim, 2023). They center their attention on the extreme values of precision and recall, but apart from this fact, their ties are elusive. In this paper, we unify most of these approaches under the same umbrella, relying on the work of (Simon et al., 2019). Doing so, we were able not only to recover entire curves, but also to expose the sources of the accounted pitfalls of the concerned metrics. We also provide consistency results that go well beyond the ones presented in the corresponding literature. Last, we study the different behaviors of the curves obtained experimentally.
On the De-duplication of LAION-2B
Mar 17, 2023Generative models, such as DALL-E, Midjourney, and Stable Diffusion, have societal implications that extend beyond the field of computer science. These models require large image databases like LAION-2B, which contain two billion images. At this scale, manual inspection is difficult and automated analysis is challenging. In addition, recent studies show that duplicated images pose copyright problems for models trained on LAION2B, which hinders its usability. This paper proposes an algorithmic chain that runs with modest compute, that compresses CLIP features to enable efficient duplicate detection, even for vast image volumes. Our approach demonstrates that roughly 700 million images, or about 30\%, of LAION-2B's images are likely duplicated. Our method also provides the histograms of duplication on this dataset, which we use to reveal more examples of verbatim copies by Stable Diffusion and further justify the approach. The current version of the de-duplicated set will be distributed online.
Training face verification models from generated face identity data
Aug 02, 2021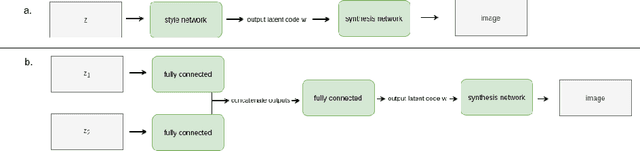
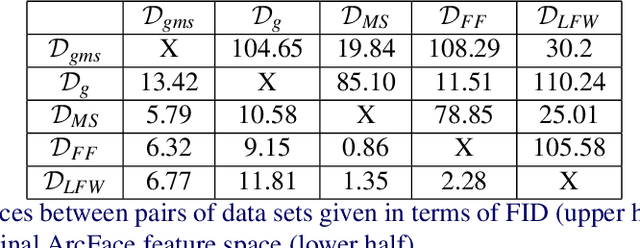

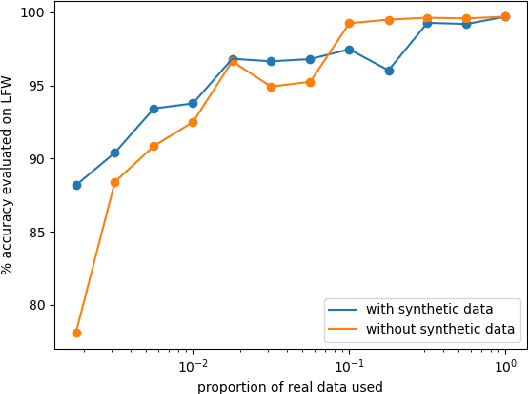
Machine learning tools are becoming increasingly powerful and widely used. Unfortunately membership attacks, which seek to uncover information from data sets used in machine learning, have the potential to limit data sharing. In this paper we consider an approach to increase the privacy protection of data sets, as applied to face recognition. Using an auxiliary face recognition model, we build on the StyleGAN generative adversarial network and feed it with latent codes combining two distinct sub-codes, one encoding visual identity factors, and, the other, non-identity factors. By independently varying these vectors during image generation, we create a synthetic data set of fictitious face identities. We use this data set to train a face recognition model. The model performance degrades in comparison to the state-of-the-art of face verification. When tested with a simple membership attack our model provides good privacy protection, however the model performance degrades in comparison to the state-of-the-art of face verification. We find that the addition of a small amount of private data greatly improves the performance of our model, which highlights the limitations of using synthetic data to train machine learning models.
This Person (Probably) Exists. Identity Membership Attacks Against GAN Generated Faces
Jul 13, 2021


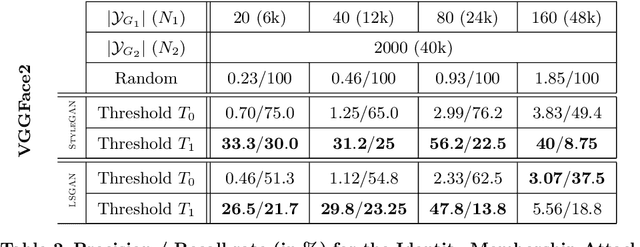
Recently, generative adversarial networks (GANs) have achieved stunning realism, fooling even human observers. Indeed, the popular tongue-in-cheek website {\small \url{ http://thispersondoesnotexist.com}}, taunts users with GAN generated images that seem too real to believe. On the other hand, GANs do leak information about their training data, as evidenced by membership attacks recently demonstrated in the literature. In this work, we challenge the assumption that GAN faces really are novel creations, by constructing a successful membership attack of a new kind. Unlike previous works, our attack can accurately discern samples sharing the same identity as training samples without being the same samples. We demonstrate the interest of our attack across several popular face datasets and GAN training procedures. Notably, we show that even in the presence of significant dataset diversity, an over represented person can pose a privacy concern.
Equivalence of several curves assessing the similarity between probability distributions
Jun 21, 2020



The recent advent of powerful generative models has triggered the renewed development of quantitative measures to assess the proximity of two probability distributions. As the scalar Frechet inception distance remains popular, several methods have explored computing entire curves, which reveal the trade-off between the fidelity and variability of the first distribution with respect to the second one. Several of such variants have been proposed independently and while intuitively similar, their relationship has not yet been made explicit. In an effort to make the emerging picture of generative evaluation more clear, we propose a unification of four curves known respectively as: the precision-recall (PR) curve, the Lorenz curve, the receiver operating characteristic (ROC) curve and a special case of R\'enyi divergence frontiers.
Detecting Overfitting of Deep Generative Networks via Latent Recovery
Jan 09, 2019
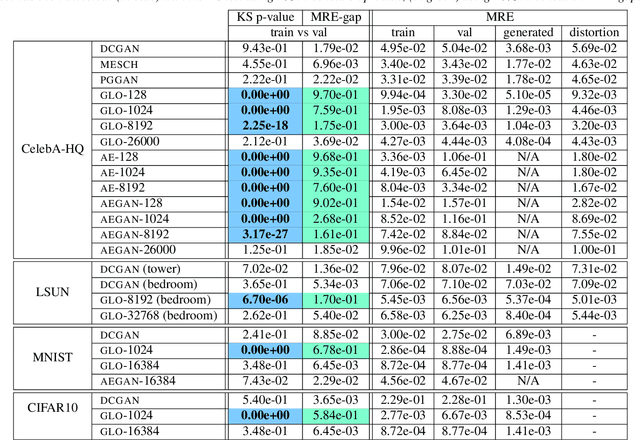
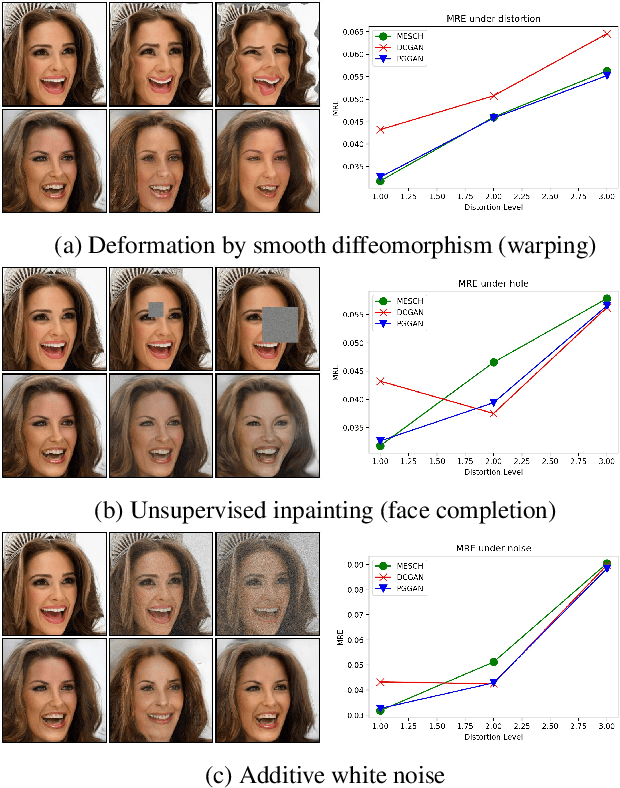
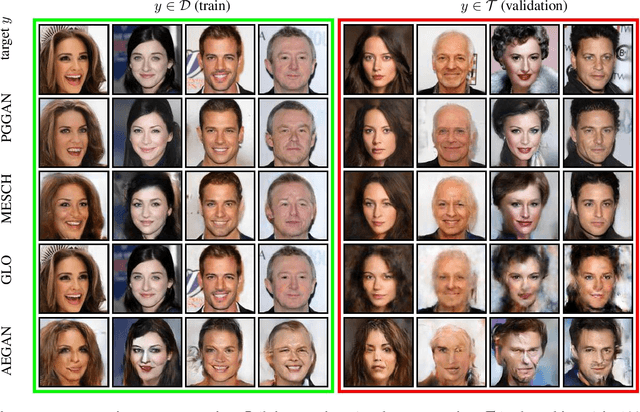
State of the art deep generative networks are capable of producing images with such incredible realism that they can be suspected of memorizing training images. It is why it is not uncommon to include visualizations of training set nearest neighbors, to suggest generated images are not simply memorized. We demonstrate this is not sufficient and motivates the need to study memorization/overfitting of deep generators with more scrutiny. This paper addresses this question by i) showing how simple losses are highly effective at reconstructing images for deep generators ii) analyzing the statistics of reconstruction errors when reconstructing training and validation images, which is the standard way to analyze overfitting in machine learning. Using this methodology, this paper shows that overfitting is not detectable in the pure GAN models proposed in the literature, in contrast with those using hybrid adversarial losses, which are amongst the most widely applied generative methods. The paper also shows that standard GAN evaluation metrics fail to capture memorization for some deep generators. Finally, the paper also shows how off-the-shelf GAN generators can be successfully applied to face inpainting and face super-resolution using the proposed reconstruction method, without hybrid adversarial losses.
Deep multi-scale architectures for monocular depth estimation
Jun 08, 2018
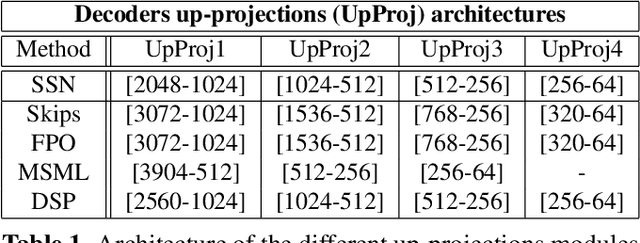
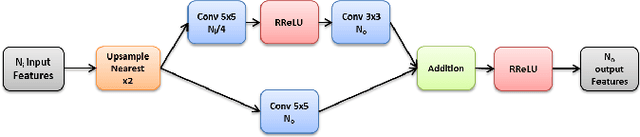

This paper aims at understanding the role of multi-scale information in the estimation of depth from monocular images. More precisely, the paper investigates four different deep CNN architectures, designed to explicitly make use of multi-scale features along the network, and compare them to a state-of-the-art single-scale approach. The paper also shows that involving multi-scale features in depth estimation not only improves the performance in terms of accuracy, but also gives qualitatively better depth maps. Experiments are done on the widely used NYU Depth dataset, on which the proposed method achieves state-of-the-art performance.