 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining face verification models from generated face identity data
Paper and Code
Aug 02, 2021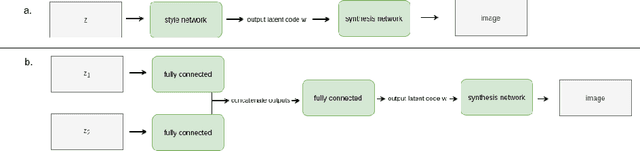
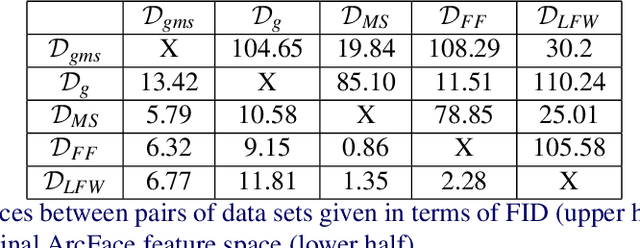

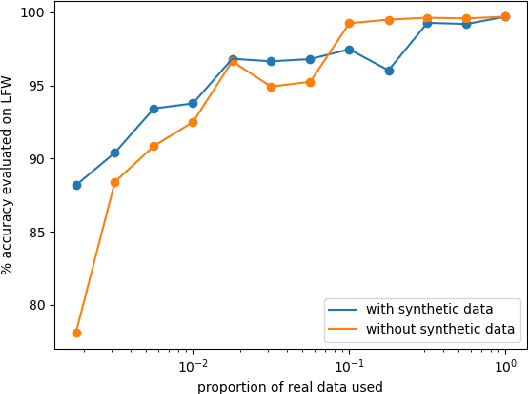
Machine learning tools are becoming increasingly powerful and widely used. Unfortunately membership attacks, which seek to uncover information from data sets used in machine learning, have the potential to limit data sharing. In this paper we consider an approach to increase the privacy protection of data sets, as applied to face recognition. Using an auxiliary face recognition model, we build on the StyleGAN generative adversarial network and feed it with latent codes combining two distinct sub-codes, one encoding visual identity factors, and, the other, non-identity factors. By independently varying these vectors during image generation, we create a synthetic data set of fictitious face identities. We use this data set to train a face recognition model. The model performance degrades in comparison to the state-of-the-art of face verification. When tested with a simple membership attack our model provides good privacy protection, however the model performance degrades in comparison to the state-of-the-art of face verification. We find that the addition of a small amount of private data greatly improves the performance of our model, which highlights the limitations of using synthetic data to train machine learning models.