 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Uncertainty Quantification in Generative Model Learning
Nov 13, 2025While generative models have become increasingly prevalent across various domains, fundamental concerns regarding their reliability persist. A crucial yet understudied aspect of these models is the uncertainty quantification surrounding their distribution approximation capabilities. Current evaluation methodologies focus predominantly on measuring the closeness between the learned and the target distributions, neglecting the inherent uncertainty in these measurements. In this position paper, we formalize the problem of uncertainty quantification in generative model learning. We discuss potential research directions, including the use of ensemble-based precision-recall curves. Our preliminary experiments on synthetic datasets demonstrate the effectiveness of aggregated precision-recall curves in capturing model approximation uncertainty, enabling systematic comparison among different model architectures based on their uncertainty characteristics.
On the De-duplication of LAION-2B
Mar 17, 2023Generative models, such as DALL-E, Midjourney, and Stable Diffusion, have societal implications that extend beyond the field of computer science. These models require large image databases like LAION-2B, which contain two billion images. At this scale, manual inspection is difficult and automated analysis is challenging. In addition, recent studies show that duplicated images pose copyright problems for models trained on LAION2B, which hinders its usability. This paper proposes an algorithmic chain that runs with modest compute, that compresses CLIP features to enable efficient duplicate detection, even for vast image volumes. Our approach demonstrates that roughly 700 million images, or about 30\%, of LAION-2B's images are likely duplicated. Our method also provides the histograms of duplication on this dataset, which we use to reveal more examples of verbatim copies by Stable Diffusion and further justify the approach. The current version of the de-duplicated set will be distributed online.
Empowering the trustworthiness of ML-based critical systems through engineering activities
Sep 30, 2022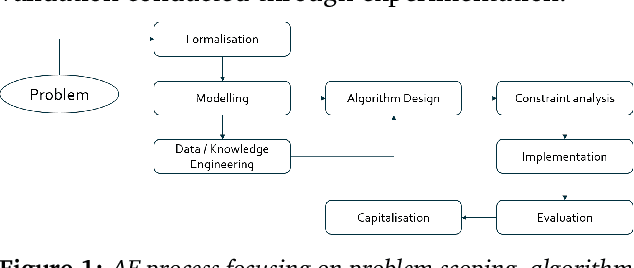
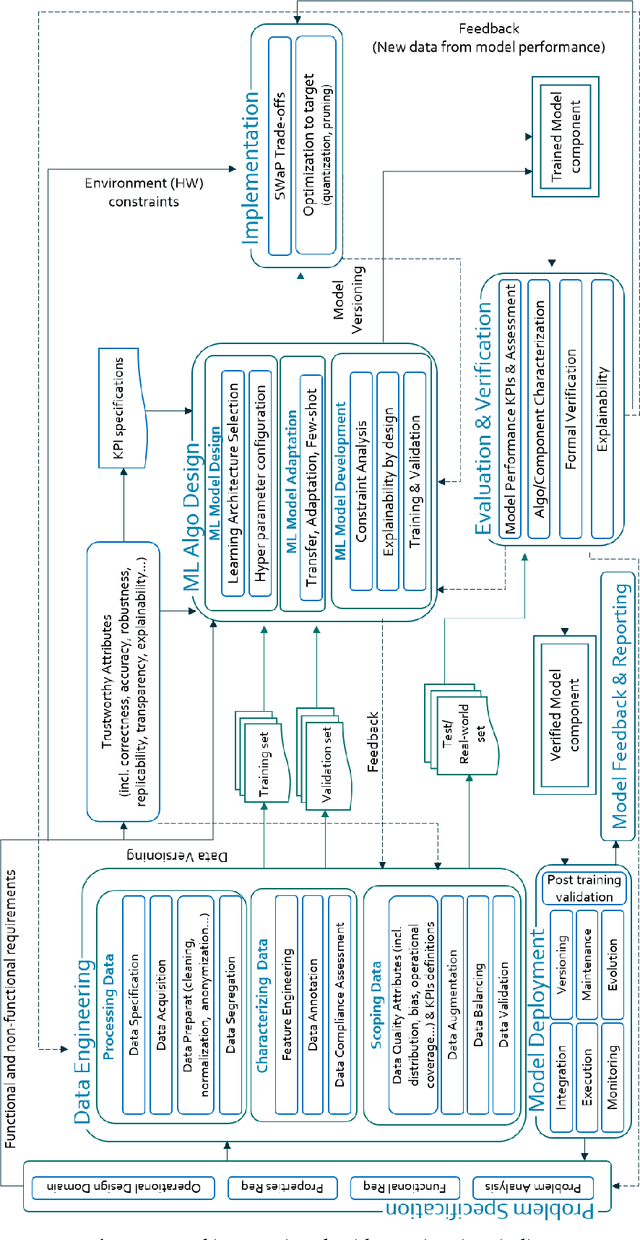
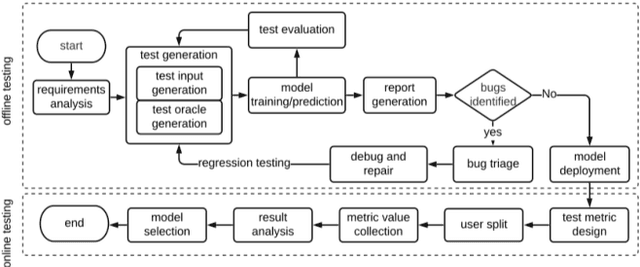
This paper reviews the entire engineering process of trustworthy Machine Learning (ML) algorithms designed to equip critical systems with advanced analytics and decision functions. We start from the fundamental principles of ML and describe the core elements conditioning its trust, particularly through its design: namely domain specification, data engineering, design of the ML algorithms, their implementation, evaluation and deployment. The latter components are organized in an unique framework for the design of trusted ML systems.
Training face verification models from generated face identity data
Aug 02, 2021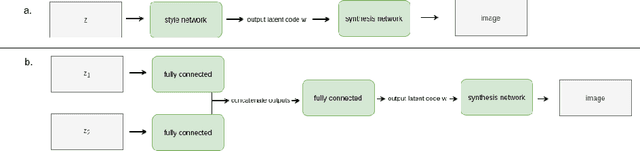
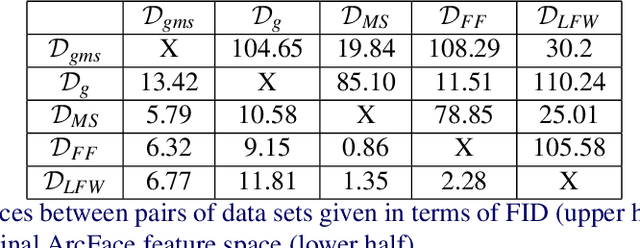

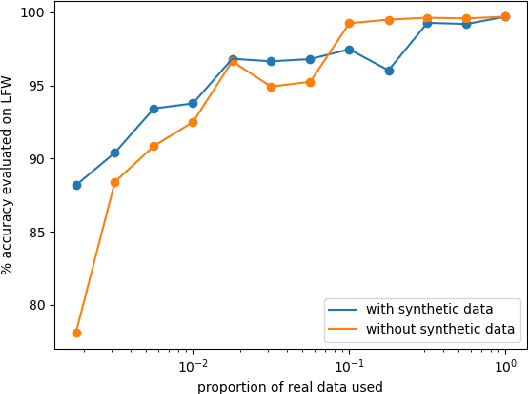
Machine learning tools are becoming increasingly powerful and widely used. Unfortunately membership attacks, which seek to uncover information from data sets used in machine learning, have the potential to limit data sharing. In this paper we consider an approach to increase the privacy protection of data sets, as applied to face recognition. Using an auxiliary face recognition model, we build on the StyleGAN generative adversarial network and feed it with latent codes combining two distinct sub-codes, one encoding visual identity factors, and, the other, non-identity factors. By independently varying these vectors during image generation, we create a synthetic data set of fictitious face identities. We use this data set to train a face recognition model. The model performance degrades in comparison to the state-of-the-art of face verification. When tested with a simple membership attack our model provides good privacy protection, however the model performance degrades in comparison to the state-of-the-art of face verification. We find that the addition of a small amount of private data greatly improves the performance of our model, which highlights the limitations of using synthetic data to train machine learning models.
This Person (Probably) Exists. Identity Membership Attacks Against GAN Generated Faces
Jul 13, 2021


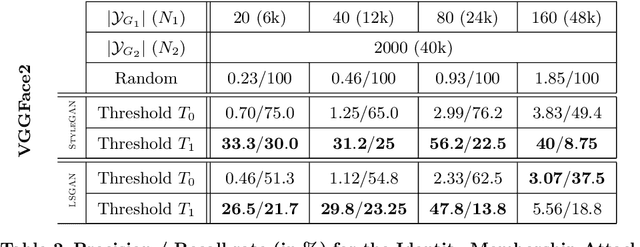
Recently, generative adversarial networks (GANs) have achieved stunning realism, fooling even human observers. Indeed, the popular tongue-in-cheek website {\small \url{ http://thispersondoesnotexist.com}}, taunts users with GAN generated images that seem too real to believe. On the other hand, GANs do leak information about their training data, as evidenced by membership attacks recently demonstrated in the literature. In this work, we challenge the assumption that GAN faces really are novel creations, by constructing a successful membership attack of a new kind. Unlike previous works, our attack can accurately discern samples sharing the same identity as training samples without being the same samples. We demonstrate the interest of our attack across several popular face datasets and GAN training procedures. Notably, we show that even in the presence of significant dataset diversity, an over represented person can pose a privacy concern.
Learning 2D to 3D Lifting for Object Detection in 3D for Autonomous Vehicles
Mar 27, 2019
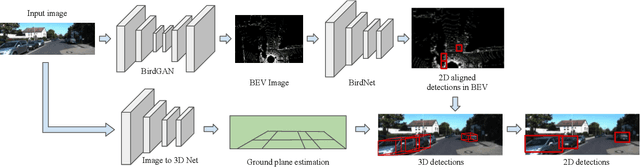
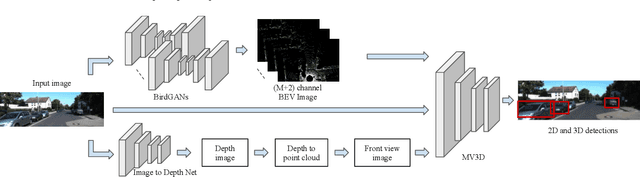

We address the problem of 3D object detection from 2D monocular images in autonomous driving scenarios. We propose to lift the 2D images to 3D representations using learned neural networks and leverage existing networks working directly on 3D to perform 3D object detection and localization. We show that, with carefully designed training mechanism and automatically selected minimally noisy data, such a method is not only feasible, but gives higher results than many methods working on actual 3D inputs acquired from physical sensors. On the challenging KITTI benchmark, we show that our 2D to 3D lifted method outperforms many recent competitive 3D networks while significantly outperforming previous state of the art for 3D detection from monocular images. We also show that a late fusion of the output of the network trained on generated 3D images, with that trained on real 3D images, improves performance. We find the results very interesting and argue that such a method could serve as a highly reliable backup in case of malfunction of expensive 3D sensors, if not potentially making them redundant, at least in the case of low human injury risk autonomous navigation scenarios like warehouse automation.
Detecting Overfitting of Deep Generative Networks via Latent Recovery
Jan 09, 2019
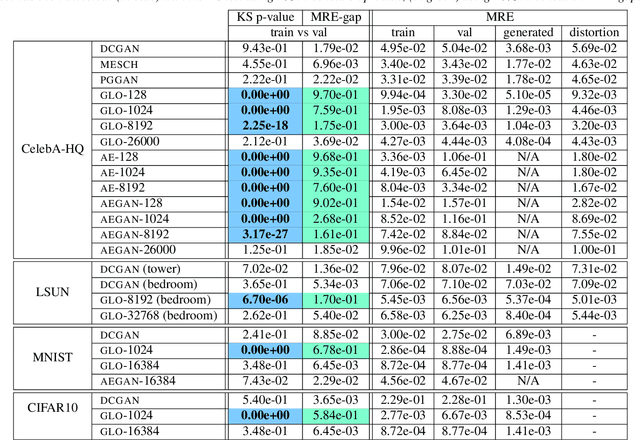
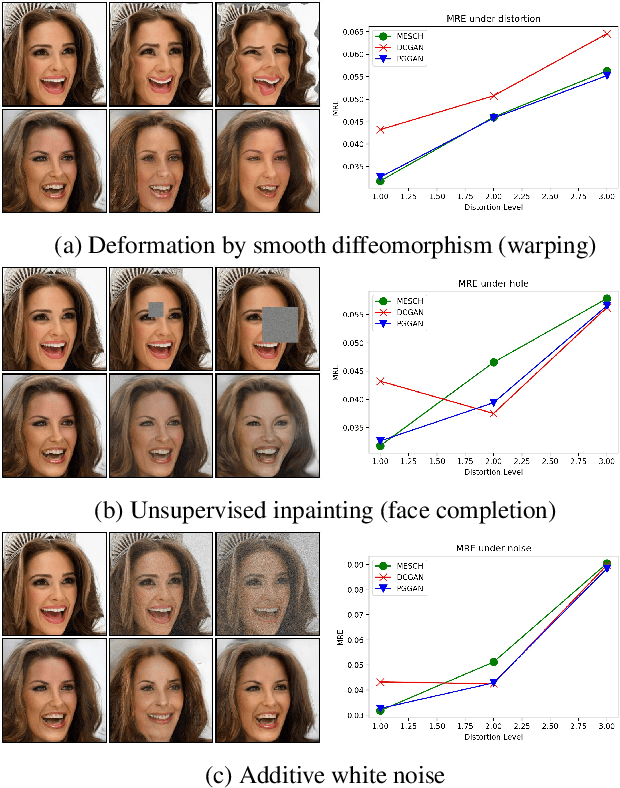
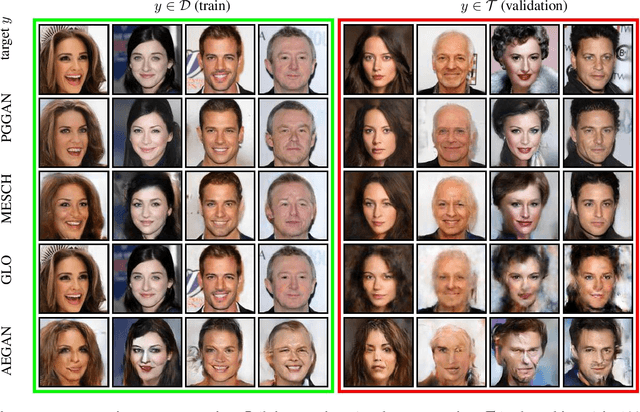
State of the art deep generative networks are capable of producing images with such incredible realism that they can be suspected of memorizing training images. It is why it is not uncommon to include visualizations of training set nearest neighbors, to suggest generated images are not simply memorized. We demonstrate this is not sufficient and motivates the need to study memorization/overfitting of deep generators with more scrutiny. This paper addresses this question by i) showing how simple losses are highly effective at reconstructing images for deep generators ii) analyzing the statistics of reconstruction errors when reconstructing training and validation images, which is the standard way to analyze overfitting in machine learning. Using this methodology, this paper shows that overfitting is not detectable in the pure GAN models proposed in the literature, in contrast with those using hybrid adversarial losses, which are amongst the most widely applied generative methods. The paper also shows that standard GAN evaluation metrics fail to capture memorization for some deep generators. Finally, the paper also shows how off-the-shelf GAN generators can be successfully applied to face inpainting and face super-resolution using the proposed reconstruction method, without hybrid adversarial losses.
Unsupervised part learning for visual recognition
Apr 12, 2017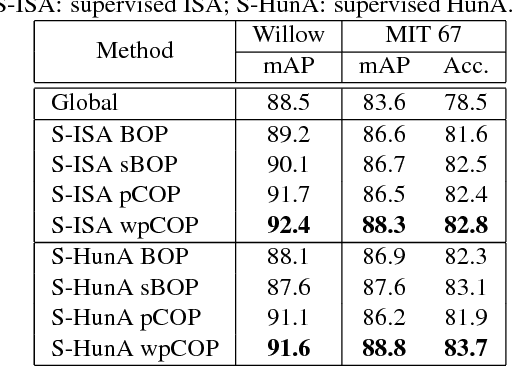

Part-based image classification aims at representing categories by small sets of learned discriminative parts, upon which an image representation is built. Considered as a promising avenue a decade ago, this direction has been neglected since the advent of deep neural networks. In this context, this paper brings two contributions: first, it shows that despite the recent success of end-to-end holistic models, explicit part learning can boosts classification performance. Second, this work proceeds one step further than recent part-based models (PBM), focusing on how to learn parts without using any labeled data. Instead of learning a set of parts per class, as generally done in the PBM literature, the proposed approach both constructs a partition of a given set of images into visually similar groups, and subsequently learn a set of discriminative parts per group in a fully unsupervised fashion. This strategy opens the door to the use of PBM in new applications for which the notion of image categories is irrelevant, such as instance-based image retrieval, for example. We experimentally show that our learned parts can help building efficient image representations, for classification as well as for indexing tasks, resulting in performance superior to holistic state-of-the art Deep Convolutional Neural Networks (DCNN) encoding.
Automatic discovery of discriminative parts as a quadratic assignment problem
Nov 14, 2016

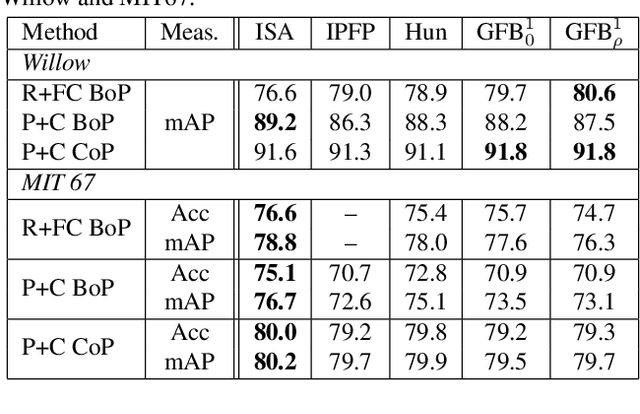

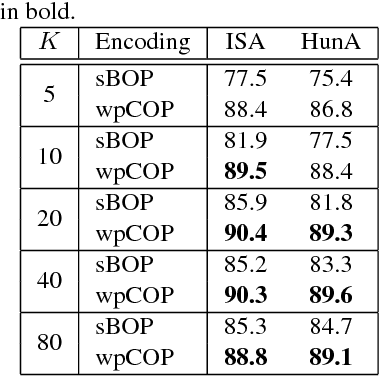
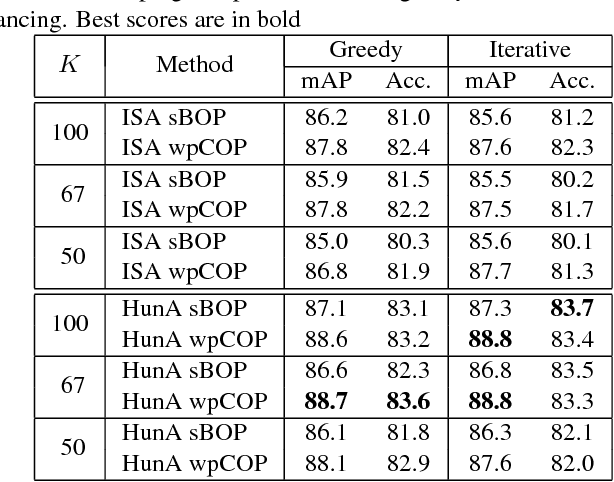
Part-based image classification consists in representing categories by small sets of discriminative parts upon which a representation of the images is built. This paper addresses the question of how to automatically learn such parts from a set of labeled training images. The training of parts is cast as a quadratic assignment problem in which optimal correspondences between image regions and parts are automatically learned. The paper analyses different assignment strategies and thoroughly evaluates them on two public datasets: Willow actions and MIT 67 scenes. State-of-the art results are obtained on these datasets.
Deep fusion of visual signatures for client-server facial analysis
Nov 09, 2016



Facial analysis is a key technology for enabling human-machine interaction. In this context, we present a client-server framework, where a client transmits the signature of a face to be analyzed to the server, and, in return, the server sends back various information describing the face e.g. is the person male or female, is she/he bald, does he have a mustache, etc. We assume that a client can compute one (or a combination) of visual features; from very simple and efficient features, like Local Binary Patterns, to more complex and computationally heavy, like Fisher Vectors and CNN based, depending on the computing resources available. The challenge addressed in this paper is to design a common universal representation such that a single merged signature is transmitted to the server, whatever be the type and number of features computed by the client, ensuring nonetheless an optimal performance. Our solution is based on learning of a common optimal subspace for aligning the different face features and merging them into a universal signature. We have validated the proposed method on the challenging CelebA dataset, on which our method outperforms existing state-of-the-art methods when rich representation is available at test time, while giving competitive performance when only simple signatures (like LBP) are available at test time due to resource constraints on the client.