 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Unlearning from Proxies Induces Closeness Guarantees on Approximate Unlearning
May 11, 2026This paper proposes a paradigm shift linking machine unlearning directly to the structure of the data distributions rather than a mere update of the neural network parameters. We show that inferring these distributions with precision enables distilling the exact unlearning signal induced by the modeling. Theoretical bounds on the Kullback-Leibler divergence from the ideal retrained model to our unlearned model, under verifiable admissibility criterion, reveal the soundness of our framework. This method is experimentally validated over three forgetting scenarios as reaching the closest classifier to the ideal retrained model when compared to competitors.
Guidance Watermarking for Diffusion Models
Sep 26, 2025



This paper introduces a novel watermarking method for diffusion models. It is based on guiding the diffusion process using the gradient computed from any off-the-shelf watermark decoder. The gradient computation encompasses different image augmentations, increasing robustness to attacks against which the decoder was not originally robust, without retraining or fine-tuning. Our method effectively convert any \textit{post-hoc} watermarking scheme into an in-generation embedding along the diffusion process. We show that this approach is complementary to watermarking techniques modifying the variational autoencoder at the end of the diffusion process. We validate the methods on different diffusion models and detectors. The watermarking guidance does not significantly alter the generated image for a given seed and prompt, preserving both the diversity and quality of generation.
Backdoor Attacks on Deep Learning Face Detection
Aug 01, 2025



Face Recognition Systems that operate in unconstrained environments capture images under varying conditions,such as inconsistent lighting, or diverse face poses. These challenges require including a Face Detection module that regresses bounding boxes and landmark coordinates for proper Face Alignment. This paper shows the effectiveness of Object Generation Attacks on Face Detection, dubbed Face Generation Attacks, and demonstrates for the first time a Landmark Shift Attack that backdoors the coordinate regression task performed by face detectors. We then offer mitigations against these vulnerabilities.
Survivability of Backdoor Attacks on Unconstrained Face Recognition Systems
Jul 02, 2025The widespread use of deep learning face recognition raises several security concerns. Although prior works point at existing vulnerabilities, DNN backdoor attacks against real-life, unconstrained systems dealing with images captured in the wild remain a blind spot of the literature. This paper conducts the first system-level study of backdoors in deep learning-based face recognition systems. This paper yields four contributions by exploring the feasibility of DNN backdoors on these pipelines in a holistic fashion. We demonstrate for the first time two backdoor attacks on the face detection task: face generation and face landmark shift attacks. We then show that face feature extractors trained with large margin losses also fall victim to backdoor attacks. Combining our models, we then show using 20 possible pipeline configurations and 15 attack cases that a single backdoor enables an attacker to bypass the entire function of a system. Finally, we provide stakeholders with several best practices and countermeasures.
Task-Agnostic Attacks Against Vision Foundation Models
Mar 05, 2025
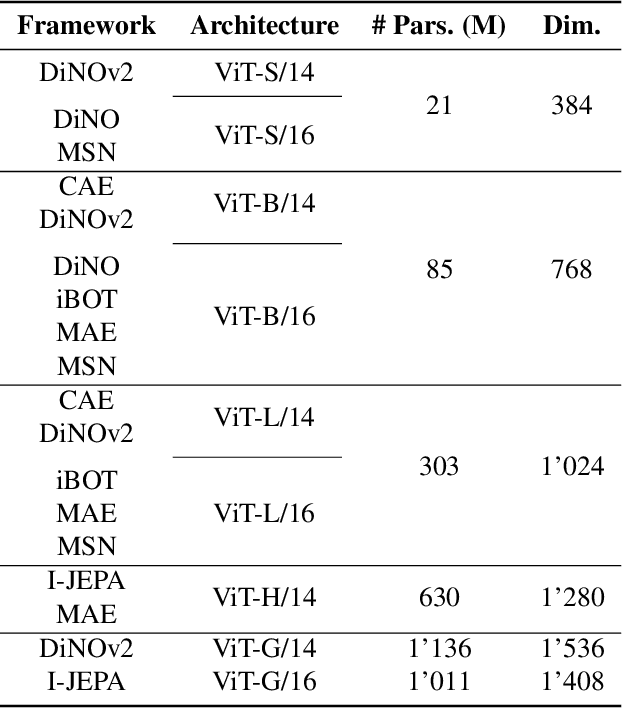
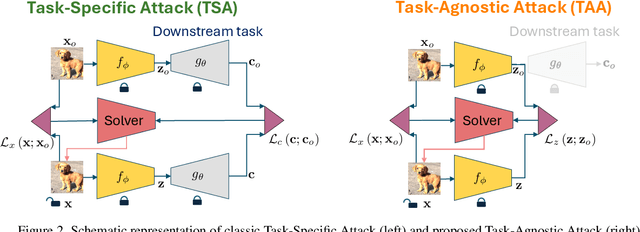
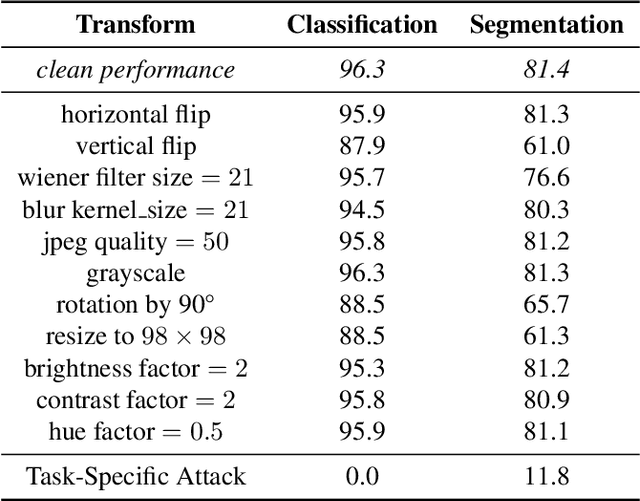
The study of security in machine learning mainly focuses on downstream task-specific attacks, where the adversarial example is obtained by optimizing a loss function specific to the downstream task. At the same time, it has become standard practice for machine learning practitioners to adopt publicly available pre-trained vision foundation models, effectively sharing a common backbone architecture across a multitude of applications such as classification, segmentation, depth estimation, retrieval, question-answering and more. The study of attacks on such foundation models and their impact to multiple downstream tasks remains vastly unexplored. This work proposes a general framework that forges task-agnostic adversarial examples by maximally disrupting the feature representation obtained with foundation models. We extensively evaluate the security of the feature representations obtained by popular vision foundation models by measuring the impact of this attack on multiple downstream tasks and its transferability between models.
Watermark Anything with Localized Messages
Nov 11, 2024



Image watermarking methods are not tailored to handle small watermarked areas. This restricts applications in real-world scenarios where parts of the image may come from different sources or have been edited. We introduce a deep-learning model for localized image watermarking, dubbed the Watermark Anything Model (WAM). The WAM embedder imperceptibly modifies the input image, while the extractor segments the received image into watermarked and non-watermarked areas and recovers one or several hidden messages from the areas found to be watermarked. The models are jointly trained at low resolution and without perceptual constraints, then post-trained for imperceptibility and multiple watermarks. Experiments show that WAM is competitive with state-of-the art methods in terms of imperceptibility and robustness, especially against inpainting and splicing, even on high-resolution images. Moreover, it offers new capabilities: WAM can locate watermarked areas in spliced images and extract distinct 32-bit messages with less than 1 bit error from multiple small regions - no larger than 10% of the image surface - even for small $256\times 256$ images.
Evaluation of Security of ML-based Watermarking: Copy and Removal Attacks
Sep 26, 2024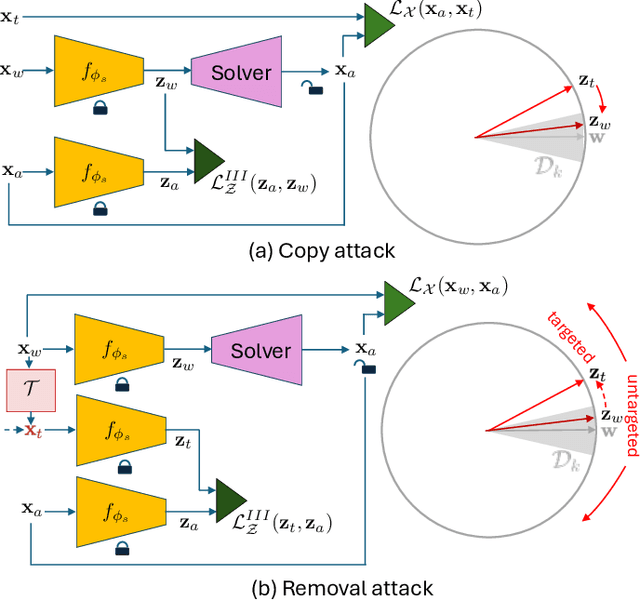
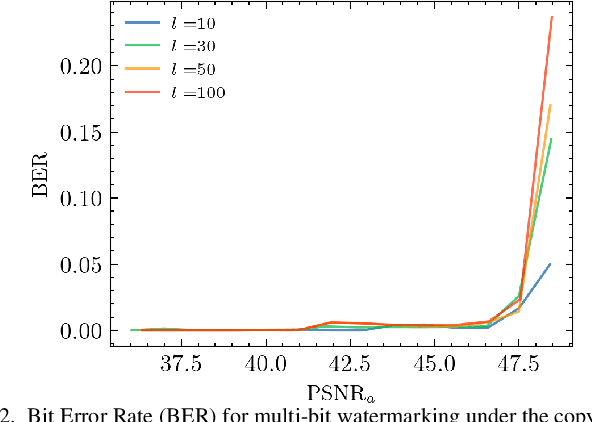
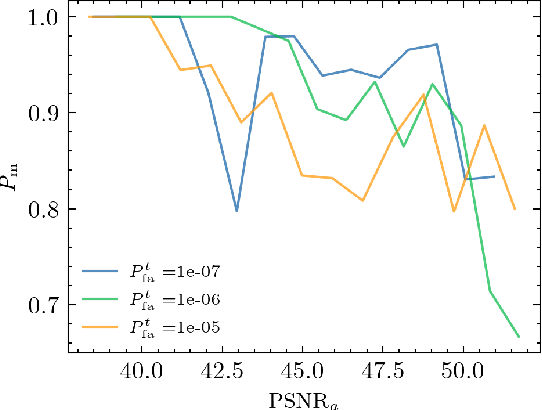
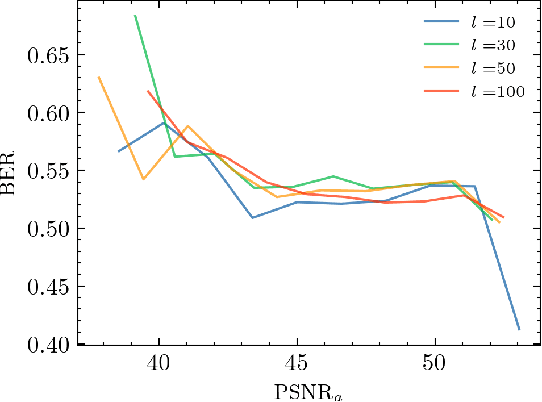
The vast amounts of digital content captured from the real world or AI-generated media necessitate methods for copyright protection, traceability, or data provenance verification. Digital watermarking serves as a crucial approach to address these challenges. Its evolution spans three generations: handcrafted, autoencoder-based, and foundation model based methods. %Its evolution spans three generations: handcrafted methods, autoencoder-based schemes, and methods based on foundation models. While the robustness of these systems is well-documented, the security against adversarial attacks remains underexplored. This paper evaluates the security of foundation models' latent space digital watermarking systems that utilize adversarial embedding techniques. A series of experiments investigate the security dimensions under copy and removal attacks, providing empirical insights into these systems' vulnerabilities. All experimental codes and results are available at https://github.com/vkinakh/ssl-watermarking-attacks}{repository
SWIFT: Semantic Watermarking for Image Forgery Thwarting
Jul 26, 2024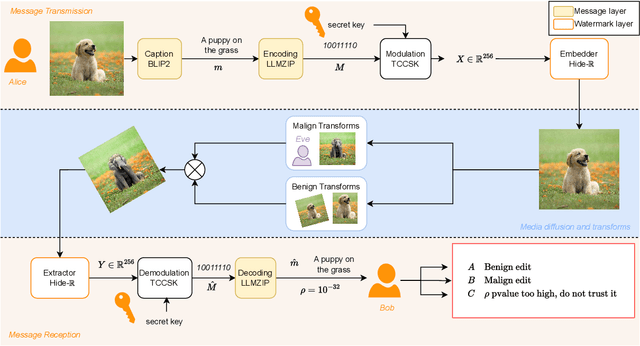
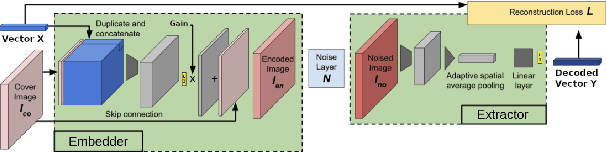
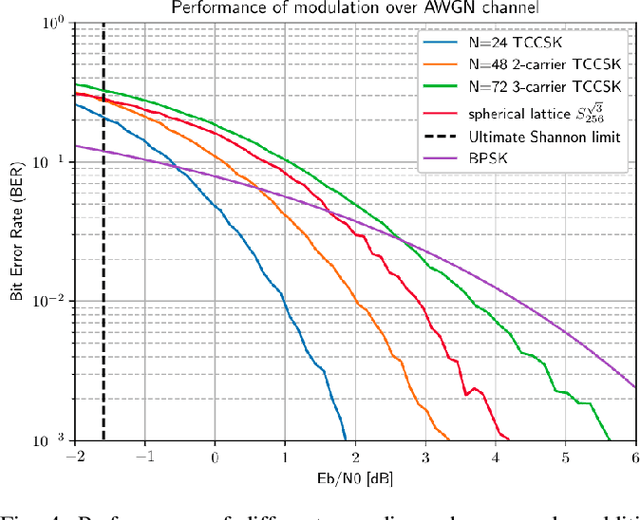
This paper proposes a novel approach towards image authentication and tampering detection by using watermarking as a communication channel for semantic information. We modify the HiDDeN deep-learning watermarking architecture to embed and extract high-dimensional real vectors representing image captions. Our method improves significantly robustness on both malign and benign edits. We also introduce a local confidence metric correlated with Message Recovery Rate, enhancing the method's practical applicability. This approach bridges the gap between traditional watermarking and passive forensic methods, offering a robust solution for image integrity verification.
Watermarking Makes Language Models Radioactive
Feb 22, 2024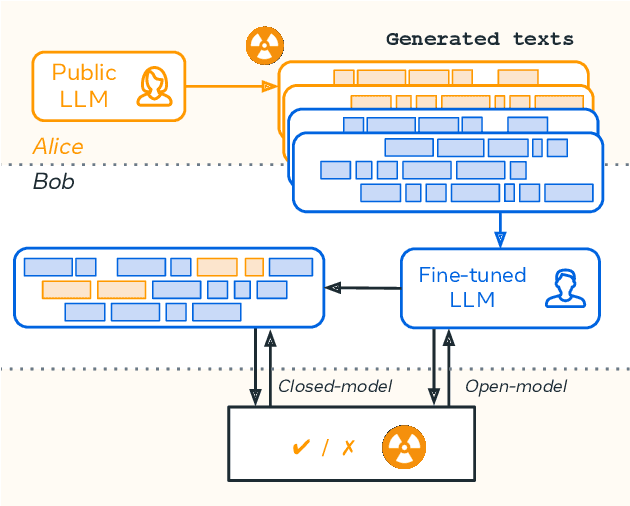
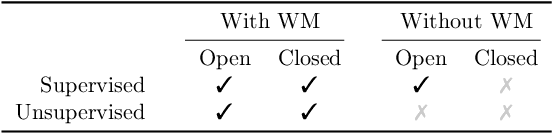
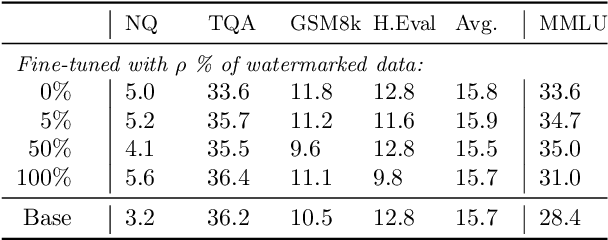
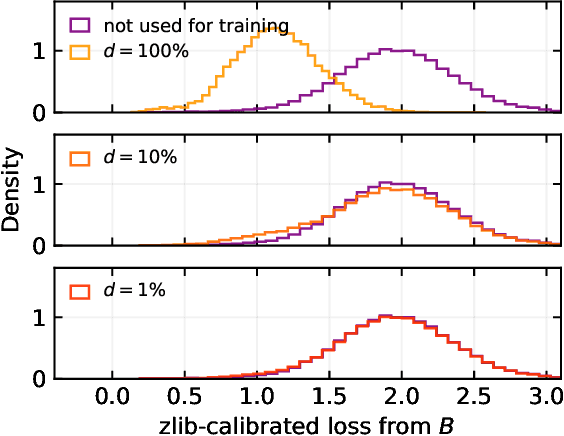
This paper investigates the radioactivity of LLM-generated texts, i.e. whether it is possible to detect that such input was used as training data. Conventional methods like membership inference can carry out this detection with some level of accuracy. We show that watermarked training data leaves traces easier to detect and much more reliable than membership inference. We link the contamination level to the watermark robustness, its proportion in the training set, and the fine-tuning process. We notably demonstrate that training on watermarked synthetic instructions can be detected with high confidence (p-value < 1e-5) even when as little as 5% of training text is watermarked. Thus, LLM watermarking, originally designed for detecting machine-generated text, gives the ability to easily identify if the outputs of a watermarked LLM were used to fine-tune another LLM.
Proactive Detection of Voice Cloning with Localized Watermarking
Jan 30, 2024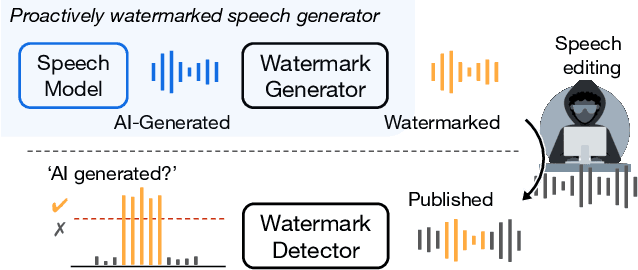
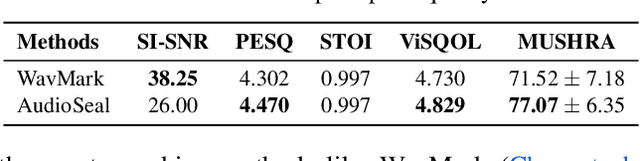
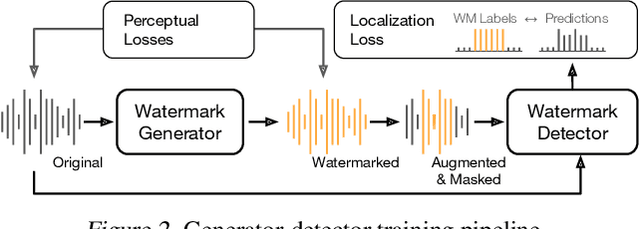
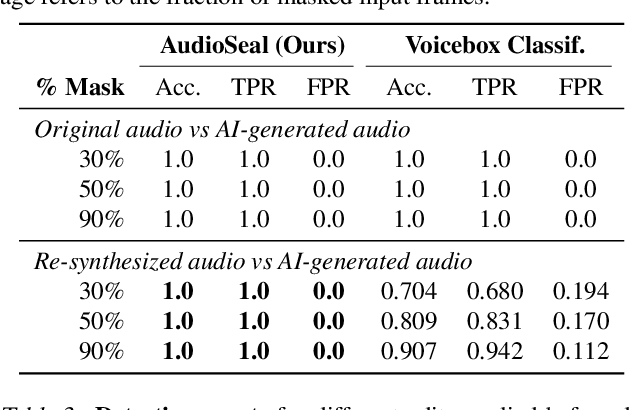
In the rapidly evolving field of speech generative models, there is a pressing need to ensure audio authenticity against the risks of voice cloning. We present AudioSeal, the first audio watermarking technique designed specifically for localized detection of AI-generated speech. AudioSeal employs a generator/detector architecture trained jointly with a localization loss to enable localized watermark detection up to the sample level, and a novel perceptual loss inspired by auditory masking, that enables AudioSeal to achieve better imperceptibility. AudioSeal achieves state-of-the-art performance in terms of robustness to real life audio manipulations and imperceptibility based on automatic and human evaluation metrics. Additionally, AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed - achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.