 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy Backdoor Attack to Deep Neural Networks
Jan 14, 2025



The rise of deep learning (DL) has increased computing complexity and energy use, prompting the adoption of application specific integrated circuits (ASICs) for energy-efficient edge and mobile deployment. However, recent studies have demonstrated the vulnerability of these accelerators to energy attacks. Despite the development of various inference time energy attacks in prior research, backdoor energy attacks remain unexplored. In this paper, we design an innovative energy backdoor attack against deep neural networks (DNNs) operating on sparsity-based accelerators. Our attack is carried out in two distinct phases: backdoor injection and backdoor stealthiness. Experimental results using ResNet-18 and MobileNet-V2 models trained on CIFAR-10 and Tiny ImageNet datasets show the effectiveness of our proposed attack in increasing energy consumption on trigger samples while preserving the model's performance for clean/regular inputs. This demonstrates the vulnerability of DNNs to energy backdoor attacks. The source code of our attack is available at: https://github.com/hbrachemi/energy_backdoor.
Deep Learning for Resilient Adversarial Decision Fusion in Byzantine Networks
Dec 17, 2024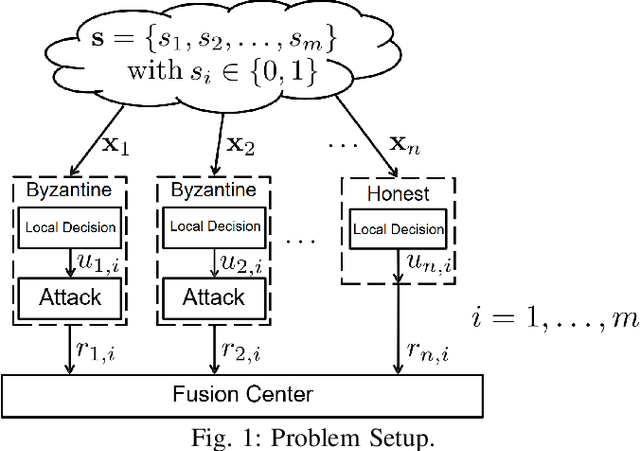
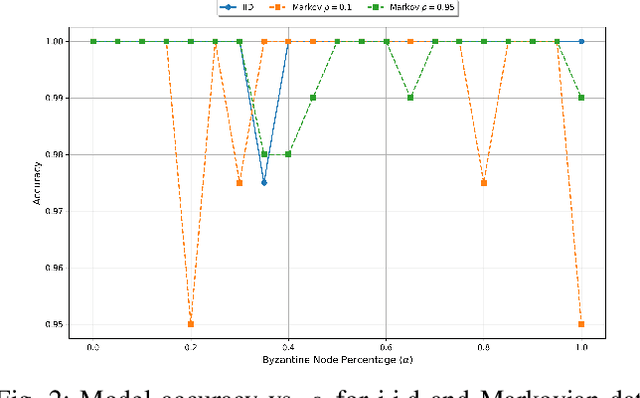
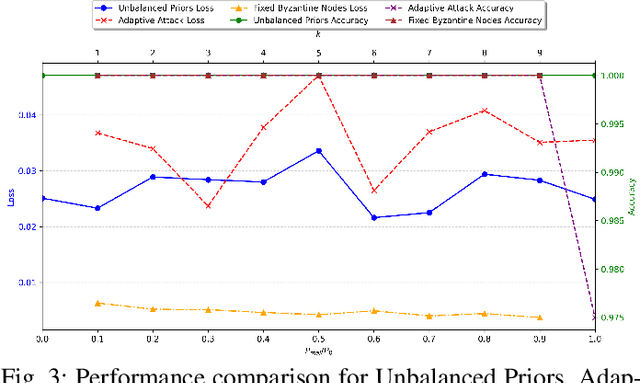
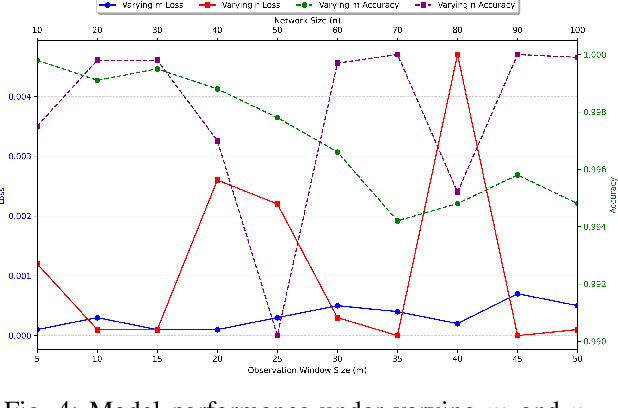
This paper introduces a deep learning-based framework for resilient decision fusion in adversarial multi-sensor networks, providing a unified mathematical setup that encompasses diverse scenarios, including varying Byzantine node proportions, synchronized and unsynchronized attacks, unbalanced priors, adaptive strategies, and Markovian states. Unlike traditional methods, which depend on explicit parameter tuning and are limited by scenario-specific assumptions, the proposed approach employs a deep neural network trained on a globally constructed dataset to generalize across all cases without requiring adaptation. Extensive simulations validate the method's robustness, achieving superior accuracy, minimal error probability, and scalability compared to state-of-the-art techniques, while ensuring computational efficiency for real-time applications. This unified framework demonstrates the potential of deep learning to revolutionize decision fusion by addressing the challenges posed by Byzantine nodes in dynamic adversarial environments.
Mixer: DNN Watermarking using Image Mixup
Dec 06, 2022

It is crucial to protect the intellectual property rights of DNN models prior to their deployment. The DNN should perform two main tasks: its primary task and watermarking task. This paper proposes a lightweight, reliable, and secure DNN watermarking that attempts to establish strong ties between these two tasks. The samples triggering the watermarking task are generated using image Mixup either from training or testing samples. This means that there is an infinity of triggers not limited to the samples used to embed the watermark in the model at training. The extensive experiments on image classification models for different datasets as well as exposing them to a variety of attacks, show that the proposed watermarking provides protection with an adequate level of security and robustness.
ROSE: A RObust and SEcure DNN Watermarking
Jun 22, 2022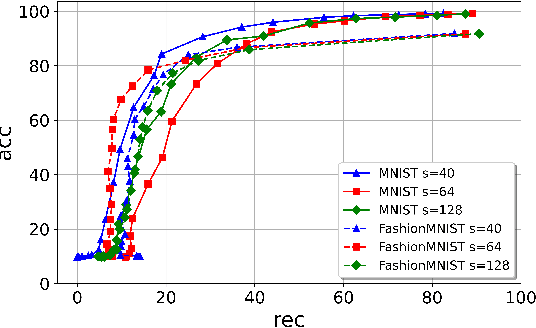
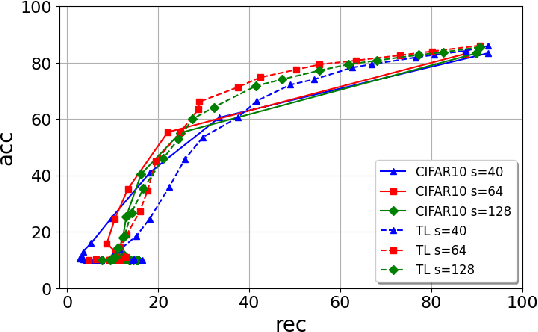
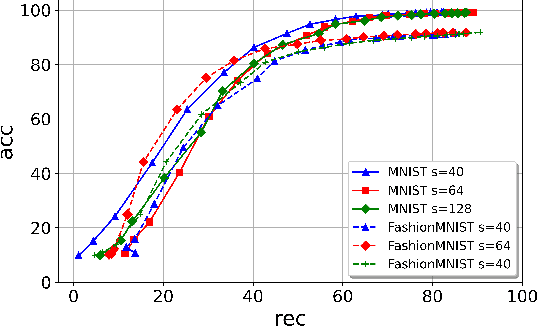
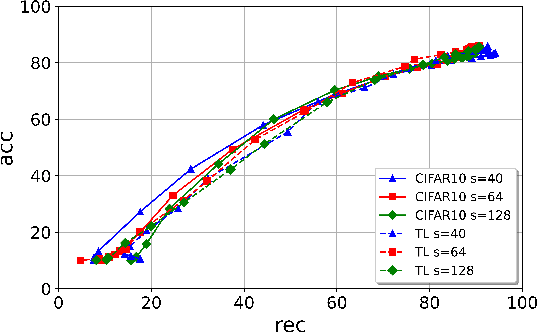
Protecting the Intellectual Property rights of DNN models is of primary importance prior to their deployment. So far, the proposed methods either necessitate changes to internal model parameters or the machine learning pipeline, or they fail to meet both the security and robustness requirements. This paper proposes a lightweight, robust, and secure black-box DNN watermarking protocol that takes advantage of cryptographic one-way functions as well as the injection of in-task key image-label pairs during the training process. These pairs are later used to prove DNN model ownership during testing. The main feature is that the value of the proof and its security are measurable. The extensive experiments watermarking image classification models for various datasets as well as exposing them to a variety of attacks, show that it provides protection while maintaining an adequate level of security and robustness.
CNN Detection of GAN-Generated Face Images based on Cross-Band Co-occurrences Analysis
Jul 25, 2020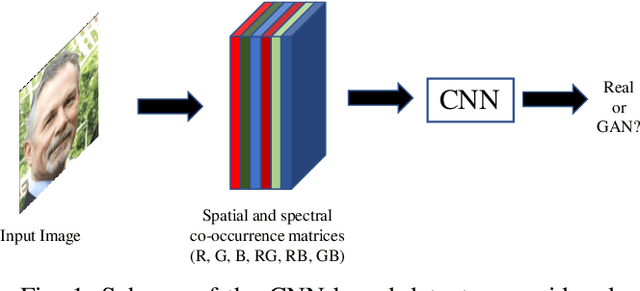

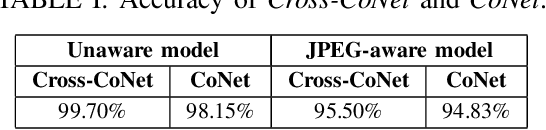
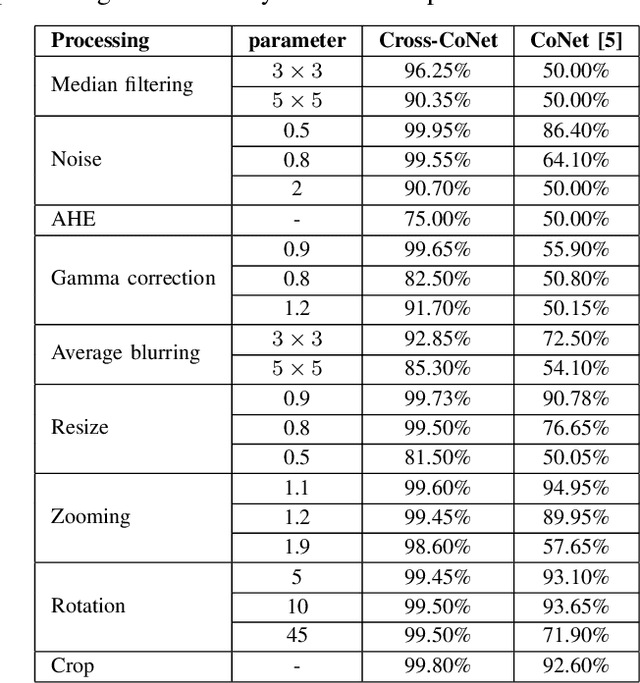
Last-generation GAN models allow to generate synthetic images which are visually indistinguishable from natural ones, raising the need to develop tools to distinguish fake and natural images thus contributing to preserve the trustworthiness of digital images. While modern GAN models can generate very high-quality images with no visible spatial artifacts, reconstruction of consistent relationships among colour channels is expectedly more difficult. In this paper, we propose a method for distinguishing GAN-generated from natural images by exploiting inconsistencies among spectral bands, with specific focus on the generation of synthetic face images. Specifically, we use cross-band co-occurrence matrices, in addition to spatial co-occurrence matrices, as input to a CNN model, which is trained to distinguish between real and synthetic faces. The results of our experiments confirm the goodness of our approach which outperforms a similar detection technique based on intra-band spatial co-occurrences only. The performance gain is particularly significant with regard to robustness against post-processing, like geometric transformations, filtering and contrast manipulations.
A new Backdoor Attack in CNNs by training set corruption without label poisoning
Feb 12, 2019
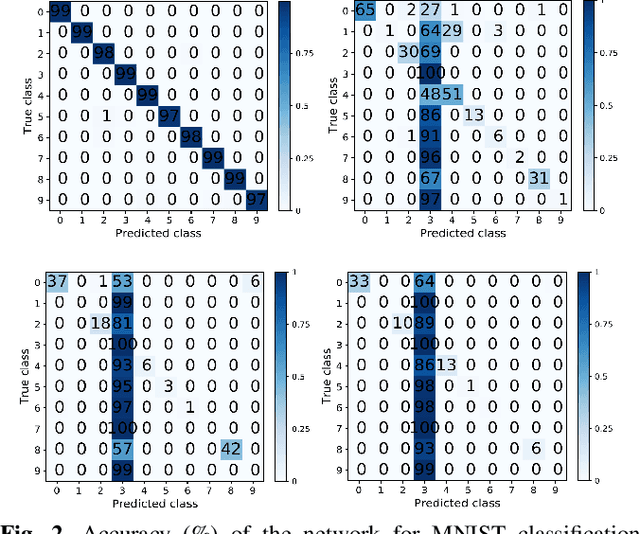

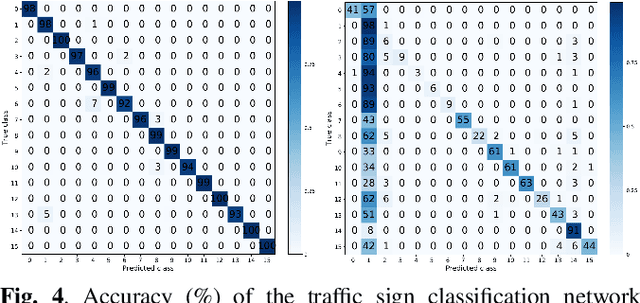
Backdoor attacks against CNNs represent a new threat against deep learning systems, due to the possibility of corrupting the training set so to induce an incorrect behaviour at test time. To avoid that the trainer recognises the presence of the corrupted samples, the corruption of the training set must be as stealthy as possible. Previous works have focused on the stealthiness of the perturbation injected into the training samples, however they all assume that the labels of the corrupted samples are also poisoned. This greatly reduces the stealthiness of the attack, since samples whose content does not agree with the label can be identified by visual inspection of the training set or by running a pre-classification step. In this paper we present a new backdoor attack without label poisoning Since the attack works by corrupting only samples of the target class, it has the additional advantage that it does not need to identify beforehand the class of the samples to be attacked at test time. Results obtained on the MNIST digits recognition task and the traffic signs classification task show that backdoor attacks without label poisoning are indeed possible, thus raising a new alarm regarding the use of deep learning in security-critical applications.