 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new Backdoor Attack in CNNs by training set corruption without label poisoning
Paper and Code
Feb 12, 2019
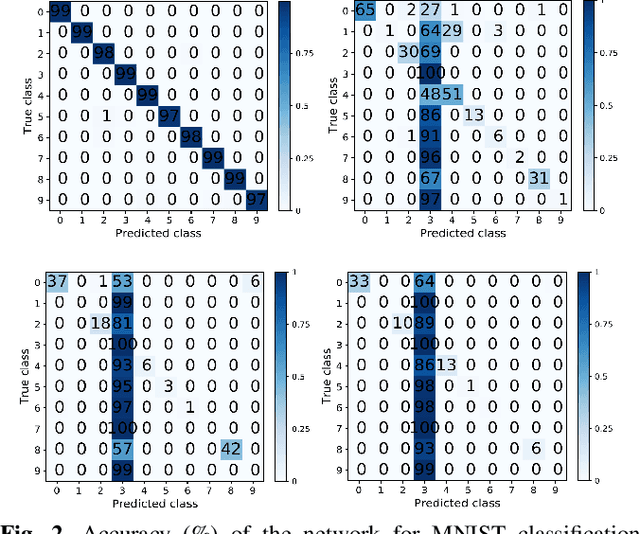

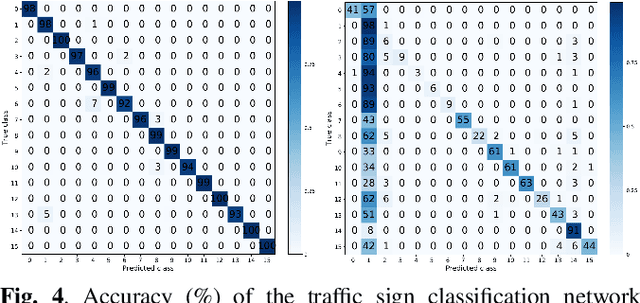
Backdoor attacks against CNNs represent a new threat against deep learning systems, due to the possibility of corrupting the training set so to induce an incorrect behaviour at test time. To avoid that the trainer recognises the presence of the corrupted samples, the corruption of the training set must be as stealthy as possible. Previous works have focused on the stealthiness of the perturbation injected into the training samples, however they all assume that the labels of the corrupted samples are also poisoned. This greatly reduces the stealthiness of the attack, since samples whose content does not agree with the label can be identified by visual inspection of the training set or by running a pre-classification step. In this paper we present a new backdoor attack without label poisoning Since the attack works by corrupting only samples of the target class, it has the additional advantage that it does not need to identify beforehand the class of the samples to be attacked at test time. Results obtained on the MNIST digits recognition task and the traffic signs classification task show that backdoor attacks without label poisoning are indeed possible, thus raising a new alarm regarding the use of deep learning in security-critical applications.