 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial Competition for Low-Complexity Learned Image Compression
May 13, 2026Autoencoder-based image codecs achieve state-of-the-art compression performance but often incur high computational complexity, particularly at decoding time. This work introduces a low-complexity learned image compression framework based on spatial competition between multiple specialized neural codecs. For each image region, the encoder selects the codec that best matches the local content according to a rate-distortion cost. A mode map is transmitted as side information to indicate the per-region codec selection. At decoding time, this mode map-based selection guides reconstruction while preserving the complexity of a single codec. This design enables per-image adaptation with low decoding complexity and fast encoding. On the CLIC 2020 dataset, our method achieves up to -14.5% rate reduction compared to a single codec and reaches HEVC-level performance with a decoding complexity of 1433 MACs per pixel.
Energy Backdoor Attack to Deep Neural Networks
Jan 14, 2025



The rise of deep learning (DL) has increased computing complexity and energy use, prompting the adoption of application specific integrated circuits (ASICs) for energy-efficient edge and mobile deployment. However, recent studies have demonstrated the vulnerability of these accelerators to energy attacks. Despite the development of various inference time energy attacks in prior research, backdoor energy attacks remain unexplored. In this paper, we design an innovative energy backdoor attack against deep neural networks (DNNs) operating on sparsity-based accelerators. Our attack is carried out in two distinct phases: backdoor injection and backdoor stealthiness. Experimental results using ResNet-18 and MobileNet-V2 models trained on CIFAR-10 and Tiny ImageNet datasets show the effectiveness of our proposed attack in increasing energy consumption on trigger samples while preserving the model's performance for clean/regular inputs. This demonstrates the vulnerability of DNNs to energy backdoor attacks. The source code of our attack is available at: https://github.com/hbrachemi/energy_backdoor.
Overfitted image coding at reduced complexity
Mar 18, 2024Overfitted image codecs offer compelling compression performance and low decoder complexity, through the overfitting of a lightweight decoder for each image. Such codecs include Cool-chic, which presents image coding performance on par with VVC while requiring around 2000 multiplications per decoded pixel. This paper proposes to decrease Cool-chic encoding and decoding complexity. The encoding complexity is reduced by shortening Cool-chic training, up to the point where no overfitting is performed at all. It is also shown that a tiny neural decoder with 300 multiplications per pixel still outperforms HEVC. A near real-time CPU implementation of this decoder is made available at https://orange-opensource.github.io/Cool-Chic/.
Cool-chic video: Learned video coding with 800 parameters
Feb 06, 2024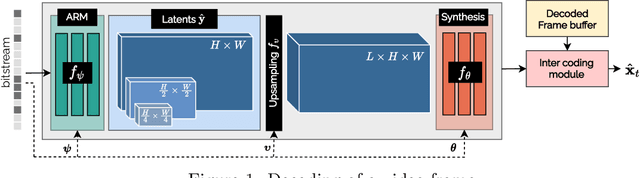

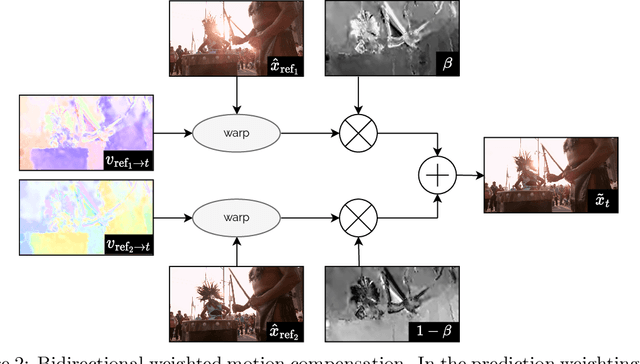
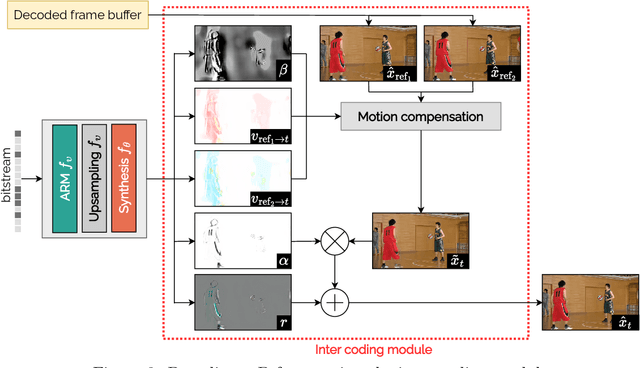
We propose a lightweight learned video codec with 900 multiplications per decoded pixel and 800 parameters overall. To the best of our knowledge, this is one of the neural video codecs with the lowest decoding complexity. It is built upon the overfitted image codec Cool-chic and supplements it with an inter coding module to leverage the video's temporal redundancies. The proposed model is able to compress videos using both low-delay and random access configurations and achieves rate-distortion close to AVC while out-performing other overfitted codecs such as FFNeRV. The system is made open-source: orange-opensource.github.io/Cool-Chic.
Efficient Predictive Coding of Intra Prediction Modes
Oct 09, 2023

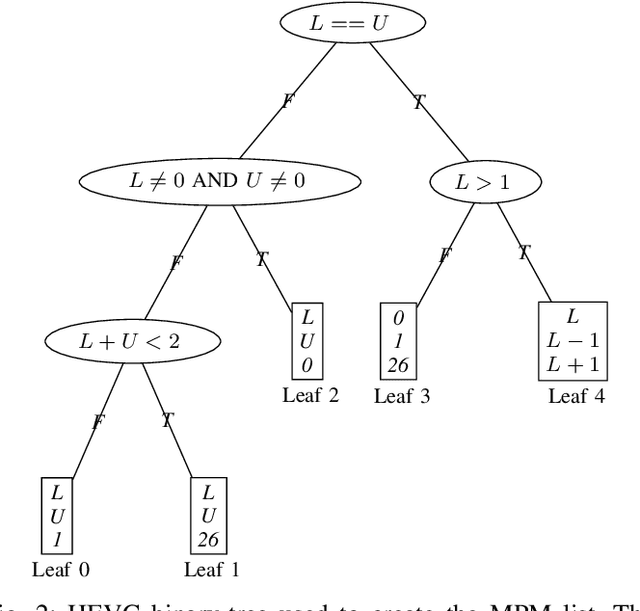

The high efficiency video coding (HEVC) standard and the joint exploration model (JEM) codec incorporate 35 and 67 intra prediction modes (IPMs) respectively, which are essential for efficient compression of Intra coded blocks. These IPMs are transmitted to the decoder through a coding scheme. In our paper, we present an innovative approach to construct a dedicated coding scheme for IPM based on contextual information. This approach comprises three key steps: prediction, clustering, and coding, each of which has been enhanced by introducing new elements, namely, labels for prediction, tests for clustering, and codes for coding. In this context, we have proposed a method that utilizes a genetic algorithm to minimize the rate cost, aiming to derive the most efficient coding scheme while leveraging the available labels, tests, and codes. The resulting coding scheme, expressed as a binary tree, achieves the highest coding efficiency for a given level of complexity. In our experimental evaluation under the HEVC standard, we observed significant bitrate gains while maintaining coding efficiency under the JEM codec. These results demonstrate the potential of our approach to improve compression efficiency, particularly under the HEVC standard, while preserving the coding efficiency of the JEM codec.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Federated Adversarial Training with Transformers
Jun 05, 2022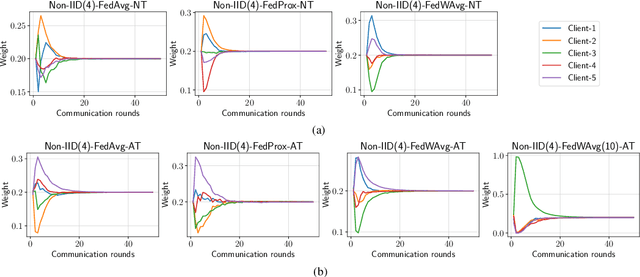
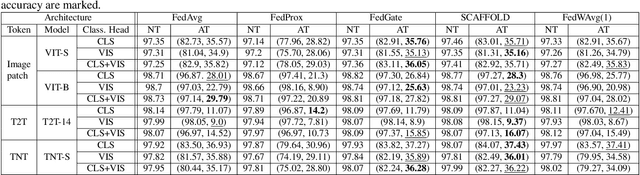
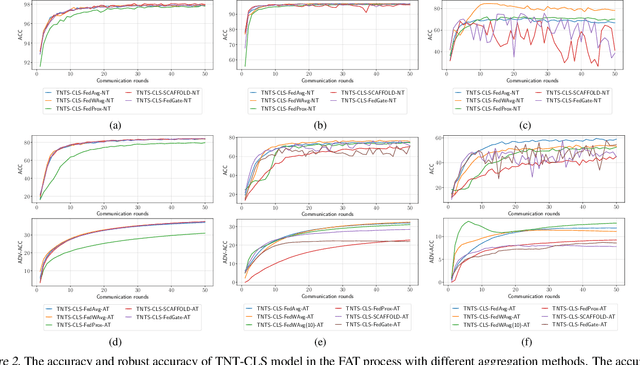
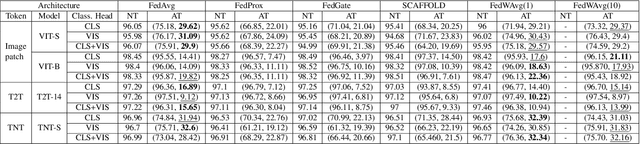
Federated learning (FL) has emerged to enable global model training over distributed clients' data while preserving its privacy. However, the global trained model is vulnerable to the evasion attacks especially, the adversarial examples (AEs), carefully crafted samples to yield false classification. Adversarial training (AT) is found to be the most promising approach against evasion attacks and it is widely studied for convolutional neural network (CNN). Recently, vision transformers have been found to be effective in many computer vision tasks. To the best of the authors' knowledge, there is no work that studied the feasibility of AT in a FL process for vision transformers. This paper investigates such feasibility with different federated model aggregation methods and different vision transformer models with different tokenization and classification head techniques. In order to improve the robust accuracy of the models with the not independent and identically distributed (Non-IID), we propose an extension to FedAvg aggregation method, called FedWAvg. By measuring the similarities between the last layer of the global model and the last layer of the client updates, FedWAvg calculates the weights to aggregate the local models updates. The experiments show that FedWAvg improves the robust accuracy when compared with other state-of-the-art aggregation methods.
Lightweight Hardware Design of the Inverse Transform Module for 4K ASIC VVC Decoders
Jul 24, 2021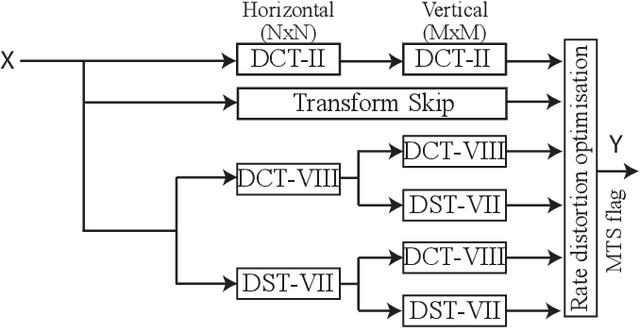
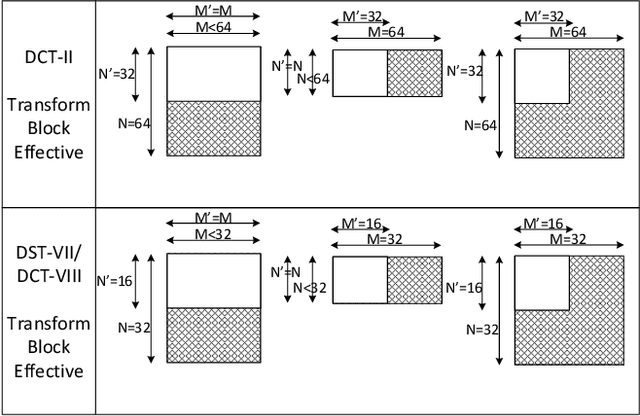
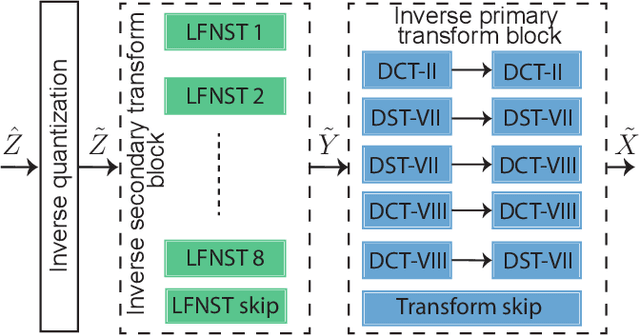
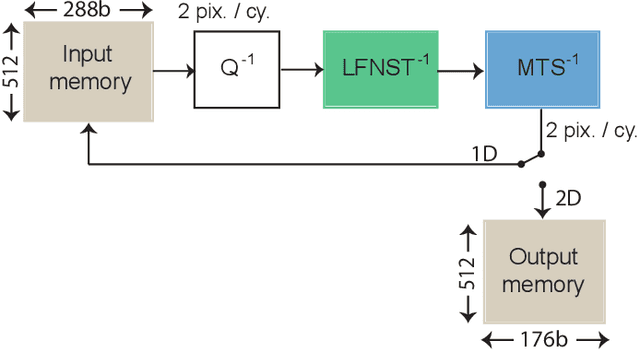
Versatile Video Coding (VVC) is the next generation video coding standard finalized in July 2020. VVC introduces new coding tools enhancing the coding efficiency compared to its predecessor High Efficiency Video Coding (HEVC). These new tools have a significant impact on the VVC software decoder complexity estimated to 2 times HEVC decoder complexity. In particular, the transform module includes in VVC separable and non-separable transforms named Multiple Transform Selection (MTS) and Low Frequency Non-Separable Transform (LFNST) tools, respectively. In this paper, we present an area-efficient hardware architecture of the inverse transform module for a VVC decoder. The proposed design uses a total of 64 regular multipliers in a pipelined architecture targeting ASIC platforms. It consists in a multi-standard architecture that supports the transform modules of recent MPEG standards including AVC, HEVC and VVC. The architecture leverages all primary and secondary transforms optimisations including butterfly decomposition, coefficients zeroing and the inherent linear relationship between the transforms. The synthesized results show that the proposed method sustains a constant throughput of 1 sample per cycle and a constant latency for all block sizes. The proposed hardware inverse transform module operates at 600 MHz frequency enabling to decode in real-time 4K video at 30 frames per second in 4:2:2 chroma sub-sampling format. The proposed module is integrated in an ASIC UHD decoder targeting energy-aware decoding of VVC videos on consumer devices.
Conditional Coding for Flexible Learned Video Compression
Apr 28, 2021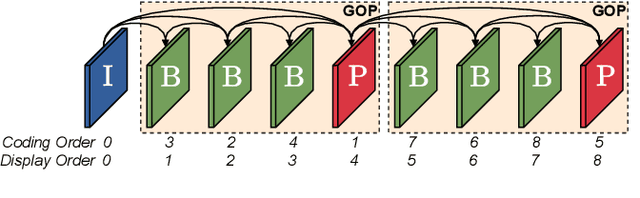

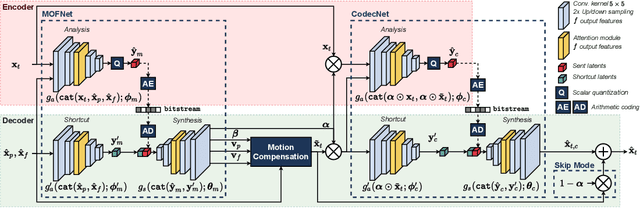
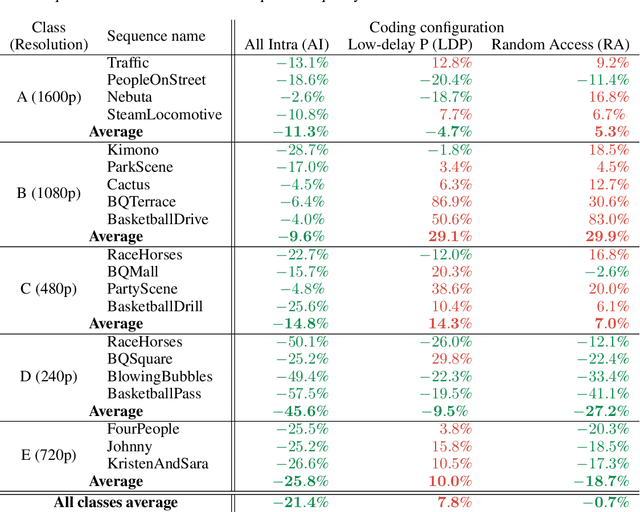
This paper introduces a novel framework for end-to-end learned video coding. Image compression is generalized through conditional coding to exploit information from reference frames, allowing to process intra and inter frames with the same coder. The system is trained through the minimization of a rate-distortion cost, with no pre-training or proxy loss. Its flexibility is assessed under three coding configurations (All Intra, Low-delay P and Random Access), where it is shown to achieve performance competitive with the state-of-the-art video codec HEVC.
Conditional Coding and Variable Bitrate for Practical Learned Video Coding
Apr 20, 2021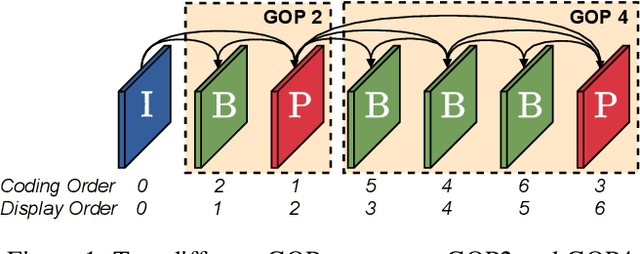

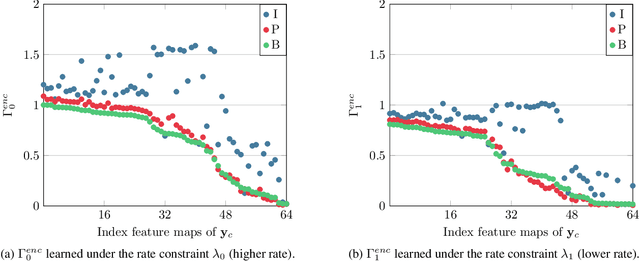

This paper introduces a practical learned video codec. Conditional coding and quantization gain vectors are used to provide flexibility to a single encoder/decoder pair, which is able to compress video sequences at a variable bitrate. The flexibility is leveraged at test time by choosing the rate and GOP structure to optimize a rate-distortion cost. Using the CLIC21 video test conditions, the proposed approach shows performance on par with HEVC.