 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Latency Attacks: A New Adversarial Threat to Deep Learning
Mar 06, 2025The growing computational demand for deep neural networks ( DNNs) has raised concerns about their energy consumption and carbon footprint, particularly as the size and complexity of the models continue to increase. To address these challenges, energy-efficient hardware and custom accelerators have become essential. Additionally, adaptable DNN s are being developed to dynamically balance performance and efficiency. The use of these strategies became more common to enable sustainable AI deployment. However, these efficiency-focused designs may also introduce vulnerabilities, as attackers can potentially exploit them to increase latency and energy usage by triggering their worst-case-performance scenarios. This new type of attack, called energy-latency attacks, has recently gained significant research attention, focusing on the vulnerability of DNN s to this emerging attack paradigm, which can trigger denial-of-service ( DoS) attacks. This paper provides a comprehensive overview of current research on energy-latency attacks, categorizing them using the established taxonomy for traditional adversarial attacks. We explore different metrics used to measure the success of these attacks and provide an analysis and comparison of existing attack strategies. We also analyze existing defense mechanisms and highlight current challenges and potential areas for future research in this developing field. The GitHub page for this work can be accessed at https://github.com/hbrachemi/Survey_energy_attacks/
Energy Backdoor Attack to Deep Neural Networks
Jan 14, 2025



The rise of deep learning (DL) has increased computing complexity and energy use, prompting the adoption of application specific integrated circuits (ASICs) for energy-efficient edge and mobile deployment. However, recent studies have demonstrated the vulnerability of these accelerators to energy attacks. Despite the development of various inference time energy attacks in prior research, backdoor energy attacks remain unexplored. In this paper, we design an innovative energy backdoor attack against deep neural networks (DNNs) operating on sparsity-based accelerators. Our attack is carried out in two distinct phases: backdoor injection and backdoor stealthiness. Experimental results using ResNet-18 and MobileNet-V2 models trained on CIFAR-10 and Tiny ImageNet datasets show the effectiveness of our proposed attack in increasing energy consumption on trigger samples while preserving the model's performance for clean/regular inputs. This demonstrates the vulnerability of DNNs to energy backdoor attacks. The source code of our attack is available at: https://github.com/hbrachemi/energy_backdoor.
Bitrate Ladder Prediction Methods for Adaptive Video Streaming: A Review and Benchmark
Oct 30, 2023HTTP adaptive streaming (HAS) has emerged as a widely adopted approach for over-the-top (OTT) video streaming services, due to its ability to deliver a seamless streaming experience. A key component of HAS is the bitrate ladder, which provides the encoding parameters (e.g., bitrate-resolution pairs) to encode the source video. The representations in the bitrate ladder allow the client's player to dynamically adjust the quality of the video stream based on network conditions by selecting the most appropriate representation from the bitrate ladder. The most straightforward and lowest complexity approach involves using a fixed bitrate ladder for all videos, consisting of pre-determined bitrate-resolution pairs known as one-size-fits-all. Conversely, the most reliable technique relies on intensively encoding all resolutions over a wide range of bitrates to build the convex hull, thereby optimizing the bitrate ladder for each specific video. Several techniques have been proposed to predict content-based ladders without performing a costly exhaustive search encoding. This paper provides a comprehensive review of various methods, including both conventional and learning-based approaches. Furthermore, we conduct a benchmark study focusing exclusively on various learning-based approaches for predicting content-optimized bitrate ladders across multiple codec settings. The considered methods are evaluated on our proposed large-scale dataset, which includes 300 UHD video shots encoded with software and hardware encoders using three state-of-the-art encoders, including AVC/H.264, HEVC/H.265, and VVC/H.266, at various bitrate points. Our analysis provides baseline methods and insights, which will be valuable for future research in the field of bitrate ladder prediction. The source code of the proposed benchmark and the dataset will be made publicly available upon acceptance of the paper.
NTIRE 2023 Quality Assessment of Video Enhancement Challenge
Jul 19, 2023



This paper reports on the NTIRE 2023 Quality Assessment of Video Enhancement Challenge, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2023. This challenge is to address a major challenge in the field of video processing, namely, video quality assessment (VQA) for enhanced videos. The challenge uses the VQA Dataset for Perceptual Video Enhancement (VDPVE), which has a total of 1211 enhanced videos, including 600 videos with color, brightness, and contrast enhancements, 310 videos with deblurring, and 301 deshaked videos. The challenge has a total of 167 registered participants. 61 participating teams submitted their prediction results during the development phase, with a total of 3168 submissions. A total of 176 submissions were submitted by 37 participating teams during the final testing phase. Finally, 19 participating teams submitted their models and fact sheets, and detailed the methods they used. Some methods have achieved better results than baseline methods, and the winning methods have demonstrated superior prediction performance.
Evaluation of Pre-Trained CNN Models for Geographic Fake Image Detection
Oct 01, 2022


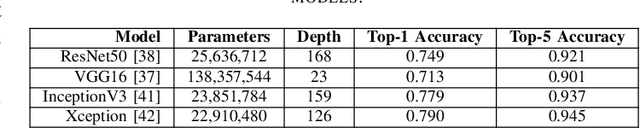
Thanks to the remarkable advances in generative adversarial networks (GANs), it is becoming increasingly easy to generate/manipulate images. The existing works have mainly focused on deepfake in face images and videos. However, we are currently witnessing the emergence of fake satellite images, which can be misleading or even threatening to national security. Consequently, there is an urgent need to develop detection methods capable of distinguishing between real and fake satellite images. To advance the field, in this paper, we explore the suitability of several convolutional neural network (CNN) architectures for fake satellite image detection. Specifically, we benchmark four CNN models by conducting extensive experiments to evaluate their performance and robustness against various image distortions. This work allows the establishment of new baselines and may be useful for the development of CNN-based methods for fake satellite image detection.
2BiVQA: Double Bi-LSTM based Video Quality Assessment of UGC Videos
Aug 31, 2022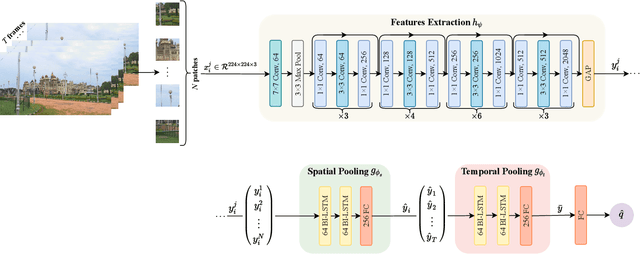
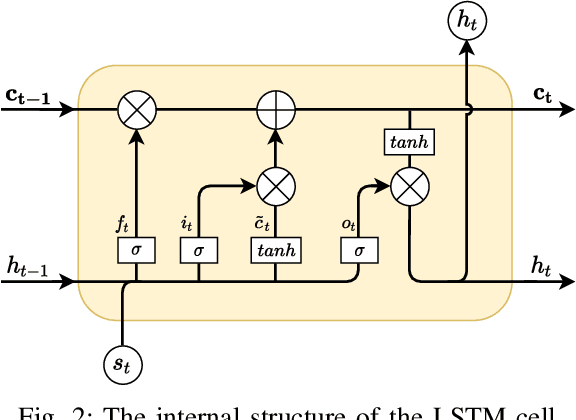
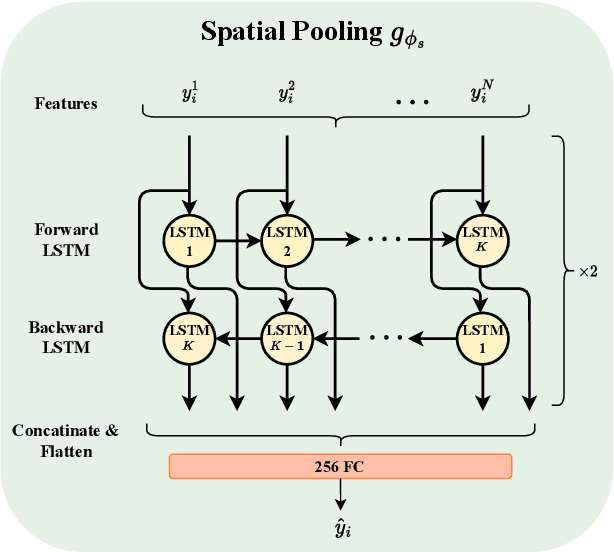
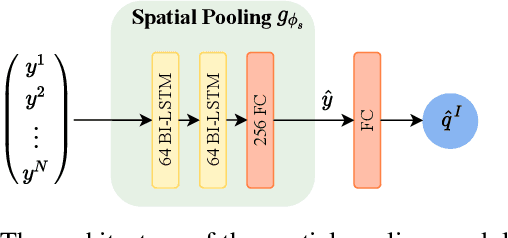
Recently, with the growing popularity of mobile devices as well as video sharing platforms (e.g., YouTube, Facebook, TikTok, and Twitch), User-Generated Content (UGC) videos have become increasingly common and now account for a large portion of multimedia traffic on the internet. Unlike professionally generated videos produced by filmmakers and videographers, typically, UGC videos contain multiple authentic distortions, generally introduced during capture and processing by naive users. Quality prediction of UGC videos is of paramount importance to optimize and monitor their processing in hosting platforms, such as their coding, transcoding, and streaming. However, blind quality prediction of UGC is quite challenging because the degradations of UGC videos are unknown and very diverse, in addition to the unavailability of pristine reference. Therefore, in this paper, we propose an accurate and efficient Blind Video Quality Assessment (BVQA) model for UGC videos, which we name 2BiVQA for double Bi-LSTM Video Quality Assessment. 2BiVQA metric consists of three main blocks, including a pre-trained Convolutional Neural Network (CNN) to extract discriminative features from image patches, which are then fed into two Recurrent Neural Networks (RNNs) for spatial and temporal pooling. Specifically, we use two Bi-directional Long Short Term Memory (Bi-LSTM) networks, the first is used to capture short-range dependencies between image patches, while the second allows capturing long-range dependencies between frames to account for the temporal memory effect. Experimental results on recent large-scale UGC video quality datasets show that 2BiVQA achieves high performance at a lower computational cost than state-of-the-art models. The source code of our 2BiVQA metric is made publicly available at: https://github.com/atelili/2BiVQA.
Detect and Defense Against Adversarial Examples in Deep Learning using Natural Scene Statistics and Adaptive Denoising
Jul 12, 2021


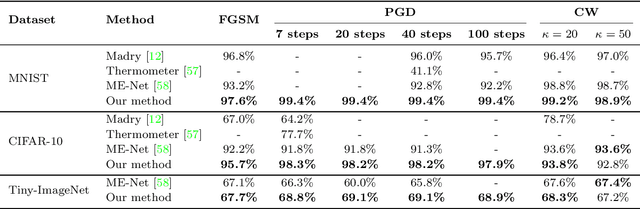
Despite the enormous performance of deepneural networks (DNNs), recent studies have shown theirvulnerability to adversarial examples (AEs), i.e., care-fully perturbed inputs designed to fool the targetedDNN. Currently, the literature is rich with many ef-fective attacks to craft such AEs. Meanwhile, many de-fenses strategies have been developed to mitigate thisvulnerability. However, these latter showed their effec-tiveness against specific attacks and does not general-ize well to different attacks. In this paper, we proposea framework for defending DNN classifier against ad-versarial samples. The proposed method is based on atwo-stage framework involving a separate detector anda denoising block. The detector aims to detect AEs bycharacterizing them through the use of natural scenestatistic (NSS), where we demonstrate that these statis-tical features are altered by the presence of adversarialperturbations. The denoiser is based on block matching3D (BM3D) filter fed by an optimum threshold valueestimated by a convolutional neural network (CNN) toproject back the samples detected as AEs into theirdata manifold. We conducted a complete evaluation onthree standard datasets namely MNIST, CIFAR-10 andTiny-ImageNet. The experimental results show that theproposed defense method outperforms the state-of-the-art defense techniques by improving the robustnessagainst a set of attacks under black-box, gray-box and white-box settings. The source code is available at: https://github.com/kherchouche-anouar/2DAE
NTIRE 2021 Challenge on Perceptual Image Quality Assessment
May 11, 2021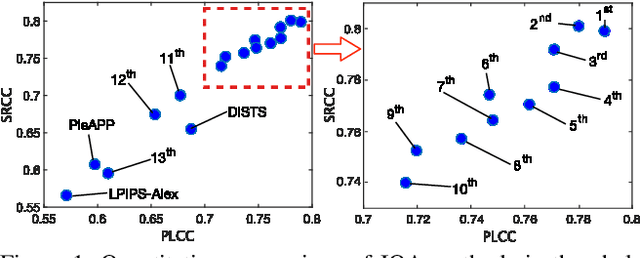
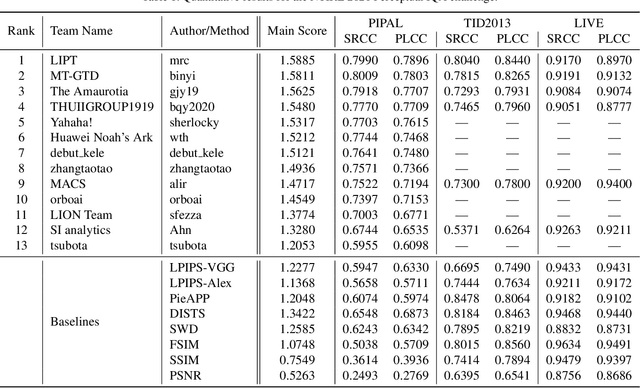

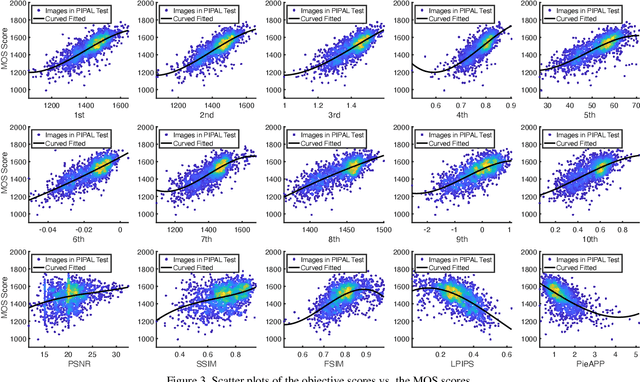
This paper reports on the NTIRE 2021 challenge on perceptual image quality assessment (IQA), held in conjunction with the New Trends in Image Restoration and Enhancement workshop (NTIRE) workshop at CVPR 2021. As a new type of image processing technology, perceptual image processing algorithms based on Generative Adversarial Networks (GAN) have produced images with more realistic textures. These output images have completely different characteristics from traditional distortions, thus pose a new challenge for IQA methods to evaluate their visual quality. In comparison with previous IQA challenges, the training and testing datasets in this challenge include the outputs of perceptual image processing algorithms and the corresponding subjective scores. Thus they can be used to develop and evaluate IQA methods on GAN-based distortions. The challenge has 270 registered participants in total. In the final testing stage, 13 participating teams submitted their models and fact sheets. Almost all of them have achieved much better results than existing IQA methods, while the winning method can demonstrate state-of-the-art performance.
Adversarial Example Detection for DNN Models: A Review
May 01, 2021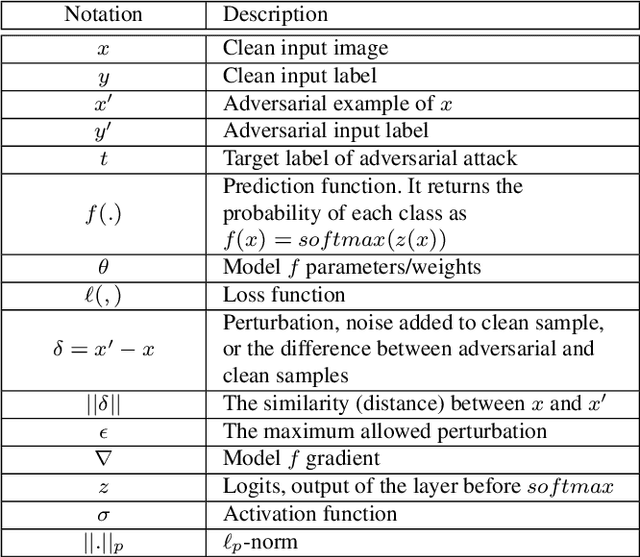
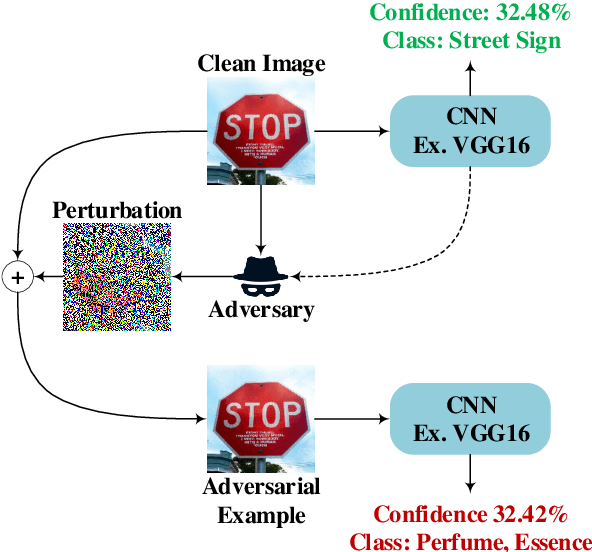
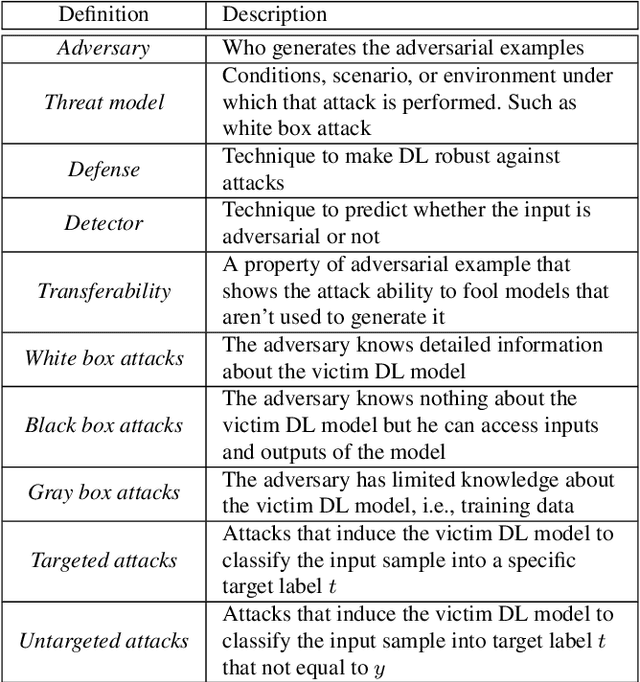
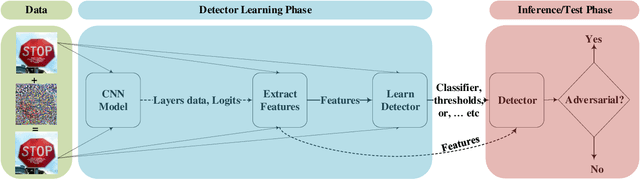
Deep Learning (DL) has shown great success in many human-related tasks, which has led to its adoption in many computer vision based applications, such as security surveillance system, autonomous vehicles and healthcare. Such safety-critical applications have to draw its path to success deployment once they have the capability to overcome safety-critical challenges. Among these challenges are the defense against or/and the detection of the adversarial example (AE). Adversary can carefully craft small, often imperceptible, noise called perturbations, to be added to the clean image to generate the AE. The aim of AE is to fool the DL model which makes it a potential risk for DL applications. Many test-time evasion attacks and countermeasures, i.e., defense or detection methods, are proposed in the literature. Moreover, few reviews and surveys were published and theoretically showed the taxonomy of the threats and the countermeasure methods with little focus in AE detection methods. In this paper, we attempt to provide a theoretical and experimental review for AE detection methods. A detailed discussion for such methods is provided and experimental results for eight state-of-the-art detectors are presented under different scenarios on four datasets. We also provide potential challenges and future perspectives for this research direction.
Light Field Image Coding Using VVC standard and View Synthesis based on Dual Discriminator GAN
Mar 06, 2021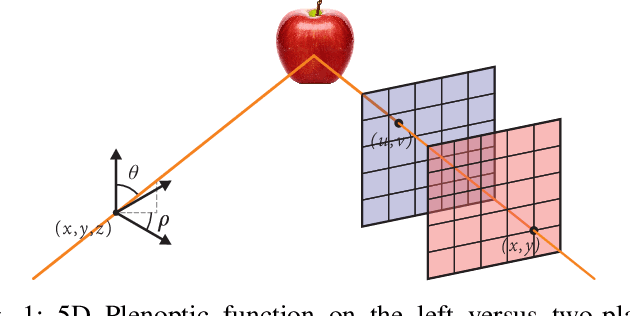



Light field (LF) technology is considered as a promising way for providing a high-quality virtual reality (VR) content. However, such an imaging technology produces a large amount of data requiring efficient LF image compression solutions. In this paper, we propose a LF image coding method based on a view synthesis and view quality enhancement techniques. Instead of transmitting all the LF views, only a sparse set of reference views are encoded and transmitted, while the remaining views are synthesized at the decoder side. The transmitted views are encoded using the versatile video coding (VVC) standard and are used as reference views to synthesize the dropped views. The selection of non-reference dropped views is performed using a rate-distortion optimization based on the VVC temporal scalability. The dropped views are reconstructed using the LF dual discriminator GAN (LF-D2GAN) model. In addition, to ensure that the quality of the views is consistent, at the decoder, a quality enhancement procedure is performed on the reconstructed views allowing smooth navigation across views. Experimental results show that the proposed method provides high coding performance and overcomes the state-of-the-art LF image compression methods by -36.22% in terms of BD-BR and 1.35 dB in BD-PSNR. The web page of this work is available at https://naderbakir79.github.io/LFD2GAN.html.