 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Example Detection for DNN Models: A Review
Paper and Code
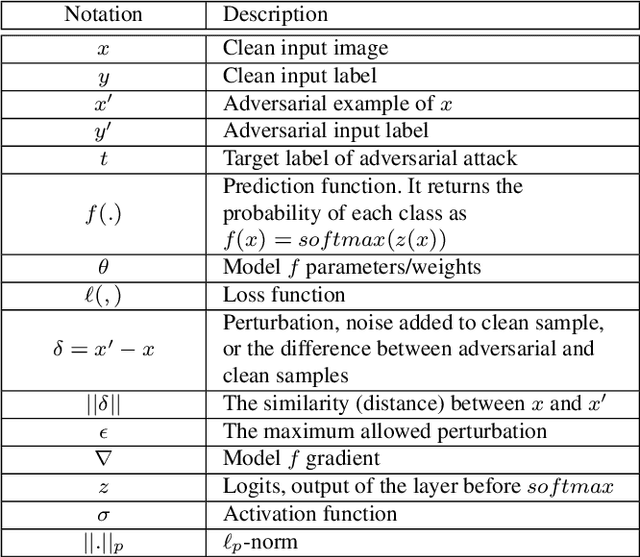
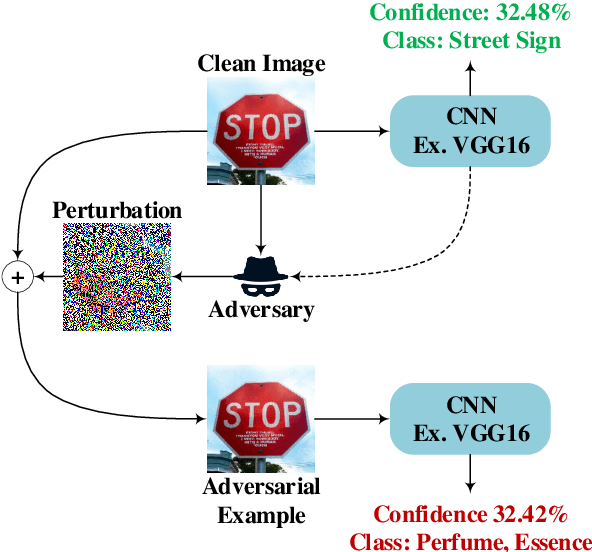
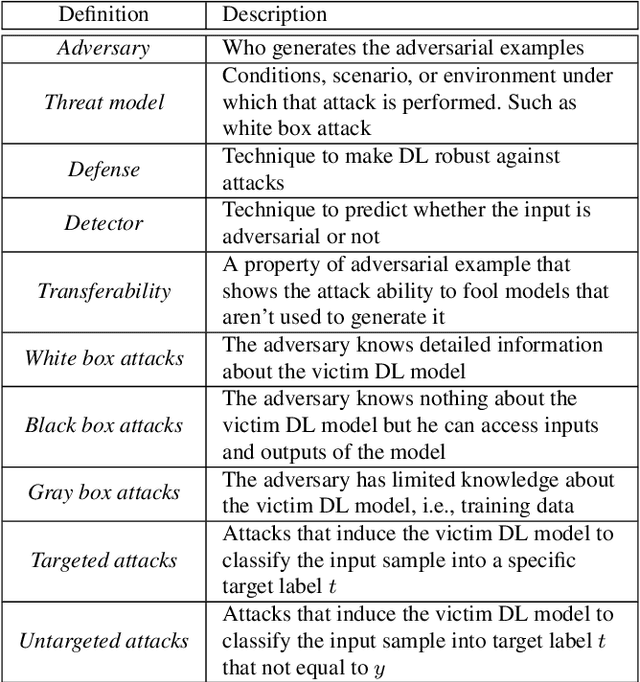
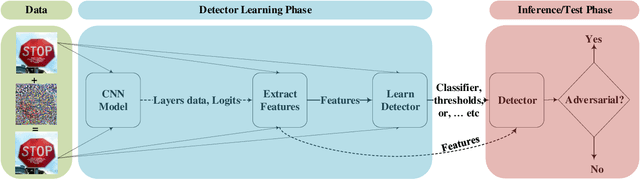
Deep Learning (DL) has shown great success in many human-related tasks, which has led to its adoption in many computer vision based applications, such as security surveillance system, autonomous vehicles and healthcare. Such safety-critical applications have to draw its path to success deployment once they have the capability to overcome safety-critical challenges. Among these challenges are the defense against or/and the detection of the adversarial example (AE). Adversary can carefully craft small, often imperceptible, noise called perturbations, to be added to the clean image to generate the AE. The aim of AE is to fool the DL model which makes it a potential risk for DL applications. Many test-time evasion attacks and countermeasures, i.e., defense or detection methods, are proposed in the literature. Moreover, few reviews and surveys were published and theoretically showed the taxonomy of the threats and the countermeasure methods with little focus in AE detection methods. In this paper, we attempt to provide a theoretical and experimental review for AE detection methods. A detailed discussion for such methods is provided and experimental results for eight state-of-the-art detectors are presented under different scenarios on four datasets. We also provide potential challenges and future perspectives for this research direction.