 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Latency Attacks: A New Adversarial Threat to Deep Learning
Mar 06, 2025The growing computational demand for deep neural networks ( DNNs) has raised concerns about their energy consumption and carbon footprint, particularly as the size and complexity of the models continue to increase. To address these challenges, energy-efficient hardware and custom accelerators have become essential. Additionally, adaptable DNN s are being developed to dynamically balance performance and efficiency. The use of these strategies became more common to enable sustainable AI deployment. However, these efficiency-focused designs may also introduce vulnerabilities, as attackers can potentially exploit them to increase latency and energy usage by triggering their worst-case-performance scenarios. This new type of attack, called energy-latency attacks, has recently gained significant research attention, focusing on the vulnerability of DNN s to this emerging attack paradigm, which can trigger denial-of-service ( DoS) attacks. This paper provides a comprehensive overview of current research on energy-latency attacks, categorizing them using the established taxonomy for traditional adversarial attacks. We explore different metrics used to measure the success of these attacks and provide an analysis and comparison of existing attack strategies. We also analyze existing defense mechanisms and highlight current challenges and potential areas for future research in this developing field. The GitHub page for this work can be accessed at https://github.com/hbrachemi/Survey_energy_attacks/
Improved Encoding for Overfitted Video Codecs
Jan 28, 2025Overfitted neural video codecs offer a decoding complexity orders of magnitude smaller than their autoencoder counterparts. Yet, this low complexity comes at the cost of limited compression efficiency, in part due to their difficulty capturing accurate motion information. This paper proposes to guide motion information learning with an optical flow estimator. A joint rate-distortion optimization is also introduced to improve rate distribution across the different frames. These contributions maintain a low decoding complexity of 1300 multiplications per pixel while offering compression performance close to the conventional codec HEVC and outperforming other overfitted codecs. This work is made open-source at https://orange-opensource. github.io/Cool-Chic/
CAESR: Conditional Autoencoder and Super-Resolution for Learned Spatial Scalability
Feb 01, 2022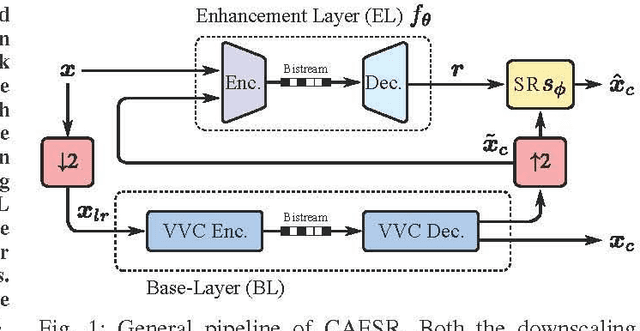
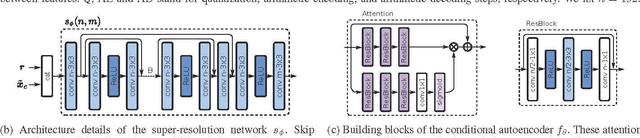
In this paper, we present CAESR, an hybrid learning-based coding approach for spatial scalability based on the versatile video coding (VVC) standard. Our framework considers a low-resolution signal encoded with VVC intra-mode as a base-layer (BL), and a deep conditional autoencoder with hyperprior (AE-HP) as an enhancement-layer (EL) model. The EL encoder takes as inputs both the upscaled BL reconstruction and the original image. Our approach relies on conditional coding that learns the optimal mixture of the source and the upscaled BL image, enabling better performance than residual coding. On the decoder side, a super-resolution (SR) module is used to recover high-resolution details and invert the conditional coding process. Experimental results have shown that our solution is competitive with the VVC full-resolution intra coding while being scalable.
Perceptual Quality Assessment of HEVC and VVC Standards for 8K Video
Sep 17, 2021
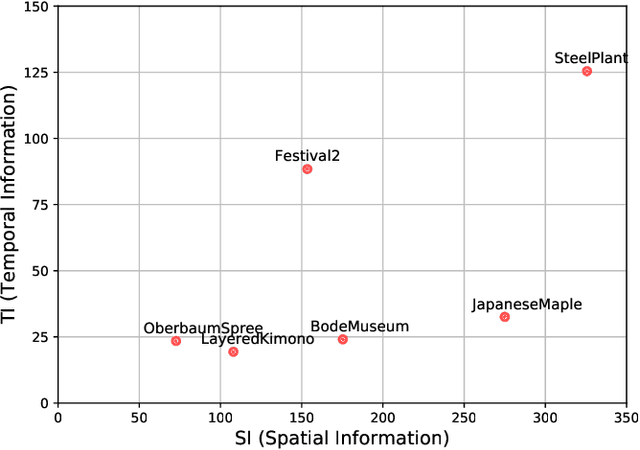
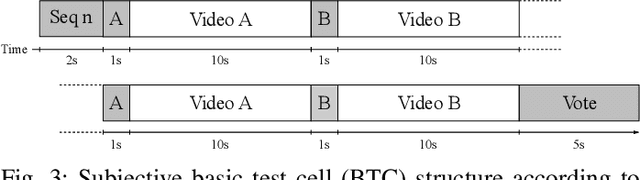

With the growing data consumption of emerging video applications and users requirement for higher resolutions, up to 8K, a huge effort has been made in video compression technologies. Recently, versatile video coding (VVC) has been standardized by the moving picture expert group (MPEG), providing a significant improvement in compression performance over its predecessor high efficiency video coding (HEVC). In this paper, we provide a comparative subjective quality evaluation between VVC and HEVC standards for 8K resolution videos. In addition, we evaluate the perceived quality improvement offered by 8K over UHD 4K resolution. The compression performance of both VVC and HEVC standards has been conducted in random access (RA) coding configuration, using their respective reference software, VVC test model (VTM-11) and HEVC test model (HM-16.20). Objective measurements, using PSNR, MS-SSIM and VMAF metrics have shown that the bitrate gains offered by VVC over HEVC for 8K video content are around 31%, 26% and 35%, respectively. Subjectively, VVC offers an average of 40% of bitrate reduction over HEVC for the same visual quality. A compression gain of 50% has been reached for some tested video sequences regarding a Student t-test analysis. In addition, for most tested scenes, a significant visual difference between uncompressed 4K and 8K has been noticed.
Reveal of Vision Transformers Robustness against Adversarial Attacks
Jun 07, 2021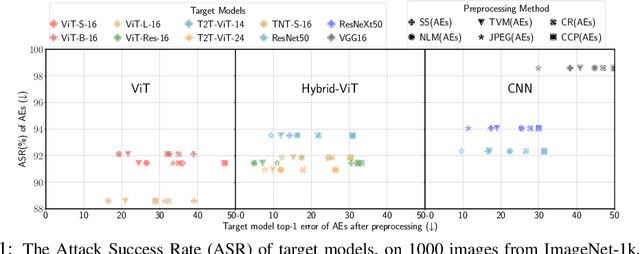
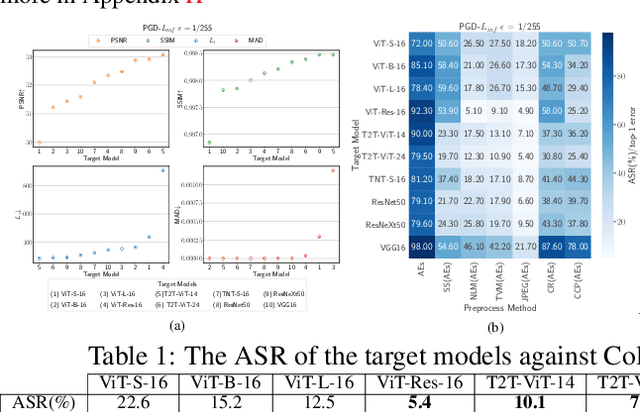
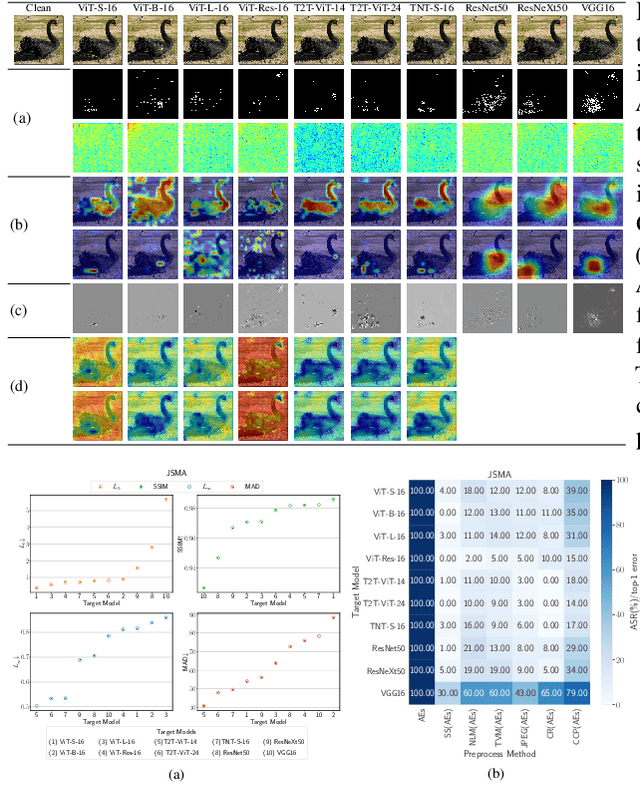
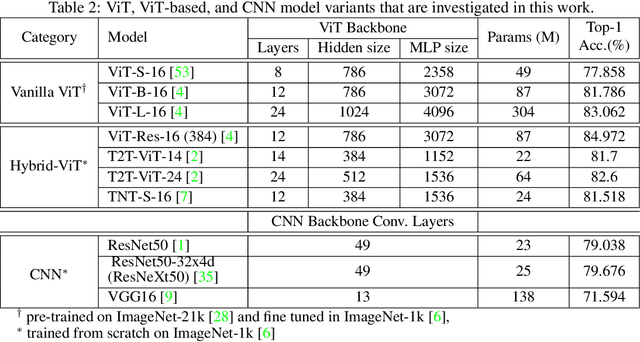
Attention-based networks have achieved state-of-the-art performance in many computer vision tasks, such as image classification. Unlike Convolutional Neural Network (CNN), the major part of the vanilla Vision Transformer (ViT) is the attention block that brings the power of mimicking the global context of the input image. This power is data hunger and hence, the larger the training data the better the performance. To overcome this limitation, many ViT-based networks, or hybrid-ViT, have been proposed to include local context during the training. The robustness of ViTs and its variants against adversarial attacks has not been widely invested in the literature. Some robustness attributes were revealed in few previous works and hence, more insight robustness attributes are yet unrevealed. This work studies the robustness of ViT variants 1) against different $L_p$-based adversarial attacks in comparison with CNNs and 2) under Adversarial Examples (AEs) after applying preprocessing defense methods. To that end, we run a set of experiments on 1000 images from ImageNet-1k and then provide an analysis that reveals that vanilla ViT or hybrid-ViT are more robust than CNNs. For instance, we found that 1) Vanilla ViTs or hybrid-ViTs are more robust than CNNs under $L_0$, $L_1$, $L_2$, $L_\infty$-based, and Color Channel Perturbations (CCP) attacks. 2) Vanilla ViTs are not responding to preprocessing defenses that mainly reduce the high frequency components while, hybrid-ViTs are more responsive to such defense. 3) CCP can be used as a preprocessing defense and larger ViT variants are found to be more responsive than other models. Furthermore, feature maps, attention maps, and Grad-CAM visualization jointly with image quality measures, and perturbations' energy spectrum are provided for an insight understanding of attention-based models.
SHD360: A Benchmark Dataset for Salient Human Detection in 360° Videos
Jun 04, 2021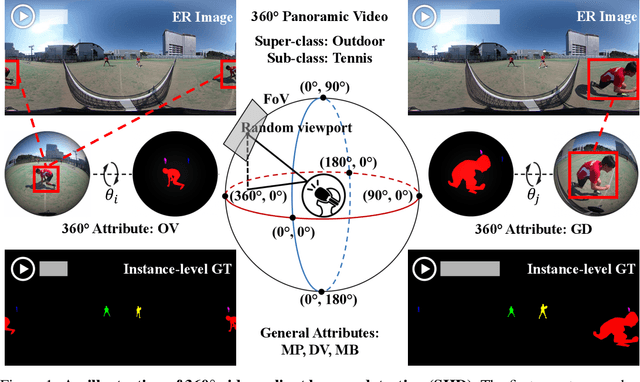
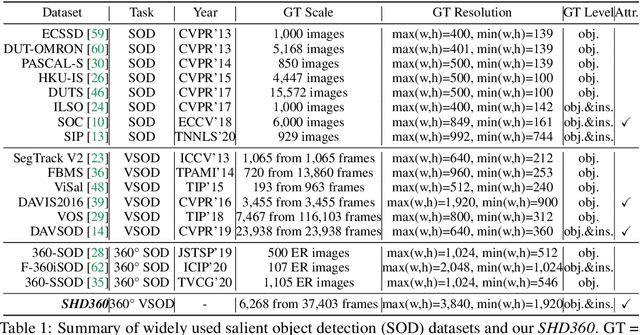
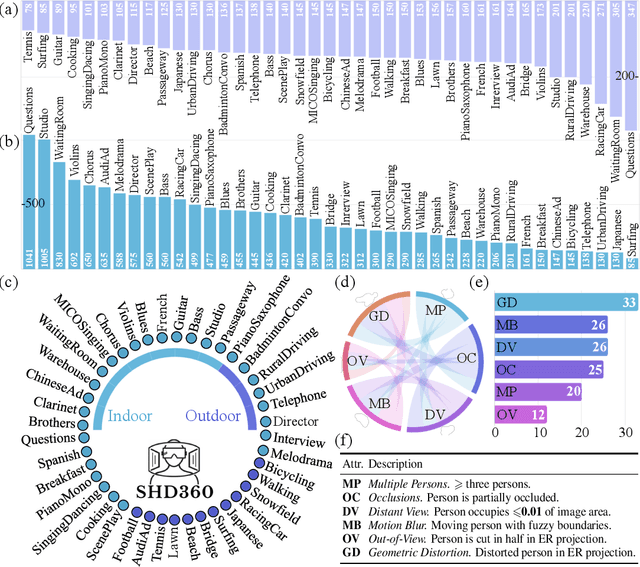
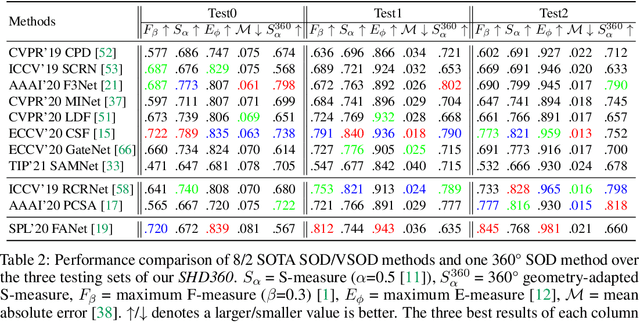
Salient human detection (SHD) in dynamic 360{\deg} immersive videos is of great importance for various applications such as robotics, inter-human and human-object interaction in augmented reality. However, 360{\deg} video SHD has been seldom discussed in the computer vision community due to a lack of datasets with large-scale omnidirectional videos and rich annotations. To this end, we propose SHD360, the first 360{\deg} video SHD dataset containing various real-life daily scenes borrowed from http://hidden.for.anonymity, with hierarchical annotations for 6,268 key frames uniformly sampled from 37,403 omnidirectional video frames at 4K resolution. Since so far there is no method proposed for 360{\deg} image/video SHD, we systematically benchmark 11 representative state-of-the-art salient object detection approaches on our SHD360. We hope our proposed dataset and benchmark could serve as a good starting point for advancing human-centric researches towards 360{\deg} panoramic data. Our dataset and benchmark will be publicly available at https://github.com/PanoAsh/SHD360.
Learning Synergistic Attention for Light Field Salient Object Detection
May 16, 2021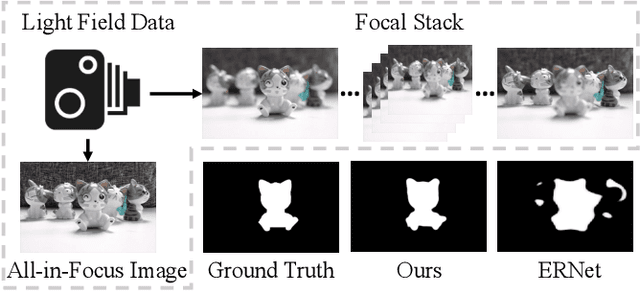
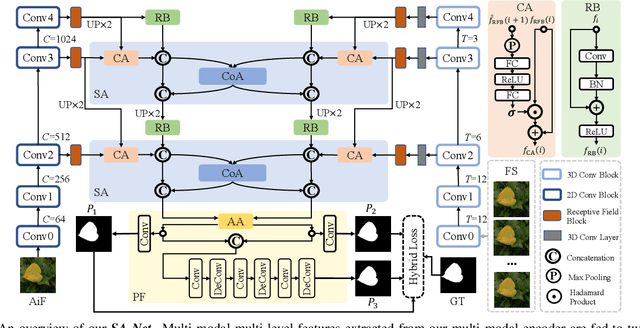
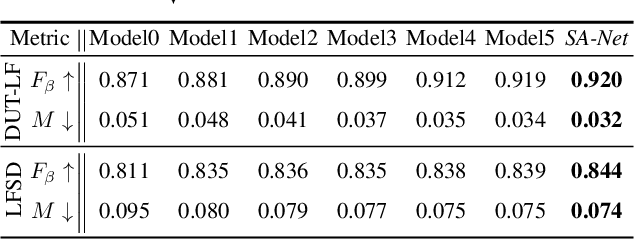
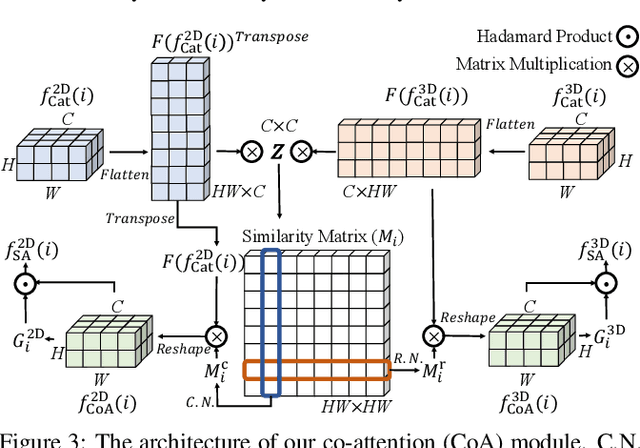
We propose a novel Synergistic Attention Network (SA-Net) to address the light field salient object detection by establishing a synergistic effect between multi-modal features with advanced attention mechanisms. Our SA-Net exploits the rich information of focal stacks via 3D convolutional neural networks, decodes the high-level features of multi-modal light field data with two cascaded synergistic attention modules, and predicts the saliency map using an effective feature fusion module in a progressive manner. Extensive experiments on three widely-used benchmark datasets show that our SA-Net outperforms 28 state-of-the-art models, sufficiently demonstrating its effectiveness and superiority. Our code will be made publicly available.
CMA-Net: A Cascaded Mutual Attention Network for Light Field Salient Object Detection
May 07, 2021
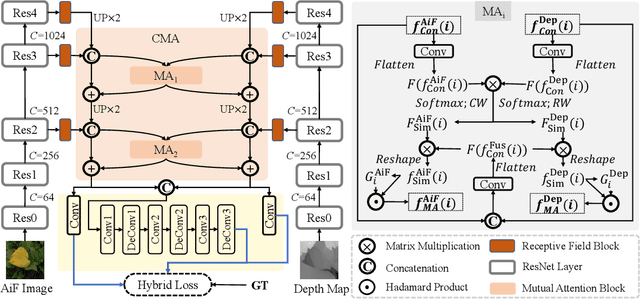
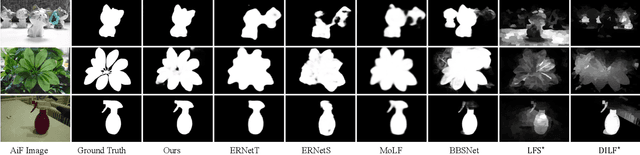
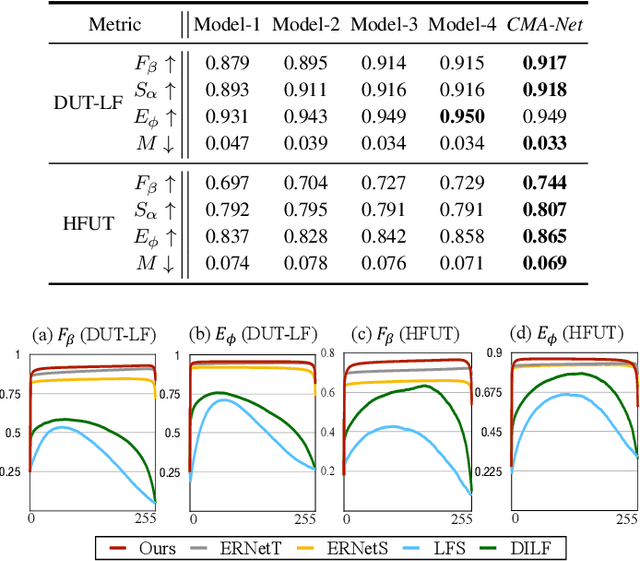
In the past few years, numerous deep learning methods have been proposed to address the task of segmenting salient objects from RGB images. However, these approaches depending on single modality fail to achieve the state-of-the-art performance on widely used light field salient object detection (SOD) datasets, which collect large-scale natural images and provide multiple modalities such as multi-view, micro-lens images and depth maps. Most recently proposed light field SOD methods have acquired improving detecting accuracy, yet still predict rough objects' structures and perform slow inference speed. To this end, we propose CMA-Net, which consists of two novel cascaded mutual attention modules aiming at fusing the high level features from the modalities of all-in-focus and depth. Our proposed CMA-Net outperforms 30 SOD methods (by a large margin) on two widely applied light field benchmark datasets. Besides, the proposed CMA-Net can run at a speed of 53 fps, thus being four times faster than the state-of-the-art multi-modal SOD methods. Extensive quantitative and qualitative experiments illustrate both the effectiveness and efficiency of our CMA-Net, inspiring future development of multi-modal learning for both the RGB-D and light field SOD.
Multitask Learning for VVC Quality Enhancement and Super-Resolution
May 03, 2021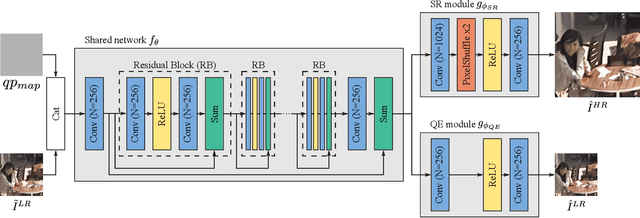
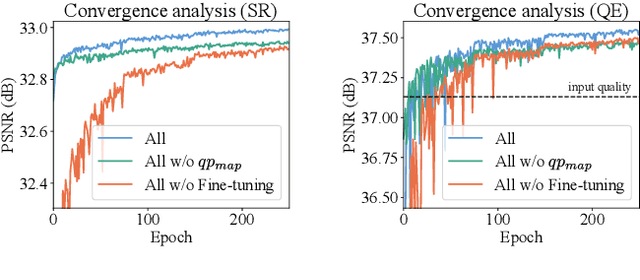

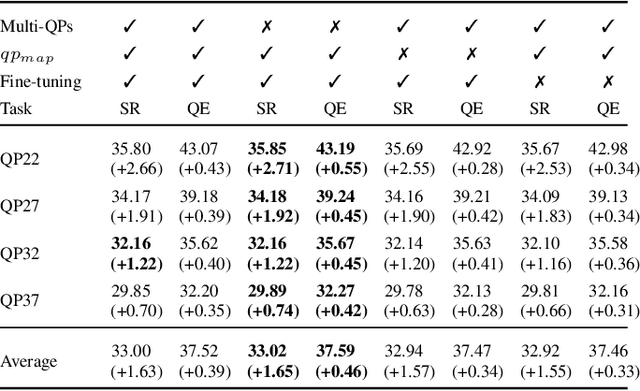
The latest video coding standard, called versatile video coding (VVC), includes several novel and refined coding tools at different levels of the coding chain. These tools bring significant coding gains with respect to the previous standard, high efficiency video coding (HEVC). However, the encoder may still introduce visible coding artifacts, mainly caused by coding decisions applied to adjust the bitrate to the available bandwidth. Hence, pre and post-processing techniques are generally added to the coding pipeline to improve the quality of the decoded video. These methods have recently shown outstanding results compared to traditional approaches, thanks to the recent advances in deep learning. Generally, multiple neural networks are trained independently to perform different tasks, thus omitting to benefit from the redundancy that exists between the models. In this paper, we investigate a learning-based solution as a post-processing step to enhance the decoded VVC video quality. Our method relies on multitask learning to perform both quality enhancement and super-resolution using a single shared network optimized for multiple degradation levels. The proposed solution enables a good performance in both mitigating coding artifacts and super-resolution with fewer network parameters compared to traditional specialized architectures.
Adversarial Example Detection for DNN Models: A Review
May 01, 2021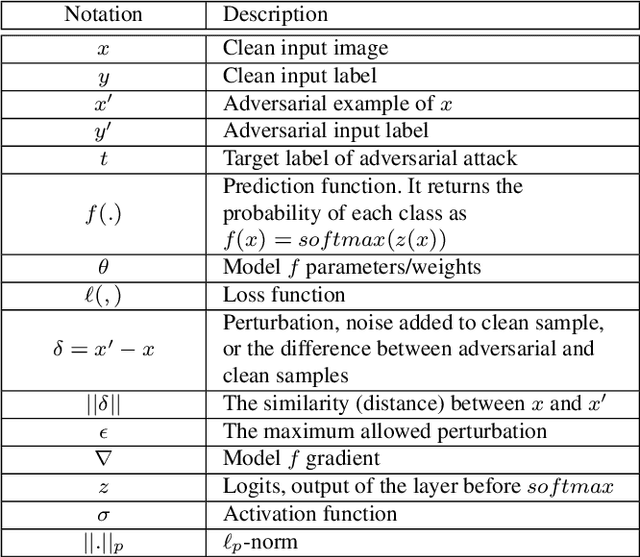
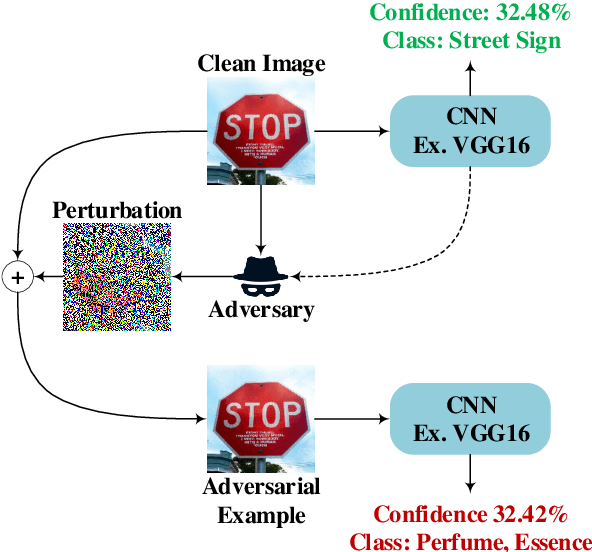
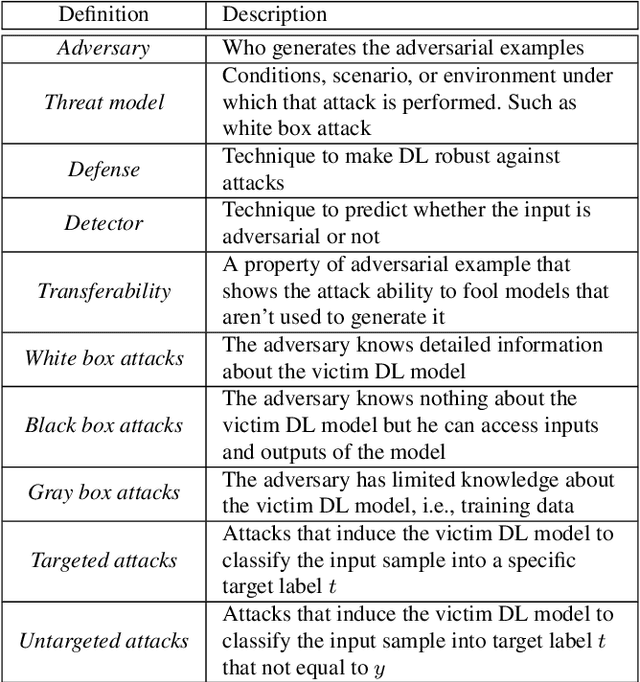
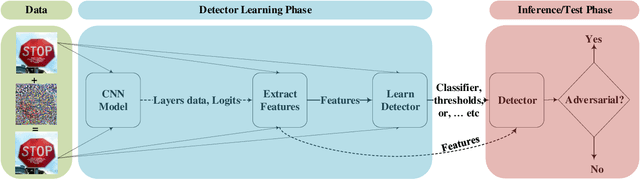
Deep Learning (DL) has shown great success in many human-related tasks, which has led to its adoption in many computer vision based applications, such as security surveillance system, autonomous vehicles and healthcare. Such safety-critical applications have to draw its path to success deployment once they have the capability to overcome safety-critical challenges. Among these challenges are the defense against or/and the detection of the adversarial example (AE). Adversary can carefully craft small, often imperceptible, noise called perturbations, to be added to the clean image to generate the AE. The aim of AE is to fool the DL model which makes it a potential risk for DL applications. Many test-time evasion attacks and countermeasures, i.e., defense or detection methods, are proposed in the literature. Moreover, few reviews and surveys were published and theoretically showed the taxonomy of the threats and the countermeasure methods with little focus in AE detection methods. In this paper, we attempt to provide a theoretical and experimental review for AE detection methods. A detailed discussion for such methods is provided and experimental results for eight state-of-the-art detectors are presented under different scenarios on four datasets. We also provide potential challenges and future perspectives for this research direction.