 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMA-Net: A Cascaded Mutual Attention Network for Light Field Salient Object Detection
Paper and Code
May 07, 2021
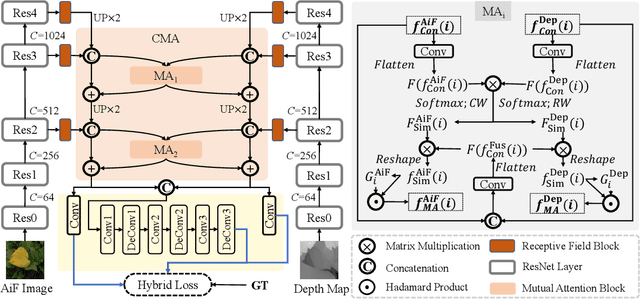
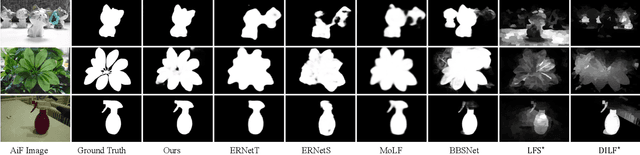
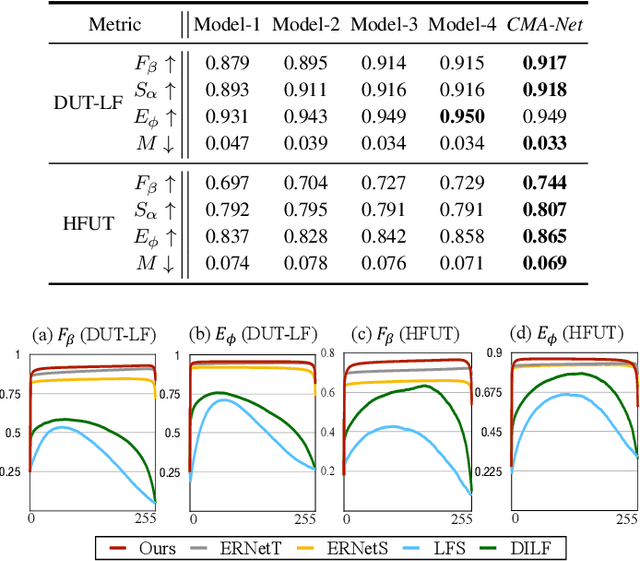
In the past few years, numerous deep learning methods have been proposed to address the task of segmenting salient objects from RGB images. However, these approaches depending on single modality fail to achieve the state-of-the-art performance on widely used light field salient object detection (SOD) datasets, which collect large-scale natural images and provide multiple modalities such as multi-view, micro-lens images and depth maps. Most recently proposed light field SOD methods have acquired improving detecting accuracy, yet still predict rough objects' structures and perform slow inference speed. To this end, we propose CMA-Net, which consists of two novel cascaded mutual attention modules aiming at fusing the high level features from the modalities of all-in-focus and depth. Our proposed CMA-Net outperforms 30 SOD methods (by a large margin) on two widely applied light field benchmark datasets. Besides, the proposed CMA-Net can run at a speed of 53 fps, thus being four times faster than the state-of-the-art multi-modal SOD methods. Extensive quantitative and qualitative experiments illustrate both the effectiveness and efficiency of our CMA-Net, inspiring future development of multi-modal learning for both the RGB-D and light field SOD.