 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sub-pixel Motion Compensation in Learned Video Codecs
Jul 29, 2025Motion compensation is a key component of video codecs. Conventional codecs (HEVC and VVC) have carefully refined this coding step, with an important focus on sub-pixel motion compensation. On the other hand, learned codecs achieve sub-pixel motion compensation through simple bilinear filtering. This paper offers to improve learned codec motion compensation by drawing inspiration from conventional codecs. It is shown that the usage of more advanced interpolation filters, block-based motion information and finite motion accuracy lead to better compression performance and lower decoding complexity. Experimental results are provided on the Cool-chic video codec, where we demonstrate a rate decrease of more than 10% and a lowering of motion-related decoding complexity from 391 MAC per pixel to 214 MAC per pixel. All contributions are made open-source at https://github.com/Orange-OpenSource/Cool-Chic
BOGausS: Better Optimized Gaussian Splatting
Apr 02, 2025
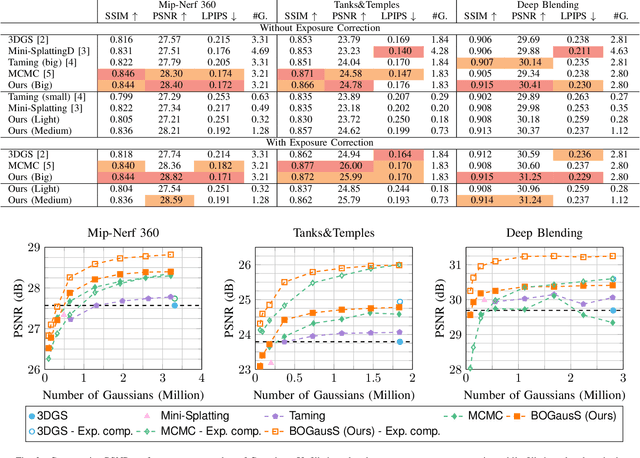
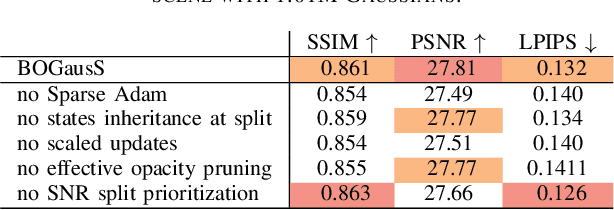
3D Gaussian Splatting (3DGS) proposes an efficient solution for novel view synthesis. Its framework provides fast and high-fidelity rendering. Although less complex than other solutions such as Neural Radiance Fields (NeRF), there are still some challenges building smaller models without sacrificing quality. In this study, we perform a careful analysis of 3DGS training process and propose a new optimization methodology. Our Better Optimized Gaussian Splatting (BOGausS) solution is able to generate models up to ten times lighter than the original 3DGS with no quality degradation, thus significantly boosting the performance of Gaussian Splatting compared to the state of the art.
Improved Encoding for Overfitted Video Codecs
Jan 28, 2025Overfitted neural video codecs offer a decoding complexity orders of magnitude smaller than their autoencoder counterparts. Yet, this low complexity comes at the cost of limited compression efficiency, in part due to their difficulty capturing accurate motion information. This paper proposes to guide motion information learning with an optical flow estimator. A joint rate-distortion optimization is also introduced to improve rate distribution across the different frames. These contributions maintain a low decoding complexity of 1300 multiplications per pixel while offering compression performance close to the conventional codec HEVC and outperforming other overfitted codecs. This work is made open-source at https://orange-opensource. github.io/Cool-Chic/
Upsampling Improvement for Overfitted Neural Coding
Nov 28, 2024Neural image compression, based on auto-encoders and overfitted representations, relies on a latent representation of the coded signal. This representation needs to be compact and uses low resolution feature maps. In the decoding process, those latents are upsampled and filtered using stacks of convolution filters and non linear elements to recover the decoded image. Therefore, the upsampling process is crucial in the design of a neural coding scheme and is of particular importance for overfitted codecs where the network parameters, including the upsampling filters, are part of the representation. This paper addresses the improvement of the upsampling process in order to reduce its complexity and limit the number of parameters. A new upsampling structure is presented whose improvements are illustrated within the Cool-Chic overfitted image coding framework. The proposed approach offers a rate reduction of 4.7%. The code is provided.
Overfitted image coding at reduced complexity
Mar 18, 2024Overfitted image codecs offer compelling compression performance and low decoder complexity, through the overfitting of a lightweight decoder for each image. Such codecs include Cool-chic, which presents image coding performance on par with VVC while requiring around 2000 multiplications per decoded pixel. This paper proposes to decrease Cool-chic encoding and decoding complexity. The encoding complexity is reduced by shortening Cool-chic training, up to the point where no overfitting is performed at all. It is also shown that a tiny neural decoder with 300 multiplications per pixel still outperforms HEVC. A near real-time CPU implementation of this decoder is made available at https://orange-opensource.github.io/Cool-Chic/.
Cool-chic video: Learned video coding with 800 parameters
Feb 06, 2024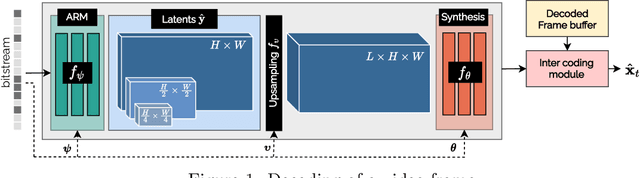

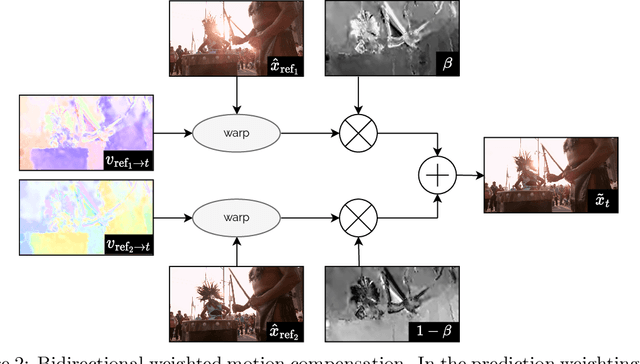
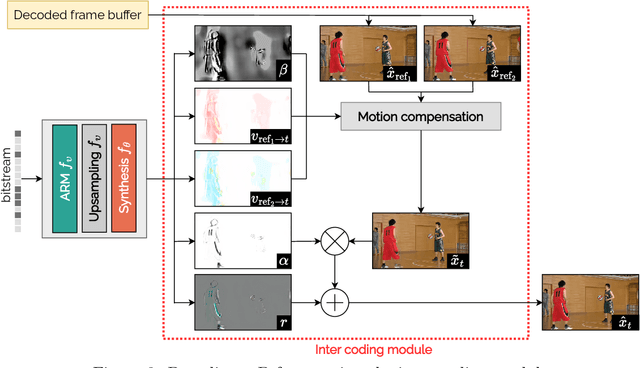
We propose a lightweight learned video codec with 900 multiplications per decoded pixel and 800 parameters overall. To the best of our knowledge, this is one of the neural video codecs with the lowest decoding complexity. It is built upon the overfitted image codec Cool-chic and supplements it with an inter coding module to leverage the video's temporal redundancies. The proposed model is able to compress videos using both low-delay and random access configurations and achieves rate-distortion close to AVC while out-performing other overfitted codecs such as FFNeRV. The system is made open-source: orange-opensource.github.io/Cool-Chic.
Cool-Chic: Perceptually Tuned Low Complexity Overfitted Image Coder
Jan 04, 2024



This paper summarises the design of the Cool-Chic candidate for the Challenge on Learned Image Compression. This candidate attempts to demonstrate that neural coding methods can lead to low complexity and lightweight image decoders while still offering competitive performance. The approach is based on the already published overfitted lightweight neural networks Cool-Chic, further adapted to the human subjective viewing targeted in this challenge.
ED: Perceptually tuned Enhanced Compression Model
Jan 04, 2024
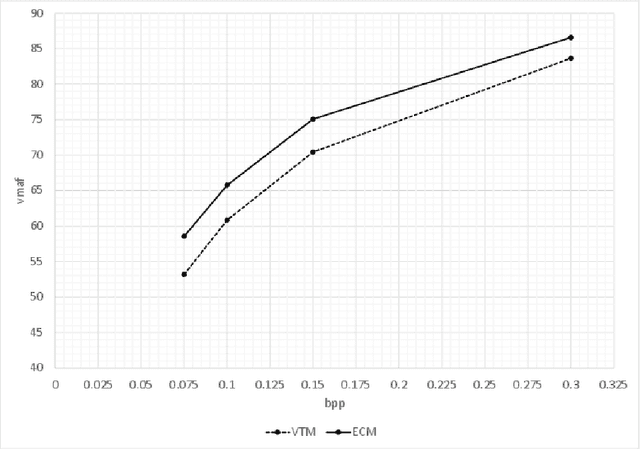

This paper summarises the design of the candidate ED for the Challenge on Learned Image Compression 2024. This candidate aims at providing an anchor based on conventional coding technologies to the learning-based approaches mostly targeted in the challenge. The proposed candidate is based on the Enhanced Compression Model (ECM) developed at JVET, the Joint Video Experts Team of ITU-T VCEG and ISO/IEC MPEG. Here, ECM is adapted to the challenge objective: to maximise the perceived quality, the encoding is performed according to a perceptual metric, also the sequence selection is performed in a perceptual manner to fit the target bit per pixel objectives. The primary objective of this candidate is to assess the recent developments in video coding standardisation and in parallel to evaluate the progress made by learning-based techniques. To this end, this paper explains how to generate coded images fulfilling the challenge requirements, in a reproducible way, targeting the maximum performance.
CAwa-NeRF: Instant Learning of Compression-Aware NeRF Features
Oct 23, 2023



Modeling 3D scenes by volumetric feature grids is one of the promising directions of neural approximations to improve Neural Radiance Fields (NeRF). Instant-NGP (INGP) introduced multi-resolution hash encoding from a lookup table of trainable feature grids which enabled learning high-quality neural graphics primitives in a matter of seconds. However, this improvement came at the cost of higher storage size. In this paper, we address this challenge by introducing instant learning of compression-aware NeRF features (CAwa-NeRF), that allows exporting the zip compressed feature grids at the end of the model training with a negligible extra time overhead without changing neither the storage architecture nor the parameters used in the original INGP paper. Nonetheless, the proposed method is not limited to INGP but could also be adapted to any model. By means of extensive simulations, our proposed instant learning pipeline can achieve impressive results on different kinds of static scenes such as single object masked background scenes and real-life scenes captured in our studio. In particular, for single object masked background scenes CAwa-NeRF compresses the feature grids down to 6% (1.2 MB) of the original size without any loss in the PSNR (33 dB) or down to 2.4% (0.53 MB) with a slight virtual loss (32.31 dB).
Low-complexity Overfitted Neural Image Codec
Jul 24, 2023



We propose a neural image codec at reduced complexity which overfits the decoder parameters to each input image. While autoencoders perform up to a million multiplications per decoded pixel, the proposed approach only requires 2300 multiplications per pixel. Albeit low-complexity, the method rivals autoencoder performance and surpasses HEVC performance under various coding conditions. Additional lightweight modules and an improved training process provide a 14% rate reduction with respect to previous overfitted codecs, while offering a similar complexity. This work is made open-source at https://orange-opensource.github.io/Cool-Chic/