 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOGausS: Better Optimized Gaussian Splatting
Apr 02, 2025
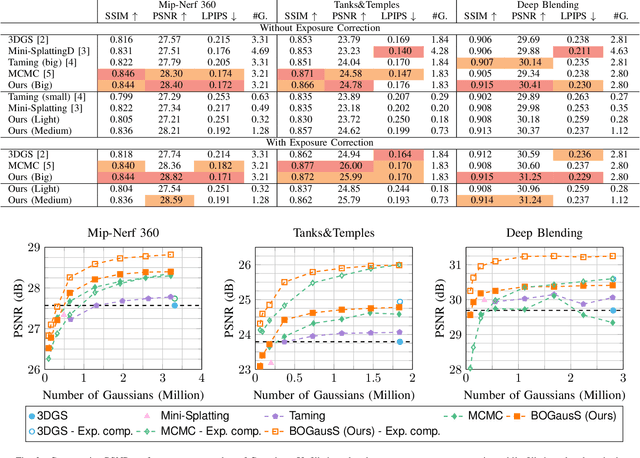
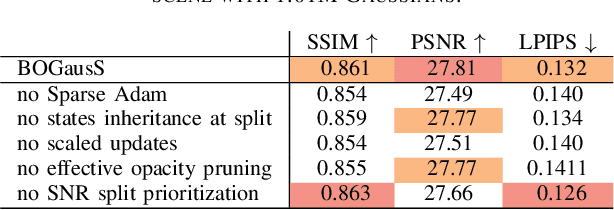
3D Gaussian Splatting (3DGS) proposes an efficient solution for novel view synthesis. Its framework provides fast and high-fidelity rendering. Although less complex than other solutions such as Neural Radiance Fields (NeRF), there are still some challenges building smaller models without sacrificing quality. In this study, we perform a careful analysis of 3DGS training process and propose a new optimization methodology. Our Better Optimized Gaussian Splatting (BOGausS) solution is able to generate models up to ten times lighter than the original 3DGS with no quality degradation, thus significantly boosting the performance of Gaussian Splatting compared to the state of the art.
NERV++: An Enhanced Implicit Neural Video Representation
Feb 28, 2024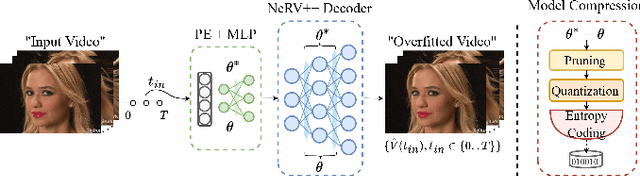
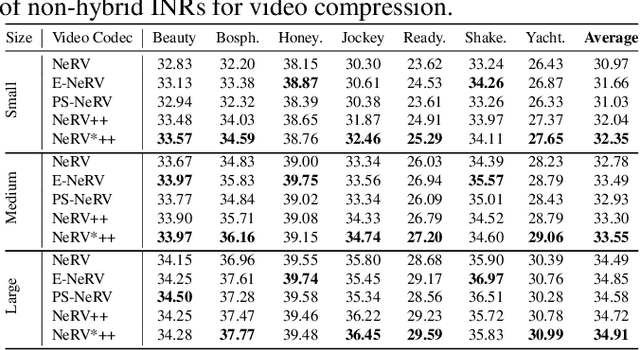
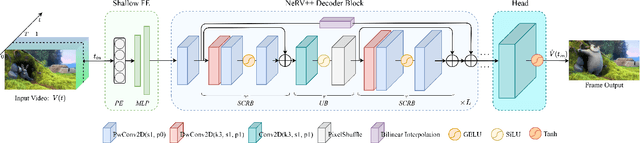
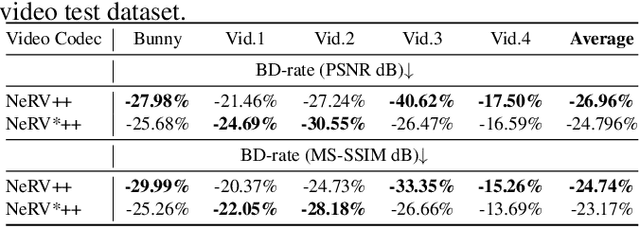
Neural fields, also known as implicit neural representations (INRs), have shown a remarkable capability of representing, generating, and manipulating various data types, allowing for continuous data reconstruction at a low memory footprint. Though promising, INRs applied to video compression still need to improve their rate-distortion performance by a large margin, and require a huge number of parameters and long training iterations to capture high-frequency details, limiting their wider applicability. Resolving this problem remains a quite challenging task, which would make INRs more accessible in compression tasks. We take a step towards resolving these shortcomings by introducing neural representations for videos NeRV++, an enhanced implicit neural video representation, as more straightforward yet effective enhancement over the original NeRV decoder architecture, featuring separable conv2d residual blocks (SCRBs) that sandwiches the upsampling block (UB), and a bilinear interpolation skip layer for improved feature representation. NeRV++ allows videos to be directly represented as a function approximated by a neural network, and significantly enhance the representation capacity beyond current INR-based video codecs. We evaluate our method on UVG, MCL JVC, and Bunny datasets, achieving competitive results for video compression with INRs. This achievement narrows the gap to autoencoder-based video coding, marking a significant stride in INR-based video compression research.
Bitrate Ladder Prediction Methods for Adaptive Video Streaming: A Review and Benchmark
Oct 30, 2023HTTP adaptive streaming (HAS) has emerged as a widely adopted approach for over-the-top (OTT) video streaming services, due to its ability to deliver a seamless streaming experience. A key component of HAS is the bitrate ladder, which provides the encoding parameters (e.g., bitrate-resolution pairs) to encode the source video. The representations in the bitrate ladder allow the client's player to dynamically adjust the quality of the video stream based on network conditions by selecting the most appropriate representation from the bitrate ladder. The most straightforward and lowest complexity approach involves using a fixed bitrate ladder for all videos, consisting of pre-determined bitrate-resolution pairs known as one-size-fits-all. Conversely, the most reliable technique relies on intensively encoding all resolutions over a wide range of bitrates to build the convex hull, thereby optimizing the bitrate ladder for each specific video. Several techniques have been proposed to predict content-based ladders without performing a costly exhaustive search encoding. This paper provides a comprehensive review of various methods, including both conventional and learning-based approaches. Furthermore, we conduct a benchmark study focusing exclusively on various learning-based approaches for predicting content-optimized bitrate ladders across multiple codec settings. The considered methods are evaluated on our proposed large-scale dataset, which includes 300 UHD video shots encoded with software and hardware encoders using three state-of-the-art encoders, including AVC/H.264, HEVC/H.265, and VVC/H.266, at various bitrate points. Our analysis provides baseline methods and insights, which will be valuable for future research in the field of bitrate ladder prediction. The source code of the proposed benchmark and the dataset will be made publicly available upon acceptance of the paper.
AICT: An Adaptive Image Compression Transformer
Jul 12, 2023



Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Current methods that still rely on ConvNet-based entropy coding are limited in long-range modeling dependencies due to their local connectivity and an increasing number of architectural biases and priors. On the contrary, the proposed ICT can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre/post-processor to accurately extract more compact latent representation while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed adaptive image compression transformer (AICT) framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM.
Joint Hierarchical Priors and Adaptive Spatial Resolution for Efficient Neural Image Compression
Jul 12, 2023Recently, the performance of neural image compression (NIC) has steadily improved thanks to the last line of study, reaching or outperforming state-of-the-art conventional codecs. Despite significant progress, current NIC methods still rely on ConvNet-based entropy coding, limited in modeling long-range dependencies due to their local connectivity and the increasing number of architectural biases and priors, resulting in complex underperforming models with high decoding latency. Motivated by the efficiency investigation of the Tranformer-based transform coding framework, namely SwinT-ChARM, we propose to enhance the latter, as first, with a more straightforward yet effective Tranformer-based channel-wise auto-regressive prior model, resulting in an absolute image compression transformer (ICT). Through the proposed ICT, we can capture both global and local contexts from the latent representations and better parameterize the distribution of the quantized latents. Further, we leverage a learnable scaling module with a sandwich ConvNeXt-based pre-/post-processor to accurately extract more compact latent codes while reconstructing higher-quality images. Extensive experimental results on benchmark datasets showed that the proposed framework significantly improves the trade-off between coding efficiency and decoder complexity over the versatile video coding (VVC) reference encoder (VTM-18.0) and the neural codec SwinT-ChARM. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the adaptive image compression transformer (AICT) and the neural codec SwinT-ChARM.
ConvNeXt-ChARM: ConvNeXt-based Transform for Efficient Neural Image Compression
Jul 12, 2023Over the last few years, neural image compression has gained wide attention from research and industry, yielding promising end-to-end deep neural codecs outperforming their conventional counterparts in rate-distortion performance. Despite significant advancement, current methods, including attention-based transform coding, still need to be improved in reducing the coding rate while preserving the reconstruction fidelity, especially in non-homogeneous textured image areas. Those models also require more parameters and a higher decoding time. To tackle the above challenges, we propose ConvNeXt-ChARM, an efficient ConvNeXt-based transform coding framework, paired with a compute-efficient channel-wise auto-regressive prior to capturing both global and local contexts from the hyper and quantized latent representations. The proposed architecture can be optimized end-to-end to fully exploit the context information and extract compact latent representation while reconstructing higher-quality images. Experimental results on four widely-used datasets showed that ConvNeXt-ChARM brings consistent and significant BD-rate (PSNR) reductions estimated on average to 5.24% and 1.22% over the versatile video coding (VVC) reference encoder (VTM-18.0) and the state-of-the-art learned image compression method SwinT-ChARM, respectively. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the next generation ConvNet, namely ConvNeXt, and Swin Transformer.
Ensemble Learning for Efficient VVC Bitrate Ladder Prediction
Jul 23, 2022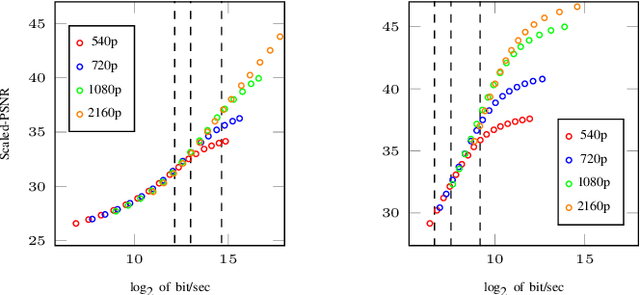
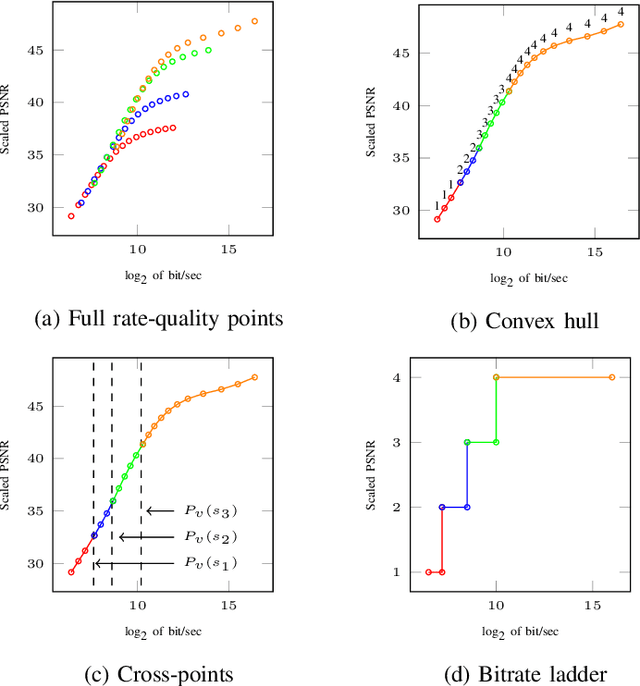
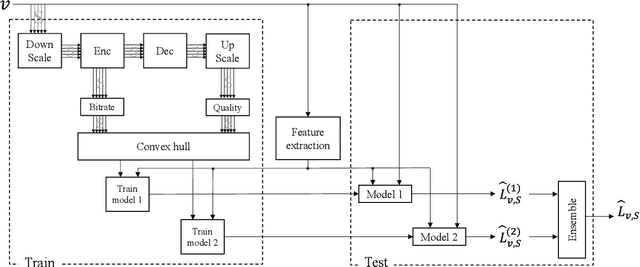
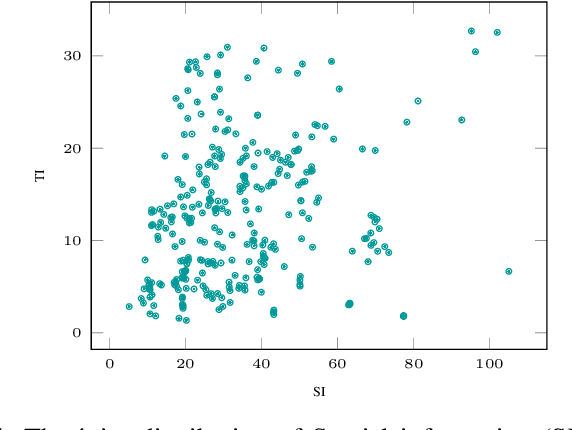
Changing the encoding parameters, in particular the video resolution, is a common practice before transcoding. To this end, streaming and broadcast platforms benefit from so-called bitrate ladders to determine the optimal resolution for given bitrates. However, the task of determining the bitrate ladder can usually be challenging as, on one hand, so-called fit-for-all static ladders would waste bandwidth, and on the other hand, fully specialized ladders are often not affordable in terms of computational complexity. In this paper, we propose an ML-based scheme for predicting the bitrate ladder based on the content of the video. The baseline of our solution predicts the bitrate ladder using two constituent methods, which require no encoding passes. To further enhance the performance of the constituent methods, we integrate a conditional ensemble method to aggregate their decisions, with a negligibly limited number of encoding passes. The experiment, carried out on the optimized software encoder implementation of the VVC standard, called VVenC, shows significant performance improvement. When compared to static bitrate ladder, the proposed method can offer about 13% bitrate reduction in terms of BD-BR with a negligible additional computational overhead. Conversely, when compared to the fully specialized bitrate ladder method, the proposed method can offer about 86% to 92% complexity reduction, at cost the of only 0.8% to 0.9% coding efficiency drop in terms of BD-BR.
Prediction-Aware Quality Enhancement of VVC Using CNN
Dec 08, 2021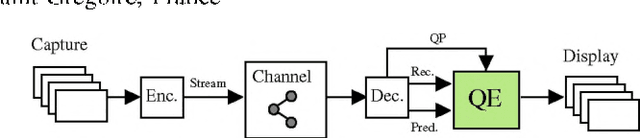

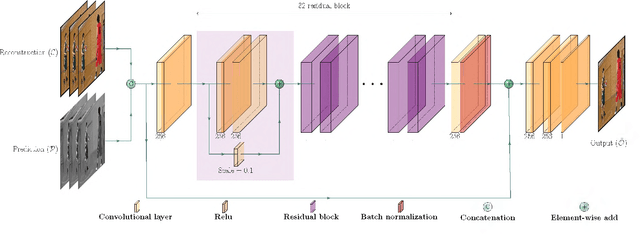

The upcoming video coding standard, Versatile Video Coding (VVC), has shown great improvement compared to its predecessor, High Efficiency Video Coding (HEVC), in terms of bitrate saving. Despite its substantial performance, compressed videos might still suffer from quality degradation at low bitrates due to coding artifacts such as blockiness, blurriness and ringing. In this work, we exploit Convolutional Neural Networks (CNN) to enhance quality of VVC coded frames after decoding in order to reduce low bitrate artifacts. The main contribution of this work is the use of coding information from the compressed bitstream. More precisely, the prediction information of intra frames is used for training the network in addition to the reconstruction information. The proposed method is applied on both luminance and chrominance components of intra coded frames of VVC. Experiments on VVC Test Model (VTM) show that, both in low and high bitrates, the use of coding information can improve the BD-rate performance by about 1% and 6% for luma and chroma components, respectively.
A CNN-based Prediction-Aware Quality Enhancement Framework for VVC
May 12, 2021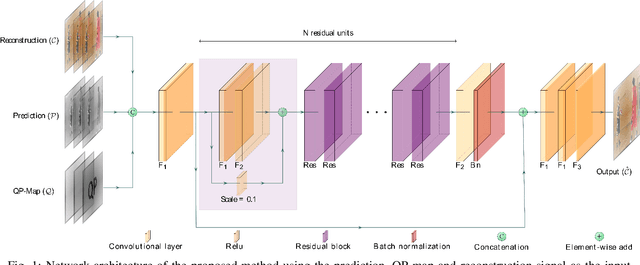
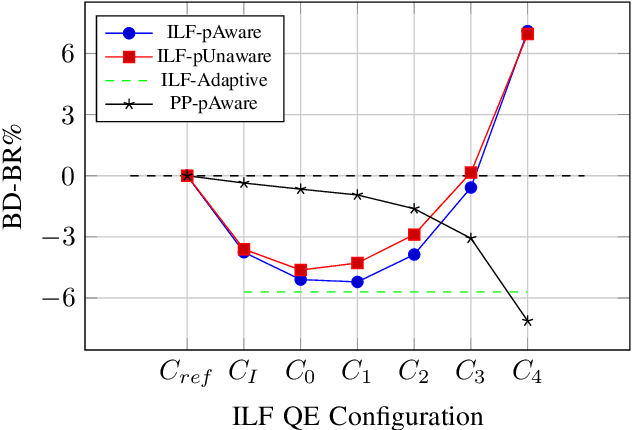
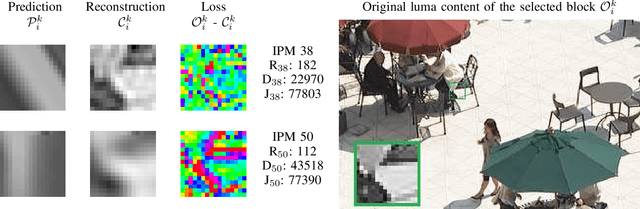
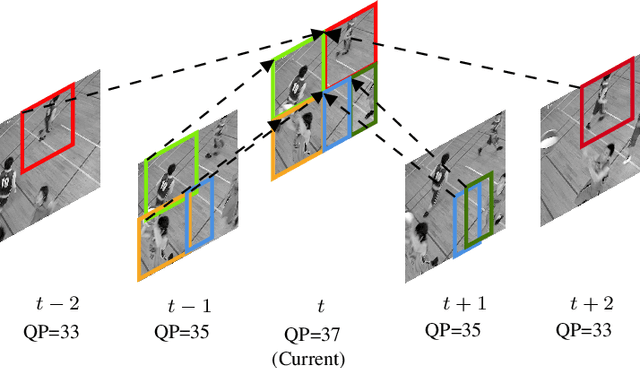
This paper presents a framework for Convolutional Neural Network (CNN)-based quality enhancement task, by taking advantage of coding information in the compressed video signal. The motivation is that normative decisions made by the encoder can significantly impact the type and strength of artifacts in the decoded images. In this paper, the main focus has been put on decisions defining the prediction signal in intra and inter frames. This information has been used in the training phase as well as input to help the process of learning artifacts that are specific to each coding type. Furthermore, to retain a low memory requirement for the proposed method, one model is used for all Quantization Parameters (QPs) with a QP-map, which is also shared between luma and chroma components. In addition to the Post Processing (PP) approach, the In-Loop Filtering (ILF) codec integration has also been considered, where the characteristics of the Group of Pictures (GoP) are taken into account to boost the performance. The proposed CNN-based Quality Enhancement(QE) framework has been implemented on top of the VVC Test Model (VTM-10). Experiments show that the prediction-aware aspect of the proposed method improves the coding efficiency gain of the default CNN-based QE method by 1.52%, in terms of BD-BR, at the same network complexity compared to the default CNN-based QE filter.
Model Selection CNN-based VVC QualityEnhancement
May 07, 2021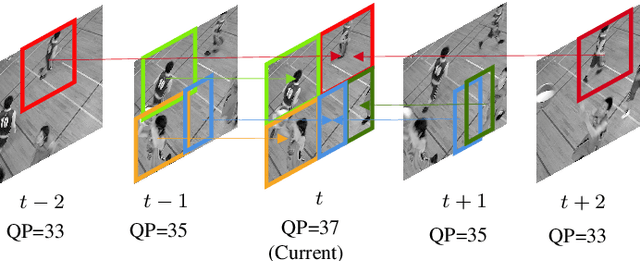
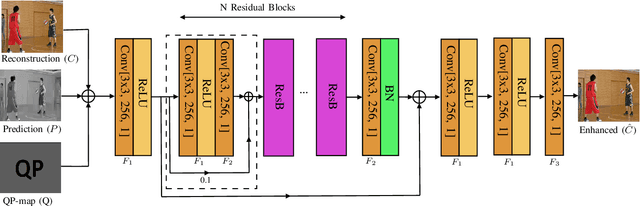

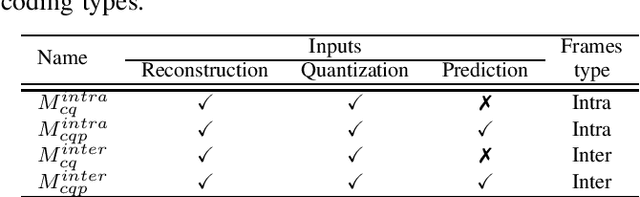
Artifact removal and filtering methods are inevitable parts of video coding. On one hand, new codecs and compression standards come with advanced in-loop filters and on the other hand, displays are equipped with high capacity processing units for post-treatment of decoded videos. This paper proposes a Convolutional Neural Network (CNN)-based post-processing algorithm for intra and inter frames of Versatile Video Coding (VVC) coded streams. Depending on the frame type, this method benefits from normative prediction signal by feeding it as an additional input along with reconstructed signal and a Quantization Parameter (QP)-map to the CNN. Moreover, an optional Model Selection (MS) strategy is adopted to pick the best trained model among available ones at the encoder side and signal it to the decoder side. This MS strategy is applicable at both frame level and block level. The experiments under the Random Access (RA) configuration of the VVC Test Model (VTM-10.0) show that the proposed prediction-aware algorithm can bring an additional BD-BR gain of -1.3% compared to the method without the prediction information. Furthermore, the proposed MS scheme brings -0.5% more BD-BR gain on top of the prediction-aware method.