 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQ-Ladder: A Deep Reinforcement Learning-based Bitrate Ladder for Adaptive Video Streaming
Mar 13, 2026Adaptive streaming of segmented video over HTTP typically relies on a predefined set of bitrate-resolution pairs, known as a bitrate ladder. However, fixed ladders often overlook variations in content and decoding complexities, leading to suboptimal trade-offs between encoding time, decoding efficiency, and video quality. This article introduces DQ-Ladder, a deep reinforcement learning (DRL)-based scheme for constructing time- and quality-aware bitrate ladders for adaptive video streaming applications. DQ-Ladder employs predicted decoding time, quality scores, and bitrate levels per segment as inputs to a Deep Q-Network (DQN) agent, guided by a weighted reward function of decoding time, video quality, and resolution smoothness. We leverage machine learning models to predict decoding time, bitrate level, and objective quality metrics (VMAF, XPSNR), eliminating the need for exhaustive encoding or quality metric computation. We evaluate DQ-Ladder using the Versatile Video Coding (VVC) toolchain (VVenC/VVdeC) on 750 video sequences across six Apple HLS-compliant resolutions and 41 quantization parameters. Experimental results against four baselines show that DQ-Ladder achieves BD-rate reductions of at least 10.3% for XPSNR compared to the HLS ladder, while reducing decoding time by 22%. DQ-Ladder shows significantly lower sensitivity to prediction errors than competing methods, remaining robust even with up to 20% noise.
End-to-End Learning-based Video Streaming Enhancement Pipeline: A Generative AI Approach
Dec 16, 2025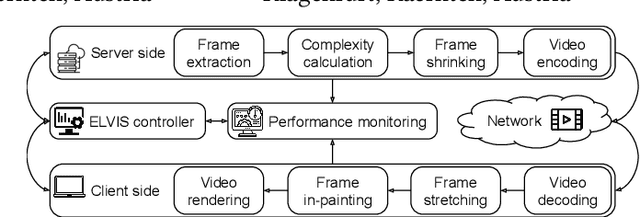



The primary challenge of video streaming is to balance high video quality with smooth playback. Traditional codecs are well tuned for this trade-off, yet their inability to use context means they must encode the entire video data and transmit it to the client. This paper introduces ELVIS (End-to-end Learning-based VIdeo Streaming Enhancement Pipeline), an end-to-end architecture that combines server-side encoding optimizations with client-side generative in-painting to remove and reconstruct redundant video data. Its modular design allows ELVIS to integrate different codecs, inpainting models, and quality metrics, making it adaptable to future innovations. Our results show that current technologies achieve improvements of up to 11 VMAF points over baseline benchmarks, though challenges remain for real-time applications due to computational demands. ELVIS represents a foundational step toward incorporating generative AI into video streaming pipelines, enabling higher quality experiences without increased bandwidth requirements.
EPS: Efficient Patch Sampling for Video Overfitting in Deep Super-Resolution Model Training
Nov 25, 2024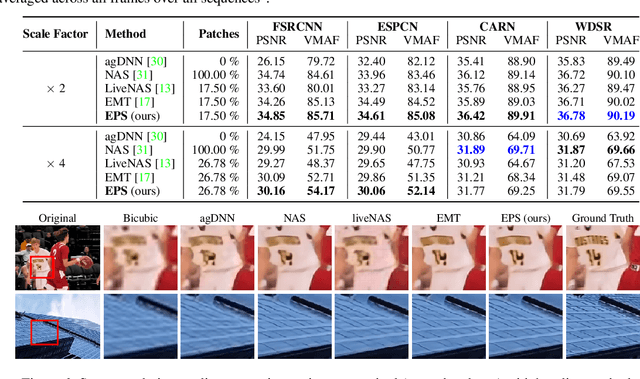
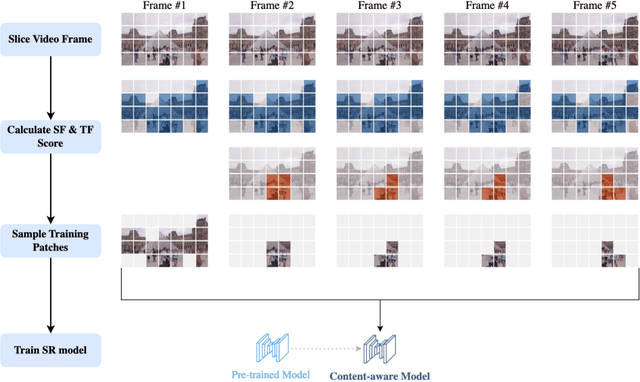

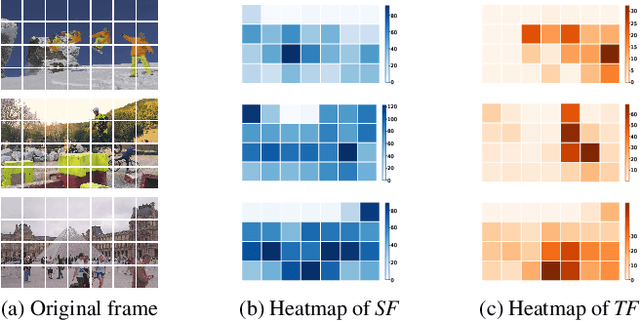
Leveraging the overfitting property of deep neural networks (DNNs) is trending in video delivery systems to enhance quality within bandwidth limits. Existing approaches transmit overfitted super-resolution (SR) model streams for low-resolution (LR) bitstreams, which are used to reconstruct high-resolution (HR) videos at the decoder. Although these approaches show promising results, the huge computational costs of training a large number of video frames limit their practical applications. To overcome this challenge, we propose an efficient patch sampling method named EPS for video SR network overfitting, which identifies the most valuable training patches from video frames. To this end, we first present two low-complexity Discrete Cosine Transform (DCT)-based spatial-temporal features to measure the complexity score of each patch directly. By analyzing the histogram distribution of these features, we then categorize all possible patches into different clusters and select training patches from the cluster with the highest spatial-temporal information. The number of sampled patches is adaptive based on the video content, addressing the trade-off between training complexity and efficiency. Our method reduces the number of patches for the training to 4% to 25%, depending on the resolution and number of clusters, while maintaining high video quality and significantly enhancing training efficiency. Compared to the state-of-the-art patch sampling method, EMT, our approach achieves an 83% decrease in overall run time.
360-Degree Video Super Resolution and Quality Enhancement Challenge: Methods and Results
Nov 11, 2024Omnidirectional (360-degree) video is rapidly gaining popularity due to advancements in immersive technologies like virtual reality (VR) and extended reality (XR). However, real-time streaming of such videos, especially in live mobile scenarios like unmanned aerial vehicles (UAVs), is challenged by limited bandwidth and strict latency constraints. Traditional methods, such as compression and adaptive resolution, help but often compromise video quality and introduce artifacts that degrade the viewer experience. Additionally, the unique spherical geometry of 360-degree video presents challenges not encountered in traditional 2D video. To address these issues, we initiated the 360-degree Video Super Resolution and Quality Enhancement Challenge. This competition encourages participants to develop efficient machine learning solutions to enhance the quality of low-bitrate compressed 360-degree videos, with two tracks focusing on 2x and 4x super-resolution (SR). In this paper, we outline the challenge framework, detailing the two competition tracks and highlighting the SR solutions proposed by the top-performing models. We assess these models within a unified framework, considering quality enhancement, bitrate gain, and computational efficiency. This challenge aims to drive innovation in real-time 360-degree video streaming, improving the quality and accessibility of immersive visual experiences.
Bitrate Ladder Prediction Methods for Adaptive Video Streaming: A Review and Benchmark
Oct 30, 2023HTTP adaptive streaming (HAS) has emerged as a widely adopted approach for over-the-top (OTT) video streaming services, due to its ability to deliver a seamless streaming experience. A key component of HAS is the bitrate ladder, which provides the encoding parameters (e.g., bitrate-resolution pairs) to encode the source video. The representations in the bitrate ladder allow the client's player to dynamically adjust the quality of the video stream based on network conditions by selecting the most appropriate representation from the bitrate ladder. The most straightforward and lowest complexity approach involves using a fixed bitrate ladder for all videos, consisting of pre-determined bitrate-resolution pairs known as one-size-fits-all. Conversely, the most reliable technique relies on intensively encoding all resolutions over a wide range of bitrates to build the convex hull, thereby optimizing the bitrate ladder for each specific video. Several techniques have been proposed to predict content-based ladders without performing a costly exhaustive search encoding. This paper provides a comprehensive review of various methods, including both conventional and learning-based approaches. Furthermore, we conduct a benchmark study focusing exclusively on various learning-based approaches for predicting content-optimized bitrate ladders across multiple codec settings. The considered methods are evaluated on our proposed large-scale dataset, which includes 300 UHD video shots encoded with software and hardware encoders using three state-of-the-art encoders, including AVC/H.264, HEVC/H.265, and VVC/H.266, at various bitrate points. Our analysis provides baseline methods and insights, which will be valuable for future research in the field of bitrate ladder prediction. The source code of the proposed benchmark and the dataset will be made publicly available upon acceptance of the paper.
MoViDNN: A Mobile Platform for Evaluating Video Quality Enhancement with Deep Neural Networks
Jan 12, 2022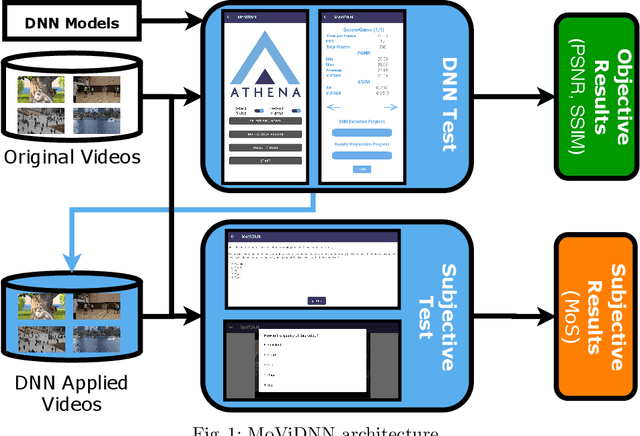


Deep neural network (DNN) based approaches have been intensively studied to improve video quality thanks to their fast advancement in recent years. These approaches are designed mainly for desktop devices due to their high computational cost. However, with the increasing performance of mobile devices in recent years, it became possible to execute DNN based approaches in mobile devices. Despite having the required computational power, utilizing DNNs to improve the video quality for mobile devices is still an active research area. In this paper, we propose an open-source mobile platform, namely MoViDNN, to evaluate DNN based video quality enhancement methods, such as super-resolution, denoising, and deblocking. Our proposed platform can be used to evaluate the DNN based approaches both objectively and subjectively. For objective evaluation, we report common metrics such as execution time, PSNR, and SSIM. For subjective evaluation, Mean Score Opinion (MOS) is reported. The proposed platform is available publicly at https://github.com/cd-athena/MoViDNN